概要
Python在处理大的数据集的时候总是速度感人。代码一旦开始运行,剩下的时间只好满心愧疚地刷手机。
MPI(Message Passing Interface)是在并行计算中,在不同进程间传递信息的标准解决方案。mpi4py是它的python版本。
网上有大量教程讲怎么通过mpi4py实现同步运行相对独立的python代码。在服务器上跑代码的时候尤其有用。
在正式开始之前,有两个基本概念需要理解:
node,翻译一般作服务器节点。我的理解,一个node,可以看作是一台个人电脑。每个node(每台电脑)可以有多个core(核)。比如你可能听过,一个程序在12个nodes上运行,每个nodes运行128个任务。就是说,这个程序同步运行在个cores上。可能一个core还可以有多个CPU.
比如下面展示的简单示例中,一共有12个并行任务。我们让它在2个nodes上运行,所以每个nodes需要运行6个任务。同时我们指定每个node只调用4个cores(因为所有的cores平分memory,如果一次性调用所有的cores,每个core能用的memory可能不够单个任务所需)。这样的话,6个任务分配到4个核,有些核需要跑两遍,比如[2,2,1,1]。参考下图。
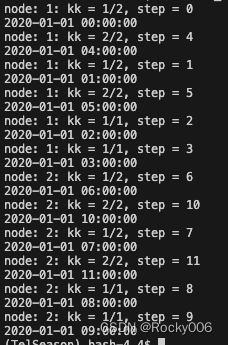
要让python代码通过mpi4py并行,实际上需要改动的地方并不多。基本的逻辑是,从系统中拿到所有node和所有core的index,这样就得到可以同步运算的所有“通道”的index,然后根据“通道”总数量,将需要运行的任务分成多个组,最后将不同的组分配到不同的“通道”上单独运行即可。
1. 修改python代码以支持mpi4py
假设你想要并行运算的python代码叫“python_mpi4py.py“,这个代码是一个可以独立在一台电脑上(一个node)上执行的代码。下面的解释只为增加理解(可以略过),实际上代码读懂了改的地方不多。
-
参数
num指定这个python的主体代码运行在哪个node上。实际上只用于输出信息之用。 -
参数
t1和t2指定,在所有的任务中,当前的node上(node index 为num)运行第t1-t2步。我们总共有12步 (代码中periods=12)的任务,且我们指定两个node运行这12步任务,所以当前node只跑所有任务中的一部分(第t1-t2步)。因为调用2个nodes,python_mpi4py.py会被运行2次,每次接受不同的t1和t2,两步加起来就运行了所有的t。 -
rank和size是mpi4py中很重要的概念。现在我们回到单个node,这里的rank可以看作是这个node中所有core的index。比如,我们指定调用4个cores,那rank的值就是一个listrank=[0,1,2,3]。size(代码中写作npro)是获得的cores的总数,这里size=4。这里的解释肯定是过度简单化了。但大概这样。 -
然后就是前面提到的分组。尽管这个node得到的已经是一个sub- group(只有
steps_global[t1:t2])。这个sub- group还需要进一步分给不同的cores(代码中的list_all_pros). -
然后各个core会同时进行,但是,我们在每个核上有不止一个任务([2,2,1,1]),所以要进行唯一的循环。
#%%
import sys
import numpy as np
import mpi4py
import time as pytime
import pandas as pd
# get the number of the node, and the range of the steps [t1:t2] that runs on this node
num = int(sys.argv[1])
t1 = int(sys.argv[2])
t2 = int(sys.argv[3])
# example of all the steps that need to be run on all the nodes
time = pd.date_range('2020-01-01', periods=12, freq='H')
# the steps that need to be run on this node
steps_global = np.arange(time.size)
steps = steps_global[t1:t2] # sub-group for this node
# === mpi4py ===
try:
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
npro = comm.Get_size()
except:
print('::: Warning: Proceeding without mpi4py! :::')
rank = 0
npro = 1
list_all_pros = [0]*npro # sub-sub-groups for all the cores
for nn in range(npro):
list_all_pros[nn] = steps[nn::npro]
steps = list_all_pros[rank]
pytime.sleep(0.1*rank) # to make sure the print statements are in order
# use mpi4py here
for kk, step in enumerate(steps):
print(f'node: {num}: kk = {kk+1}/{steps.size}, step = {step}')
print(f'{time[step]}')
上面的代码,我们把原本要进行的12步循环,最后压缩到了最大2步循环。当然,这个想象空间还是很大的。
2. 在单个node上运行python代码
要运行上面的包含mpi4py的代码,最简单的可以一句bash命令就可以:
mpirun -np 4 python -u python_mpi4py.py $1 $2 $3
上面命令-np 4指定4个核同时运行。然后$1指定node的index,$2和$3分别指定在这个node上面运行的步骤的index。
当然服务器上,一般要先allocate 资源,然后写一个脚本(命名为submit_python_mpi4py.sh)提交后台运行代码:
#!/bin/bash
#SBATCH --job-name=parallel
#SBATCH --time=00:01:00
#SBATCH --partition=compute
#SBATCH --nodes=1
#SBATCH --ntasks=4
#SBATCH --account=*****
mpirun -np 4 python -u python_mpi4py.py $1 $2 $3
3. 在多个node上运行python代码
为了好理解,这里通过一个python代码多次提交上面的bash代码,即申请多个node。这样做可以更加直接得控制哪些任务运行在哪个node上。比如,让不同的模型在不同的nodes上运行。这个python文件我们命名为master_submitter.py
#!/usr/bin/env python
#%%
import os
import numpy as np
#%%
nsteps = 12
npar = 6
njobs = int(nsteps/npar) # 2 nodes
#%%
for kk in range(njobs): #0,1 node-index
k1 = kk*npar #0,6 the starting task-index for node1 and node2
k2 = (kk+1)*npar #6,12 the ending task-index for node1 and node2
print("-----node line -----")
os.system(f"sbatch ./submit_python_mpi4py.sh {kk+1} {k1} {k2}") #
# %%
上面的示例简单展示了一种可以利用mpi4py在多个nodes,多个cores上并行运算的例子。上面的例子中,各个任务之间是完全没有依赖的。但是我们的for循环结束了之后一般比如会有个concat操作之类的,需要将各个cores运行的结果收集起来。mpi4py也支持在不同的任务之间传输数据。更多信息网上找啦。
今天的分享就到这,欢迎点赞收藏转发,感谢🙏

![[openCV]基于拟合中线的智能车巡线方案V3](https://img-blog.csdnimg.cn/6d6e0e96c2dc49d2b5af82306de736db.png)