进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容!
🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,Kerberos安全认证,大数据OLAP体系技术栈-CSDN博客
📌订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
👍点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!
目录
1. Memory
2. Merge
3. Distributed
1. Memory
Memory表引擎直接将数据保存在内存中,ClickHouse中的Memory表引擎具有以下特点:
- Memory 引擎以未压缩的形式将数据存储在 RAM 中,数据完全以读取时获得的形式存储。
- 并发数据访问是同步的,锁范围小,读写操作不会相互阻塞。
- 不支持索引。
- 查询是并行化的,在简单查询上达到最大速率(超过10 GB /秒),在相对较少的行(最多约100,000,000)上有高性能的查询。
- 没有磁盘读取,不需要解压缩或反序列化数据,速度更快(在许多情况下,与 MergeTree 引擎的性能几乎一样高)。
- 重新启动服务器时,表存在,但是表中数据全部清空。
- Memory引擎多用于测试。
- 示例:
#在 newdb中创建表 t_memory ,表引擎使用Memory
node1 :) create table t_memory(id UInt8 ,name String, age UInt8) engine = Memory;
CREATE TABLE t_memory
(
`id` UInt8,
`name` String,
`age` UInt8
)
ENGINE = Memory
Ok.
0 rows in set. Elapsed: 0.008 sec.
#向表 t_memory中插入数据
node1 :) insert into t_memory values (1,'张三',18),(2,'李四',19),(3,'王五',20);
INSERT INTO t_memory VALUES
Ok.
3 rows in set. Elapsed: 0.004 sec.
#查询表t_memory中的数据
node1 :) select * from t_memory;
SELECT *
FROM t_memory
┌─id─┬─name─┬─age─┐
│ 1 │ 张三 │ 18 │
│ 2 │ 李四 │ 19 │
│ 3 │ 王五 │ 20 │
└────┴──────┴─────┘
3 rows in set. Elapsed: 0.004 sec.
#重启clickhouse 服务
[root@node1 ~]# service clickhouse-server restart
Stop clickhouse-server service: DONE
Start clickhouse-server service: Path to data directory in /etc/clickhouse-server/config.xml: /var/lib/clickhouse/
DONE
#进入 newdb 库,查看表 t_memory数据,数据为空。
node1 :) select * from t_memory;
SELECT *
FROM t_memory
Ok.
0 rows in set. Elapsed: 0.003 sec.注意:”Memory”表引擎写法固定,不能小写。同时创建好表t_memory后,在对应的磁盘目录/var/lib/clickhouse/data/newdb下没有“t_memory”目录,基于内存存储,当重启ClickHouse服务后,表t_memory存在,但是表中数据全部清空。
2. Merge
Merge 引擎 (不要跟 MergeTree 引擎混淆) 本身不存储数据,但可用于同时从任意多个其他的表中读取数据,这里需要多个表的结构相同,并且创建的Merge引擎表的结构也需要和这些表结构相同才能读取。
读是自动并行的,不支持写入。读取时,那些被真正读取到数据的表如果设置了索引,索引也会被使用。
Merge 引擎的参数:一个数据库名和一个用于匹配表名的正则表达式:
Merge(数据库, 正则表达式)例如:Merge(hits, '^WatchLog') 表示数据会从 hits 数据库中表名匹配正则 ‘^WatchLog’ 的表中读取。
注意:当选择需要读取的表时,会匹配正则表达式匹配上的表,如果当前Merge表的名称也符合正则表达式匹配表名,这个Merge表本身会自动排除,以避免进入递归死循环,当然也可以创建两个相互无限递归读取对方数据的 Merge 表,但这并没有什么意义。
- 示例:
#在newdb库中创建表m_t1,并插入数据
node1 :) create table m_t1 (id UInt8 ,name String,age UInt8) engine = TinyLog;
node1 :) insert into m_t1 values (1,'张三',18),(2,'李四',19)
#在newdb库中创建表m_t2,并插入数据
node1 :) create table m_t2 (id UInt8 ,name String,age UInt8) engine = TinyLog;
node1 :) insert into m_t2 values (3,'王五',20),(4,'马六',21)
#在newdb库中创建表m_t3,并插入数据
node1 :) create table m_t3 (id UInt8 ,name String,age UInt8) engine = TinyLog;
node1 :) insert into m_t3 values (5,'田七',22),(6,'赵八',23)
#在newdb库中创建表t_merge,使用Merge引擎,匹配m开头的表
node1 :) create table t_merge (id UInt8,name String,age UInt8) engine = Merge(newdb,'^m');
#查询 t_merge表中的数据
node1 :) select * from t_merge;
SELECT *
FROM t_merge
┌─id─┬─name─┬─age─┐
│ 1 │ 张三 │ 18 │
│ 2 │ 李四 │ 19 │
└────┴─────┴────┘
┌─id─┬─name─┬─age─┐
│ 3 │ 王五 │ 20 │
│ 4 │ 马六 │ 21 │
└────┴─────┴────┘
┌─id─┬─name─┬─age─┐
│ 5 │ 田七 │ 22 │
│ 6 │ 赵八 │ 23 │
└────┴─────┴────┘
6 rows in set. Elapsed: 0.008 sec.注意:t_merge表不会在对应的库路径下产生对应的目录结构。
3. Distributed
Distributed是ClickHouse中分布式引擎,之前所有的操作虽然说是在ClickHouse集群中进行的,但是实际上是在node1节点中单独操作的,与node2、node3无关,使用分布式引擎声明的表才可以在其他节点访问与操作。
Distributed引擎和Merge引擎类似,本身不存放数据,功能是在不同的server上把多张相同结构的物理表合并为一张逻辑表。
分布式引擎语法:
Distributed(cluster_name, database_name, table_name[, sharding_key])对以上语法解释:
- cluster_name:集群名称,与集群配置中的自定义名称相对应。配置在/etc/metrika.xml文件中,如下图:
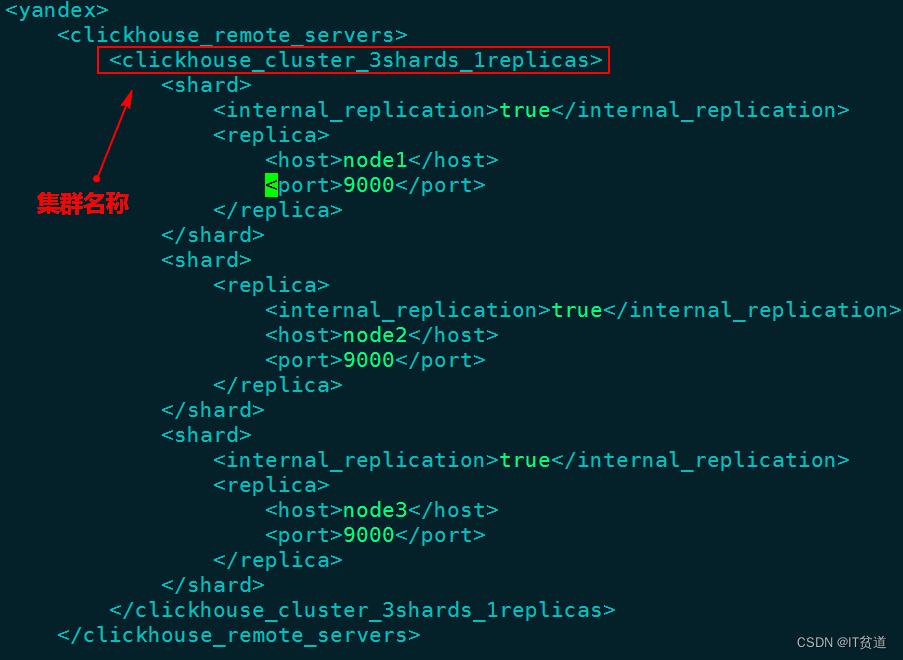
- database_name:数据库名称。
- table_name:表名称。
- sharding_key:可选的,用于分片的key值,在数据写入的过程中,分布式表会依据分片key的规则,将数据分布到各个节点的本地表。
注意:创建分布式表是读时检查的机制,也就是说对创建分布式表和本地表的顺序并没有强制要求。
- 示例:
#在node1、node2、node3节点上启动ClickHouse 服务
[root@node1 ~]# service clickhouse-server start
[root@node2 ~]# service clickhouse-server start
[root@node3 ~]# service clickhouse-server start
#使用默认的default库,在每个节点上创建表 test_table
node1 :) create table test_local (id UInt8,name String) engine= TinyLog
node2 :) create table test_local (id UInt8,name String) engine= TinyLog
node3 :) create table test_local (id UInt8,name String) engine= TinyLog
#在node1上创建分布式表 t_distributed,表引擎使用 Distributed 引擎
node1 :) create table t_distributed(id UInt8,name String) engine = Distributed(clickhouse_cluster_3shards_1replicas,default,test_local,id);
注意:以上分布式表 t_distributed 只存在与node1节点的clickhouse中。
#分别在node1、node2、node3节点上向表test_local中插入2条数据
node1 :) insert into test_local values (1,'张三'),(2,'李四');
node2 :) insert into test_local values (3,'王五'),(4,'马六');
node3 :) insert into test_local values (5,'田七'),(6,'赵八');
#查询分布式表 t_distributed 中的数据
node1 :) select * from t_distributed;
SELECT *
FROM t_distributed
┌─id─┬─name─┐
│ 1 │ 张三 │
│ 2 │ 李四 │
└──┴────┘
┌─id─┬─name─┐
│ 5 │ 田七 │
│ 6 │ 赵八 │
└──┴────┘
┌─id─┬─name─┐
│ 3 │ 王五 │
│ 4 │ 马六 │
└──┴────┘
6 rows in set. Elapsed: 0.010 sec.
#向分布式表 t_distributed 中插入一些数据,然后查询 node1、node2、node3节点上的test_local数据,发现数据已经分布式存储在不同节点上
node1 :) insert into t_distributed values (7,'zs'),(8,'ls'),(9,'ww'),(10,'ml'),(11,'tq'),(12,'zb');
#node1查询本地表 test_local
node1 :) select * from test_local;
SELECT *
FROM test_local
┌─id─┬─name─┐
│ 1 │ 张三 │
│ 2 │ 李四 │
│ 9 │ ww │
│ 12 │ zb │
└───┴────┘
4 rows in set. Elapsed: 0.004 sec.
#node2查询本地表 test_local
node2 :) select * from test_local;
SELECT *
FROM test_local
┌─id─┬─name─┐
│ 3 │ 王五 │
│ 4 │ 马六 │
│ 7 │ zs │
│ 10 │ ml │
└───┴────┘
4 rows in set. Elapsed: 0.004 sec.
#node3查询本地表 test_local
node3 :) select * from test_local;
SELECT *
FROM test_local
┌─id─┬─name─┐
│ 5 │ 田七 │
│ 6 │ 赵八 │
│ 8 │ ls │
│ 11 │ tq │
└───┴────┘
4 rows in set. Elapsed: 0.005 sec.以上在node1节点上创建的分布式表t_distributed 虽然数据是分布式存储在每个clickhouse节点上的,但是只能在node1上查询t_distributed 表,其他clickhouse节点查询不到此分布式表。如果想要在每台clickhouse节点上都能访问分布式表我们可以指定集群,创建分布式表:
#创建分布式表 t_cluster ,引擎使用Distributed 引擎
node1 :) create table t_cluster on cluster clickhouse_cluster_3shards_1replicas (id UInt8,name String) engine = Distributed(clickhouse_cluster_3shards_1replicas,default,test_local,id);
CREATE TABLE t_cluster ON CLUSTER clickhouse_cluster_3shards_1replicas
(
`id` UInt8,
`name` String
)
ENGINE = Distributed(clickhouse_cluster_3shards_1replicas, default, test_local, id)
┌─host──┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ node3 │ 9000 │ 0 │ │ 2 │ 0 │
│ node2 │ 9000 │ 0 │ │ 1 │ 0 │
│ node1 │ 9000 │ 0 │ │ 0 │ 0 │
└───────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
3 rows in set. Elapsed: 0.152 sec.上面的语句中使用了ON CLUSTER分布式DDL(数据库定义语言),这意味着在集群的每个分片节点上,都会创建一张Distributed表,这样便可以从其中任意一端发起对所有分片的读、写请求。
👨💻如需博文中的资料请私信博主。