算法的备胎Hash和找靠山的队列
备胎Hash
Hash,不管是算法,还是在工程中都会大量使用。很多复杂的算法问题都用Hash能够轻松解决,也正是如此,在算法例就显得没什么思维含量,所以Hash是应用里的扛把子,但在算法里就是备胎的角色,只要有其他方式,一般就不会考虑队列了。这也是面试算法和应用算法的一个区别。
Hash的重要性
Hash在技术面试中也频繁出现,常见问题有三个:
1.对象比较为什么要计算hashCode
2.HashMap的实现原理;ConcurrentHashMap的实现原理,特别是并发和扩容方面的问题。
3.ThreadLocal里的Map工作原理
找靠山的队列
直接考察队列的算法题几乎没有,大部分场景是作为高级算法的一个工具。经典问题是树里的层次遍历相关问题和图 等高级主题中 与 广度优先相关的问题。所以说队列需要找一个靠山才行。
队列的重要性
对于Java程序员来说,队列真正的大热门是作为技术面试,考察JUC里的阻塞队列、AQS等的实现原理等。这个一般在多线程相关的课程里讲解。
Hash基础
Hash的概念和基本特征
概念
哈希(Hash)也称为散列,就是把任意长度的输入,通过散列算法,变换成固定长度的输出,这个输出值就是散列值。
基本特征
映射:
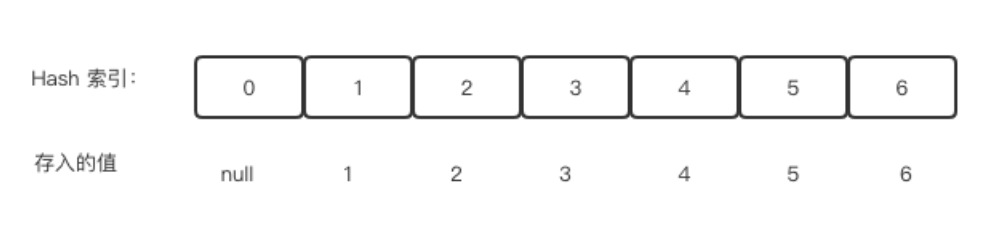
假设数组array存放的是1到15这些数,现在要存在一个大小是7的Hash表中,该如何存储呢?
存储(如下图所示):
存储位置计算公式
index = number % 7
读取:
index = number % 7
存储案例
将1至6存入的时候,图示如下:
将7至13存入的时候,图示如下:
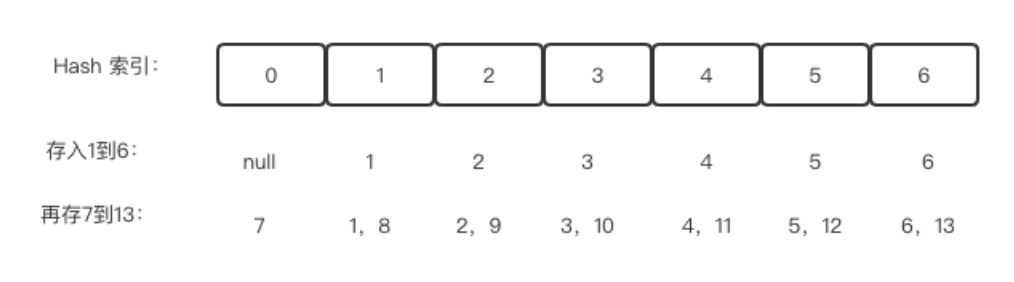
最后存14 和 15
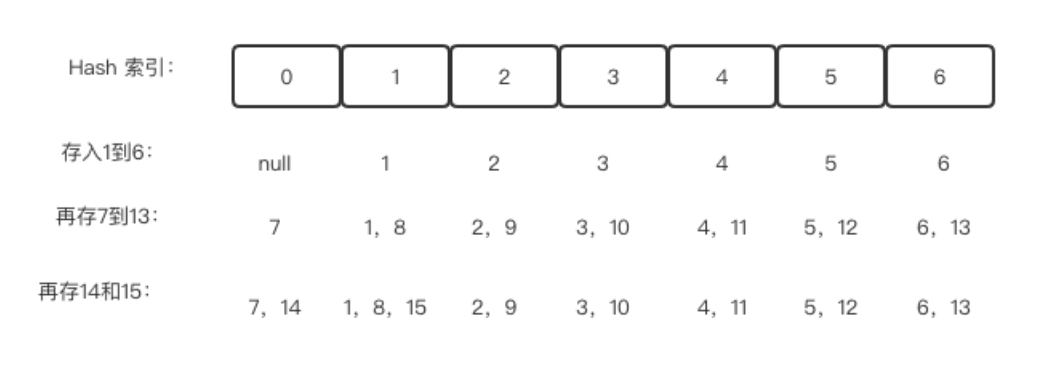
读取案例
假如我们要测试13在不在这个结构中,同样使用上面的公式进行计算。通过计算,
13 % 7 = 6。则可以直接访问array[6]这个位置,很明显是存在的,所以返回true。
假如我们要测试20在不在这个结构中,同样使用上面的公式进行计算。通过计算,
20 % 7 = 6。则可以直接访问array[6]这个位置,但这个位置上只有6和13,没有20,所以返回false。
碰撞处理方法
碰撞
在上面例子中,有些在Hash中的位置可能要存储两个甚至多个元素,很明显单纯的数组是不行的(会出现元素覆盖)。这种由 两个不同的输入值,根据同一散列函数计算出的散列值相同的现象 就叫做 碰撞。
碰撞解决方法
- 开放地址法(Java里的ThreadLocal)
- 链地址法(Java里的ConcurrentHashMap)
- 哈希法(布隆过滤器)
- 建立公共溢出区
开放定址法
开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将数据存入其中。
图例
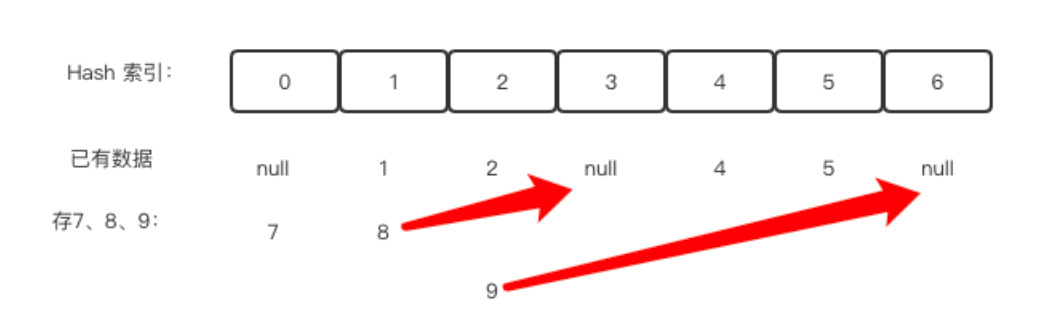
例如上面要继续存7,8,9的时候,7没问题,可以直接存到索引为0位置。8本来应该存到索引为1的位置,但是已经满了,所以继续向后找,索引3的位置是空的,所以8存到3位置。同理9存到索引6位置。
疑惑解释
疑惑:
这样鸠占鹊巢的方法会不会引起混乱? 比如再存3 和6的话,本来自己的位置好好的,但是被外来户占领了,该如何处理呢?
解释:
这个问题学习Java里的ThreadLocal后能解开。其基本思想如下:
ThreadLocal有一个专门存储元素的TheadLocalMap,每次在get 和set元素的时候,会先将目标位置前后的空间搜索一下,将标记为null的位置回收掉,这样大部分不用的位置就收回来了。
这就像假期后你到公司,每个人都将自己的位子附近打扫干净,结果整个工作区就很干净了。当然Hash处理该问题的整个过程非常复杂,涉及弱引用等等,这些都是Java技术面试里的高频考点。
链地址法
将哈希表的每个单元作为链表的头节点,所有哈希地址为 i 的元素构成一个同义词链表。即发生Hash冲突时,就把该关键字链在以该单位为头节点的链表的尾部,如下图所示:
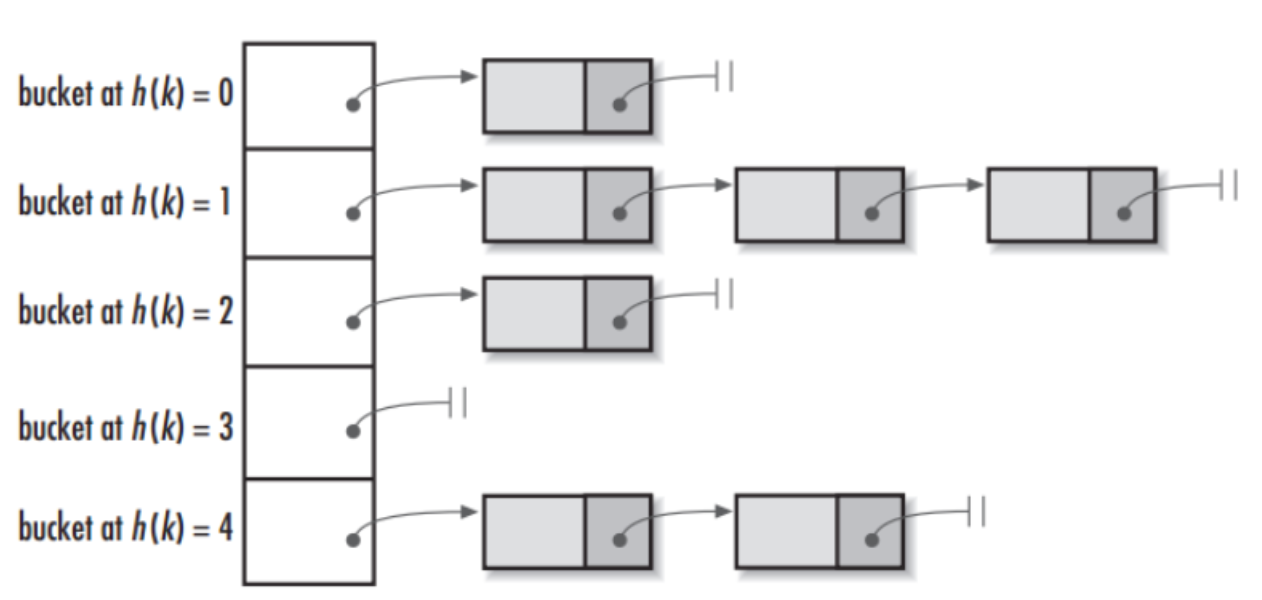
这种处理方法的问题是处理起来代价还是比较高的。要落地还要进行很多优化
例如在Java里的ConcurrentHashMap中就使用了这种方式,其中涉及元素尽量均匀、访问和操作速度要快、线程安全、扩容等很多问题
错误的Hash结构
看一下下面这个Hash结构,下面的图有两处非常明显的错误
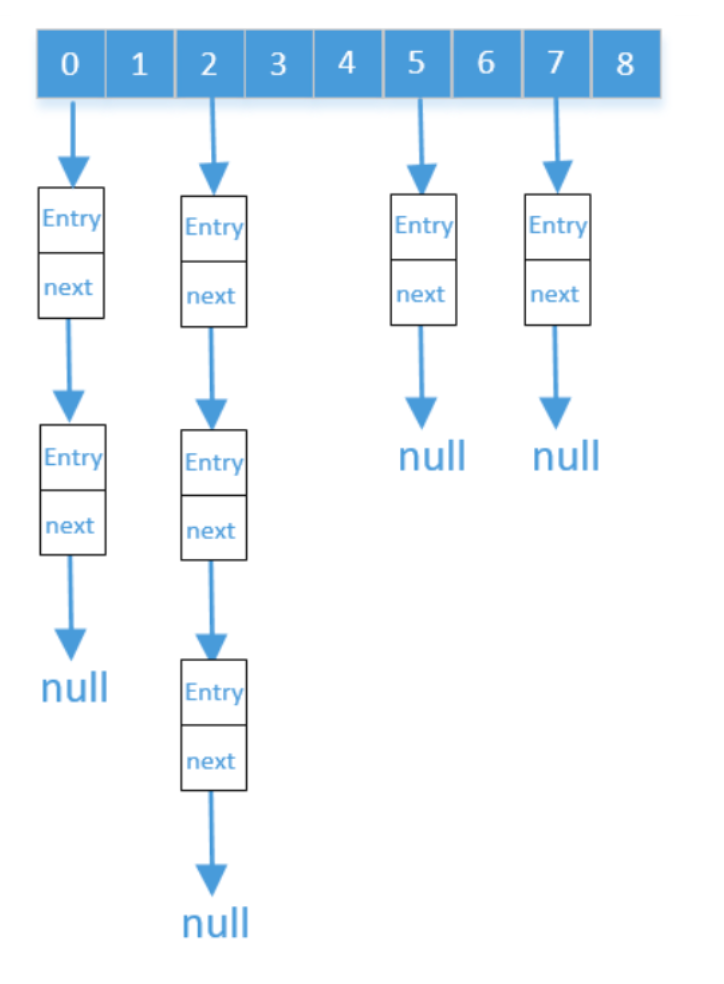
错误解释
首先是数组的长度必须是2的n次幂,这里长度是9,明显有错,然后是entry 的个数不能大于数组长度的75%,如果大于就会触发扩容机制进行扩容,这里明显是大于75%
原因
总:
在许多哈希表的实现中,选择2的n次幂作为哈希表的大小,可以提高散列函数的计算速度、解决哈希冲突的效率,并可以更好地利用内存。这些因素都有助于提高哈希表的性能。
分:
散列函数计算索引:哈希表使用散列函数将键(key)映射到索引,然后将值(value)存储在该索引处。对于2的n次幂大小的哈希表,散列函数可以使用位操作,而不需要执行较慢的模运算。例如,可以使用按位与运算(bitwise AND)操作,通过掩码来获取索引。这样可以提高散列函数的计算速度。
哈希冲突的解决:在哈希表中,不同的键可能会被散列到相同的索引位置,这称为哈希冲突。为了解决冲突,通常使用开放定址法、链表法或者其他方法。当哈希表的大小为2的n次幂时,使用位移操作(bitwise shift)可以快速计算出下一个索引位置,这样可以加快解决哈希冲突的速度。
内存分配的优化:许多现代计算机体系结构中,内存是以块(block)的形式进行分配的,其中每个块的大小通常是2的n次幂。如果哈希表的大小与内存块的大小匹配,可以更好地利用内存,减少内存分配的碎片化。
正确的Hash结构
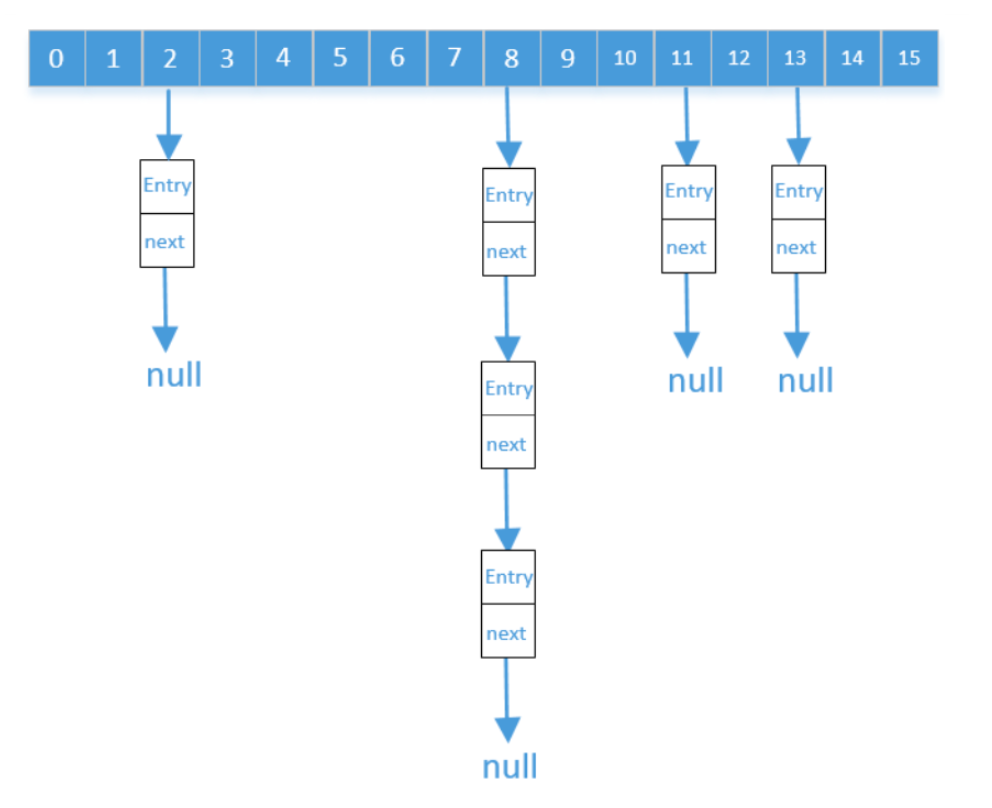
解释
数组的长度即是2的n次幂,而他的size又不大于数组长度的75%。 HashMap的实现原理是先要找到要存放数组的下标,如果是空的就存进去,如果不是空的就判断key值是否一样,如果一样就替换,如果不一样就以链表的形式存在链表中(从JDK8开始,根据元素数量选择使用链表还是红黑树存储)。
队列基础
队列的概念和基本特征
概念
队列(Queue)是一种常见的数据结构,它是一种先进先出(First-In-First-Out,FIFO)的线性数据结构。
基本特征
先进先出:节点的排排队次序和出队次序按入队时间先后确定
实现方式
- 数组
队列使用一个固定大小的数组来存储元素,并使用两个指针来标记队列的头部和尾部
- 链表
对于基于链表,因为链表的长度是随时都可以变的,实现起来比较简单。
实现队列
链表实现
package org.example.queue;
public class LinkQueue {
/**
* 构建节点
*/
static class Node{
public int data;
public Node next;
public Node(int data) {
this.data = data;
}
}
/*
创建队列头和尾
*/
private Node front;
private Node rear;
private int size;
// 初始化节点
public LinkQueue() {
this.front = new Node(0);
this.rear = new Node(0);
}
/**
* 入队
* @param value 入队数据
*/
public void push(int value){
Node newNode = new Node(value);
Node temp = front;
while (temp.next != null){
temp = temp.next;
}
temp.next = newNode;
rear = newNode;
size++;
}
/**
* 出队
* @return 出队的值
*/
public int pull(){
if (front.next == null){
System.out.println("队列已空,无法出队");
}
Node firstNode = front.next;
front.next = firstNode.next;
size--;
return firstNode.data;
}
/**
* 遍历队列
*/
public void traverse(){
Node temp = front.next;
while (temp != null){
System.out.println(temp.data + "\t");
temp = temp.next;
}
}
public static void main(String[] args) {
LinkQueue linkQueue = new LinkQueue();
linkQueue.push(1);
linkQueue.push(2);
linkQueue.push(3);
System.out.println("The first Node = " + linkQueue.pull());
System.out.println("队列遍历结果为");
linkQueue.traverse();
}
}