在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。
重排序分3种类型。
-
编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
-
指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-LevelParallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
-
内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
写缓冲区
写缓冲区临时保存向内存写入的数据。
好处:
写缓冲区可以保证指令流水线持续运行,它可以避免由于处理器停顿下来等待向内存写入数据而产生的延迟。同时,通过以批处理的方式刷新写缓冲区,以及合并写缓冲区中对同一内存地址的多次写,减少对内存总线的占用。
每个处理器上的写缓冲区,仅仅对它所在的处理器可见。这个特性会对内存操作的执行顺序产生重要的影响:
处理器对内存的读/写操作的执行顺序,不一定与内存实际发生的读/写操作顺序一致!
💥看下面这个栗子:

如果先执行了线程A1,再执行线程B2,那么 y=1;
如果先执行了线程B1,再执行线程A2,那么 x=2,
但现在出现了 x=y=0 的情况,很诡异的结果。
出现这种情况事务原因是 发生了指令重排序!!
看图分析:
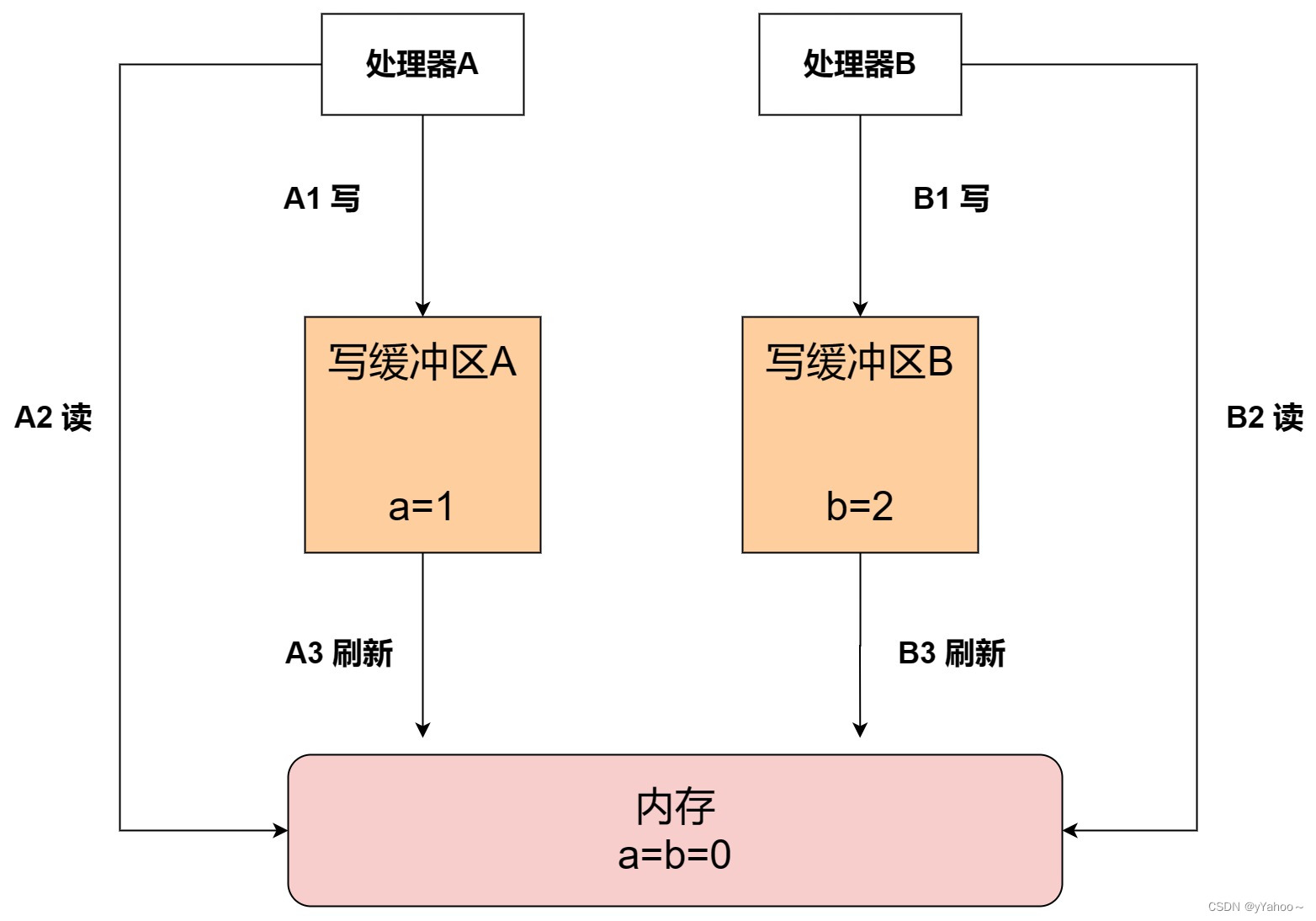
在程序执行的过程中,处理器A和处理器B同时把共享变量写入自己的写缓冲区(A1,B1),然后从内存中读取另一个共享变量(A2,B2),最后才把自己写缓存区中保存的脏数据刷新到内存中(A3,B3)。
当以这种时序执行时,程序就可以得到 x=y=0 的结果。
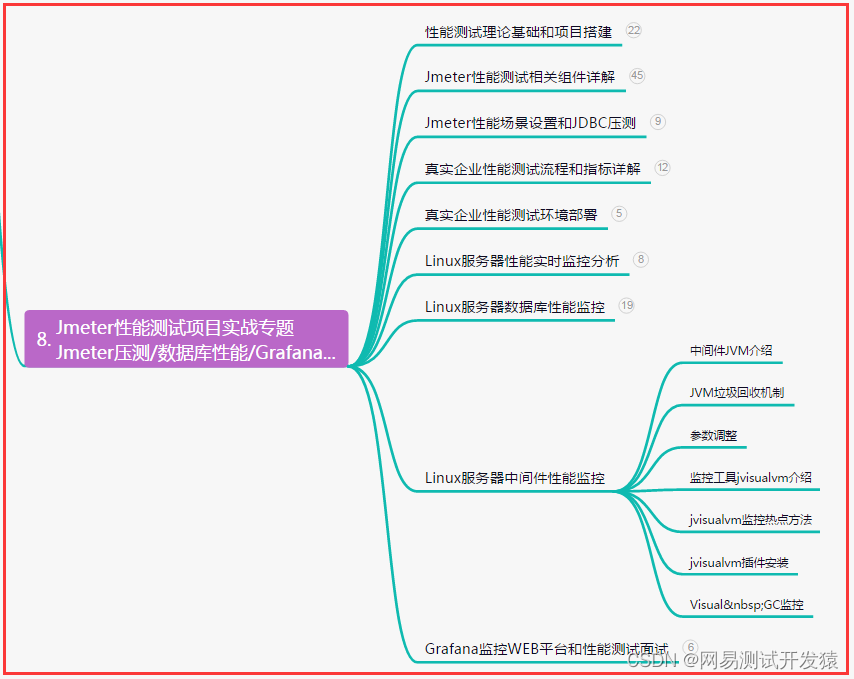
常见处理器允许的重排序类型:
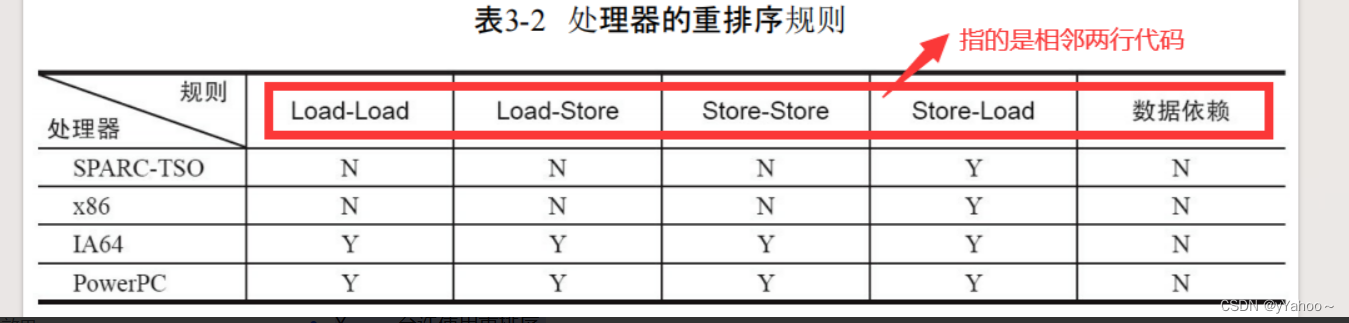
单线程内的相邻两行代码进行操作:
-
Load —— 读 (例如 x = b)
-
Store ——写(例如 b = 2)
-
N —— 不允许使用重排序
-
Y —— 允许使用重排序
内存屏障类型
每一个屏障都是为了防止每种类型发生指令重排序的问题。
其中最重要的是写后读,StoreLoad Barriers是一个“全能型”的屏障,它同时具有其他3个屏障的效果。

happens-before
两个操作之间具有happens-before关系,并不意味着前一个操作必须要在后一个操作之前执行!happens-before仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前。
volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读。(保障了写后读)
数据依赖性
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。
数据依赖分为下列3种类型
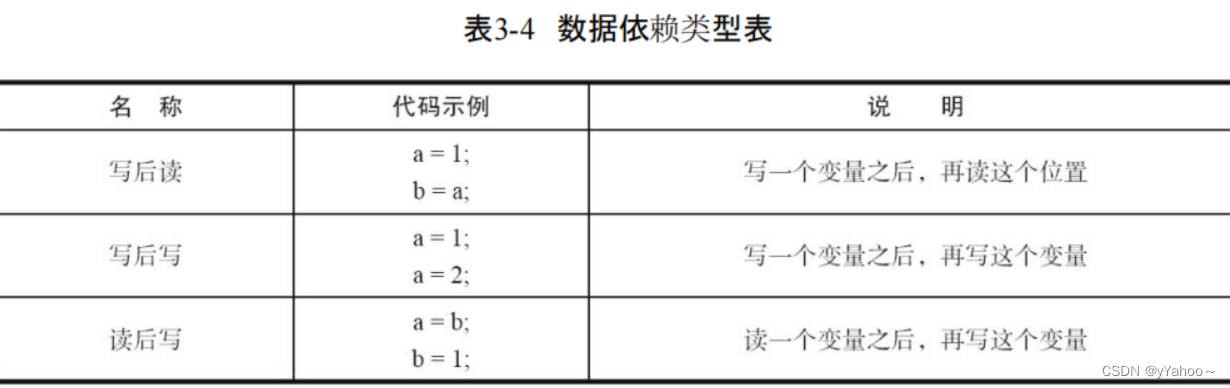 有数据依赖的情况下,重排序是没有用的!!
有数据依赖的情况下,重排序是没有用的!!
as-if-serial语义
在数据相互依赖的情况下,也可以实现指令重排序,只要不改变最后的执行结果就可以。
重排序对多线程的影响:
看这段代码: flag变量是个标记,用来标识变量a是否已被写入。
这里假设有两个线程A和B,A首先执行writer()方法,随后B线程接着执行reader()方法。线程B在执行操作4时,能否看到线程A在操作1对共享变量a的写入呢? 答案是:不一定能看到
class ReorderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; // 1
flag = true; // 2
}
public void reader() {
if (f?lag) { // 3
int i = a * a; // 4
……
}
}
} 对于程序结果,由于操作1和2指令重排序可能导致出现 i = 0的情况。在writer()方法中,可能 flag = true 先执行,此时 a=0;接着执行reader()方法,最后执行结果 i=0。
解决方法:
使用volatile修饰变量a,就可以防止指令重排序。