速通pytorch库(长文)
前言
本篇文章主要为那些对于pytorch库不熟悉、还没有上手的朋友们准备,梳理pytorch库的主要内容,帮助大家入门深度学习最重要的库之一。
目录结构
文章目录
- 速通pytorch库(长文)
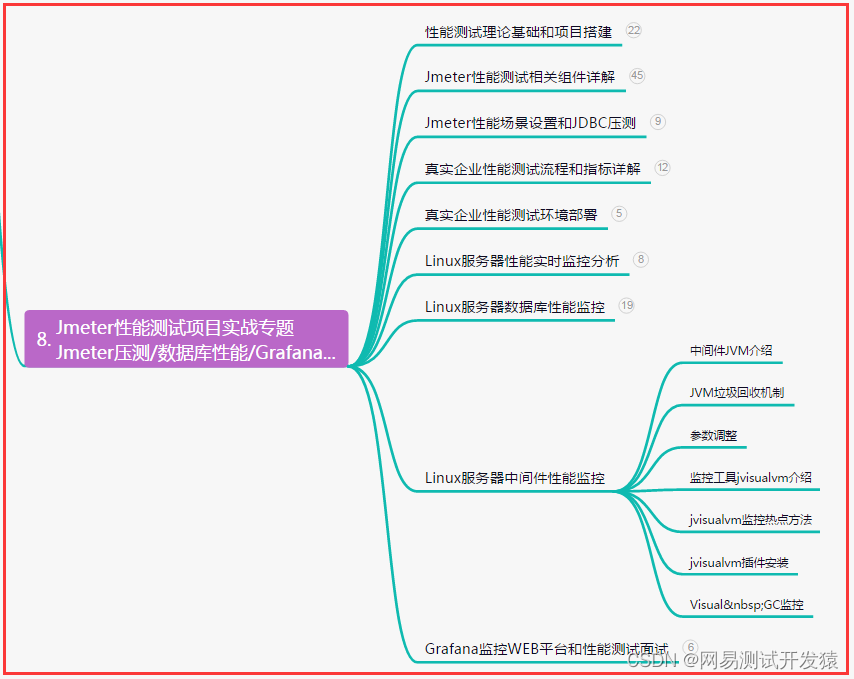
- 1. 介绍与安装
- 1.1 介绍
- 1.2 安装
- 2. Tensor及其常用方法:
- 2.1 创建Tensor:
- 2.2 Tensor对象属性:
- 2.3 常用运算:
- 2.4 tensor于array转换:
- 2.5 索引操作:
- 2.6 形状改变:
- 2.7 拼接:
- 2.8 其它常用方法总结:
- 3. 自动求导:
- 3.1 自动求导:
- 3.2 控制求导:
- 3.3 清空累计值:
- 3.4 Variable用法
- 3.5 其它注意点:
- 4. 模型创建和定义:
- 4.1 模型构建中涉及的方法:
- 4.1.1 激活函数:
- 4.1.2 参数初始化:
- 4.1.3 损失函数:
- 4.1.4 优化方法:
- 4.1.5 数据扁平化:
- 4.1.6 模型参数补充:
- 4.2 模型各个层的定义:
- 4.2.1 线性层/全连接层:
- 4.2.2 卷积层:
- 4.2.3 最大池化层
- 4.2.4 平均池化层:
- 4.2.5 dropout层:
- 4.2.6 BN层:
- 4.3 模型的存储方法:
- 4.3.1 Sequential:
- 4.3.2 ModuleList:
- 4.3.3 ModuleDict:
- 4.4 模型定义:
- 5. 数据加载和读入:
- 5.1 文件夹整理:
- 5.2 Dataset制作:
- 5.3 DataLoader使用:
- 5.4 其它方法—ImageFloder:
- 5.5 自带数据使用:
- 6. 模型训练和评估:
- 7. 可视化:
- 7.1 torchinfo:
- 7.2 tensorboard:
- 7.3 举例:
- 8. 调用GPU:
- 8.1 检测是否可以使用GPU:
- 8.2 查看GPU数量和名字:
- 8.3 调用步骤:
- 9. torchvision模块:
- 9.1 transforms常用方法:
- 9.2 models常用方法:
- 10. 模型保存与加载:
- 10.1 保存和加载整个模型:
- 10.2 保存和加载模型参数:
- 9. torchvision模块:
- 9.1 transforms常用方法:
- 9.2 models常用方法:
- 10. 模型保存与加载:
- 10.1 保存和加载整个模型:
- 10.2 保存和加载模型参数:
1. 介绍与安装
1.1 介绍
pytorch库是目前使用率最高的实现深度学习的库之一,另外一个是tensorflow。关于两者的选择,首先是看你的课题组/公司使用的什么框架,如果你是自由学习者,其实两者都可以选择学习,不过建议是pytorch。
1.2 安装
pytorch的安装网上已经有很多详细的安装教程了,大家可以自行搜索。不过,需要注意的是一定要安装GPU版本的,不然很多项目运行时都会报错。
2. Tensor及其常用方法:
Tensor,即张量,是PyTorch中的基本操作对象,可以看做是包含单一数据类型元素的多维矩阵。从使用角度来看,Tensor与NumPy的ndarrays非常类似,相互之间也可以自由转换,只不Tensor还支持GPU的加速。
因此,可以大胆的把tensor看作类似array的对象。
2.1 创建Tensor:
普通的创建
a = torch.tensor([[1,2],
[3,4]])
print(a)
注意:如果数据全为整数,那么tensor默认为INT64类型,一旦有小数,类型就会变为float32。
创建数据为零的张量
# 创建数据为零的张量
b = torch.zeros((2,3)) # 输入指定形状即可
print(b) # 默认为float32
创建数据为1的张量
# 创建数据为1的张量
c = torch.ones((3,3,3))
print(c)
创建单位矩阵
# 创建单位矩阵
d = torch.eye(3)
print(d)
创建数据为随机值的张量
# 创建数据为随机值的张量
e = torch.randn((2,3)) # 正态分布,均值为0,方差为1
f = torch.rand((2,3)) # 均匀分布,[0,1)的均匀分布
print(e)
print(f)
创建指定范围的一维张量
g = torch.arange(1,20,3) # 起始值,结束值,步长
print(g)
h = torch.linspace(1,100,100) # [start=1,end-100]个数100个
print(h)
print(h.size())
2.2 Tensor对象属性:
形状
a = torch.ones((3,4))
print(a.shape)
print(a.size())
数据类型
a = torch.ones((3,4))
print(a.dtype)
方法:numel()
# 返回元素个数
a = torch.ones((3,4))
print(a.numel()) # 12
2.3 常用运算:
| 运算 | 方法 | 参数 | 说明 |
|---|---|---|---|
| 绝对值 | torch.abs(a) | ||
| 相加 | + 或者 torch.add(c,d) | ||
| 裁剪 | torch.clamp(e,2,4) | 裁剪对象,下界,上界 | 将tensor中每个值与上界和下界比较,低于下界则改写为下界值,高于上界则改写为上界值,中间的不变。 |
| 除法 | torch.div(f,2) | 除法是对应元素相除 | |
| 幂运算 | torch.pow(h,3) | ||
| 对应元素相乘 | torch.mul(f,g) | ||
| 矩阵相乘 | torch.mm(i,j) | ||
| 判断大小 | torch.ge(input, other) | 待对比的张量,对比的张量 | 两个张量的值一一对比,值相同的位置为1,否则为0 类似的方法还有:le(是否小于等于)、ge(是否大于等于) |
| 获得索引位置 | torch.where(condition,a,b) | condition为条件判定,当满足条件时,对应位置为a的值否则为b的值 | 一般和上面的方法联合使用,比如: torch.where(torch.eq(a,b[:,None])) |
2.4 tensor于array转换:
tensor —> array
a = torch.tensor([2,3])
b = a.numpy()
c = np.array(a)
print(type(b))
print(type(c))
array—>tensor
d = np.array([2,3])
e = torch.tensor(d)
print(type(e))
2.5 索引操作:
tensor的索引和普通的索引没有什么区别,只是需要注意的是tensor中的内存共享:
import torch
a = torch.randn((3,4))
b = a[0,0]
print(b)
b += 1
print(a)
运行结果为:
tensor(-0.4613)
tensor([[ 0.5387, -1.2455, 0.4596, -0.9547],
[ 1.7746, 0.2623, -0.2514, 1.4591],
[-0.1769, 2.2323, 0.1277, 0.2700]])
即,虽然我们把a[0,0]赋值给了变量b,但是由于两者内存都指向的同一个地址,因此你修改b,a对应值也会变化。
2.6 形状改变:
import torch
a = torch.randn(5,4)
# 先克隆一个
b = torch.clone(a)
# 再改变形状
c = a.view(4,5)
print(c)
注意:由于内存共享,因此在改变形状之前,先克隆一个备份,再来改变形状。
还有一个类似的方法:
import torch
a = torch.randn(5,4)
b = torch.reshape(a,(4,5)) # 参照numpy方法,不过view只能用于连续内存
print(b)
上述方法还有一种很常用的形式:
a.view(-1,5) # 表示第二个维度为5,第一个维度的值自己推导
2.7 拼接:
| 方法 | 参数 |
|---|---|
| torch.cat() | 第一个参数,(A,B,…),是要拼接的对象 第二个参数,dim,指定从哪个维度拼接,0为按行拼接(拼接的维度要相同) |
| torch.stack() | 第一个参数,(a,b),即要拼接的对象,形状必须相同 第二个参数,dim,拼接后新增维度的索引 |
举例:
import torch
a = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
b = torch.tensor([[11, 22, 33], [44, 55, 66], [77, 88, 99]])
c = torch.stack([a, b], 0)
print(a)
print(b)
print(c)
# 输出信息:
tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
tensor([[11, 22, 33],
[44, 55, 66],
[77, 88, 99]])
tensor([[[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9]],
[[11, 22, 33],
[44, 55, 66],
[77, 88, 99]]])
2.8 其它常用方法总结:
| 方法名 | 作用 | 示例/参数讲解 |
|---|---|---|
| squeeze() | 对数据的维度进行压缩,去掉维数为1的的维度 | squeeze(0):代表若第一维度值为1则去除第一维度 |
| unsqueeze() | 对数据的维度进行扩容,即升维 | x.unsqueeze(0),即在第一个维度扩充一个维度 |
| sort() | 按照指定的维度对tensor张量的元素进行排序 | 参数: descending(bool, optional):False表示升序,True表示降序 返回值: 第一个tensor表示对应维度张量值排序;第二个tensor表示对应维度张量值得索引序列 |
| numel() | 迅速查看一个张量到底又多少元素 |
3. 自动求导:
自动求导是pytorch的核心功能,也是我们实现我们的神经网络算法的核心。其主要应用是用来处理反向传播算法。
3.1 自动求导:
基本方法
下面,我们通过一个例子来演示:
构建 y = x + b,然后对y求导
那么,实现方法如下:
import torch
b = torch.randn((3,4),requires_grad=True) # requires_grad = True 必须声明
x = torch.randn((3,4),requires_grad=True)
# 定义一个函数
t = x + b
y = t.sum() # 这一步是因为只有标量才可以求导(pytorch所规定)
# 求导
y.backward()
# b的梯度
print(b.grad)
# x的梯度
print(x.grad)
运行结果如下:
tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
# 正确结果,因为为线性函数嘛
不难从上面看出,想要自动求导需要的步骤为:
# 1. 定义数据和函数
xxxx = torch.tensor(xxx,requires_grad=True)
fx = xxxx
# 2. 对目标求导:fx要为标量
fx.backward()
# 3. 计算想要的参数的梯度
print(xx.grad)
深入探究1
想要探究一下:是否所有变量都要声明requires_grad=True?
- 所有变量都声明
这个就是上面的例子,显然是可以正常运行的。
- 只有一个变量声明
代码一:
import torch
b = torch.randn((3,4),requires_grad=True)
x = torch.randn((3,4))
# 定义一个函数
t = x + b
y = t.sum()
# 求导
y.backward()
# b的梯度
print(b.grad)
# x的梯度
print(x.grad)
结果为:
tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
None
代码二:
import torch
b = torch.randn((3,4))
x = torch.randn((3,4),requires_grad=True)
# 定义一个函数
t = x + b
y = t.sum()
# 求导
y.backward()
# b的梯度
print(b.grad)
# x的梯度
print(x.grad)
结果为:
None
tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
- 一个也不声明
显然,这样结果肯定报错。
- 总结
通过上面的测试,可以看出:如果你想求解梯度的变量是最基层(底层,不由其它变量构成)的变量,那么你必须为它声明requires_grad=True,但是如果你对它不感兴趣,可以不用设置。
深入研究2
另外一个问题:是否所有变量都声明了requires_grad=True,函数才可以调用backward方法?
这个答案,其实上面的案例已经告诉我们了——不是。那么,是不是声明一个变量,那么由这个变量构成的函数就可以使用backward方法呢?
看代码:
import torch
b = torch.randn((3,4))
x = torch.randn((3,4),requires_grad=True)
# 定义一个函数
t1 = x + b # 由x构成的函数
y1 = t1.sum()
t2 = b*3 # 不由x构成的函数
y2 = t2.sum()
# 查看是否可以
print(y1.requires_grad) # 返回变量requires_grad是否为True
print(y2.requires_grad)
结果为:
True
False
综上,得出结论:只要有一个变量声明了requires_grad=True,那么由它构成的函数requires_grad也为True,可以正常使用backward方法。
3.2 控制求导:
有时候,我们的一些量不需要参与梯度计算。此时,就需要这个方法:
import torch
x = torch.randn((3,4),requires_grad=True)
with torch.no_grad(): # 这样y不受x的requires_grad=True影响
y = x ** 2
print(y.requires_grad) #false
3.3 清空累计值:
梯度计算默认会累加,但是一般情况下我们并不需要累加:
import torch
x = torch.tensor([10,20,30,40],requires_grad=True,dtype=torch.float32)
for i in range(5):
y = x**2 +10
# 转为标量
y1 = y.mean()
# 自动求导
y1.backward()
print(x.grad)
运行结果:
tensor([ 5., 10., 15., 20.])
tensor([10., 20., 30., 40.])
tensor([15., 30., 45., 60.])
tensor([20., 40., 60., 80.])
tensor([ 25., 50., 75., 100.])
因此,需要进行清除累加值:
import torch
x = torch.tensor([10,20,30,40],requires_grad=True,dtype=torch.float32)
for i in range(5):
y = x**2 +10
# 转为标量
y1 = y.mean()
# 清楚累加
if x.grad is not None:
x.grad.data.zero_()
# 自动求导
y1.backward()
print(x.grad)
3.4 Variable用法
我们创建FloatTensor的时候,没有参数指定requires_grad=True,因为这个FloatTensor是一个类,不是我们常用的方法,对于这类的变量想要加入微分系统中,即可以自动求导,需要特别处理。
方法一
使用Variable方法:
import torch
from torch.autograd import Variable
b = torch.FloatTensor([1,2,3])
b = Variable(b)
print(b.requires_grad)
方法二
使用自带的属性:
import torch
a = torch.FloatTensor([1,2,3]).requires_grad_() # 默认为True
print(a.requires_grad)
3.5 其它注意点:
1. 只有浮点型和复数型可以进行自动梯度求导
2. 自动求导默认累加,需要自己清空
3. 只有标量可以自动求导,因此需要手动转换,比如上面中t.sum()
4. 当一个张量设置了requires_grad=True后,不可以直接转为numpy对象,需要先使用detach方法生成一个新张量,然后进行转换。
关于第四点这里举一个例子:
import torch
x = torch.randn((3,4),requires_grad=True)
c = x.numpy()
上面代码直接运行会报错,需要修改为:
import torch
x = torch.randn((3,4),requires_grad=True)
new_x = x.detach()
c = new_x.numpy()
print(type(c)) # <class 'numpy.ndarray'>
4. 模型创建和定义:
4.1 模型构建中涉及的方法:
4.1.1 激活函数:
首先,你需要知道各个激活函数的名字是什么,然后按照下面的模板使用即可:
import torch
from matplotlib import pyplot as plt
x = torch.arange(-100,100,1)
y = torch.sigmoid(x) # torch.函数名字
plt.figure()
plt.plot(x,y)
plt.show()
小提一句:上面的torch.xxx是画函数的方法,具体用的时候还是使用torch.nn.xxxx
# softmax多分类
torch.nn.LogSoftmax(dim=1/0)
# 1 表示按行求和为1
# 0 表示按列求和为1
4.1.2 参数初始化:
主要的参数方法有:
1. 均值初始化
2. 高斯分布初始化
3. Xavier初始化
4. He初始化
5. 其它初始化:固定值初始化等
下面,一一介绍相关的API:
import torch
import torch.nn as nn
# 1. 均匀分布
def test1():
# 定义一个层,这样才有参数
linear = nn.Linear(5,3) # 输入特征维度为5,输出特征维度为3
nn.init.uniform_(linear.weight)
print(linear.weight)
# 2. 高斯分布
def test2():
# 定义一个层,这样才有参数
linear = nn.Linear(5,3) # 输入特征维度为5,输出特征维度为3
nn.init.normal_(linear.weight,mean=0,std=1)
print(linear.weight)
# 3. Xavier初始化
def test3():
# 定义一个层,这样才有参数
linear = nn.Linear(5,3) # 输入特征维度为5,输出特征维度为3
nn.init.xavier_normal_(linear.weight) # 可以为normal(高斯)、uniform(均匀)
print(linear.weight)
# 4. He初始化
def test4():
# 定义一个层,这样才有参数
linear = nn.Linear(5,3) # 输入特征维度为5,输出特征维度为3
nn.init.kaiming_uniform_(linear.weight)
print(linear.weight)
# 5. 固定值初始化
def test5():
# 定义一个层,这样才有参数
linear = nn.Linear(5,3) # 输入特征维度为5,输出特征维度为3
nn.init.constant_(linear.weight,5)
print(linear.weight)
4.1.3 损失函数:
下面,介绍几个常用的损失函数,其它的损失函数可以拓展。
使用的通用模板为:
# 1. 创建损失对象
loss = nn.L1Loss()
# 2. 计算损失
output = loss(input, target)
# 3. 计算损失的梯度
output.backward()
需要补充一句:loss对象是零维的,因此不可以使用索引来获取值,只能通过item来获取,虽然原理我不太明白。
loss_obj.item()
L1损失函数
计算输出y和真实标签target之间的差值的绝对值。
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')
'''
参数:
reduction参数决定了计算模式。有三种计算模式可选:
none:逐个元素计算
sum:所有元素求和,返回标量。
mean:加权平均,返回标量
'''
MSE损失函数
计算输出y和真实标签target之差的平方
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
二分类损失函数
计算二分类的 logistic 损失
torch.nn.SoftMarginLoss(size_average=None, reduce=None, reduction='mean')
交叉熵损失函数
loss_fc = nn.CrossEntropyLoss()
4.1.4 优化方法:
我们可以通过类的定义来自己定义相关方法,也可以简单的通过调用函数来实现。这里我仅介绍后面通用的方法:(后面案例如果涉及了其它的会补充)
# 1.实例化优化器
# 参数: 参数、学习率、动量大小
optimizer = torch.optim.SGD([weight], lr=0.1, momentum=0.9)
# 2. 梯度更新、参数更新
optimizer.step()
# 3. 输出参数
optimizer.param_groups
# 4. 添加参数组
optimizer.add_param_group({"params": weight2, 'lr': 0.0001, 'nesterov': True})
同样的,如果我们知道优化器的名字,就可以使用,因为pytorch都定义了的:
torch.optim.Adagrad
torch.optim.Adam
torch.optim.SGD
torch.optim.RMSprop
# 常用的优化方法
另外,对于优化对象的一些常用属性和方法,下面略作介绍:
param_groups:管理的参数组,是一个list,其中每个元素是一个字典step():执行一步梯度更新,参数更新add_param_group():添加参数组
4.1.5 数据扁平化:
假设你的数据为1维数据,那么这个数据天然就已经扁平化了,如果是2维数据,那么扁平化就是将2维数据变为1维数据,如果是3维数据,那么就要根据你自己所选择的“扁平化程度”来进行操作,假设需要全部扁平化,那么就直接将3维数据变为1维数据,如果只需要部分扁平化。
方法
torch.flatten(obj,start,end)
'''
参数:
obj:操作的对象
start:开始flatten的维度,可以不指定,默认为0
end:结束flatten的维度,可以不指定,不指定默认为-1
返回值:
新的数据
'''
仔细理解:
# part 1
a = torch.arange(0,5,1) # tensor([0, 1, 2, 3, 4])
print(a.size()) # torch.Size([5])
b = torch.flatten(a)
print(b) # tensor([0, 1, 2, 3, 4])
# part2
a = torch.ones((3,3,3))
print(a.size()) # torch.Size([3, 3, 3])
b = torch.flatten(a)
print(b.size()) # torch.Size([27])
从上面的代码不难看出:b = torch.flatten(a)这样写就是直接变为1维的数据。
再看下面代码:
# part3
a = torch.ones((3,3,3))
print(a.size()) # torch.Size([3, 3, 3])
b = torch.flatten(a,start_dim=0)
print(b.size()) # torch.Size([27])
c = torch.flatten(a,start_dim=1)
print(c.size()) # torch.Size([3, 9])
d = torch.flatten(a,start_dim=2)
print(d.size()) # torch.Size([3, 3, 3])
e = torch.flatten(a,start_dim=3)
print(e.size()) # 报错
f = torch.flatten(a,start_dim=1,end_dim=2)
print(f.size()) # torch.Size([3, 9])
从上面的代码可以看出:start_dim与end_dim是从0开始算的,所谓的start_dim就是从第几个维度开始拉伸,end_dim就是从第几个维度结束。比如上面中c = torch.flatten(a,start_dim=1)就是从第二个维度开始拉伸,那么第一个维度不变,结果为3*9(9是后面3*3的结果)。
4.1.6 模型参数补充:
模型参数分为两个部分:**模型整体所有参数,各个层的参数。**针对不同对象有不同的方法:
- 模型整体参数:
obj = model.parameters()
# 返回一个可迭代的参数对象
- 各个层的参数
# 一般用于模型构建类中,用法都是
self.layer_obj.weight # 除去偏置外的参数
self.layer_obj.bias # 偏置
4.2 模型各个层的定义:
下面,介绍一下pytorch各种层的定义,主要是用来构建神经网络模型。
4.2.1 线性层/全连接层:
torch.nn.Linear
主要的三个参数为:
1. 输入特征数
2. 输出特征数
3. 是否启用偏置
**值得注意的是:**会自动生成对应维度的权重参数和偏置,对于生成的权重参数和偏置,我们的模型默认使用一种比之前的简单随机方式更好的参数初始化方式。
4.2.2 卷积层:
torch.nn.Conv2d
# Conv1d一般用于nlp,根据我猜测应该是指的是一维卷积核
主要的参数为:
1. 输入通道数
2. 输出通道数
3. 卷积核大小
4. 卷积核移动步长和paddingde值
4.2.3 最大池化层
torch.nn.MaxPool2d
主要参数为:
1. 池化窗口的大小
2. 池化窗口移动步长和paddingde值
4.2.4 平均池化层:
average_pool = nn.AvgPool2d(2,stride=2)
# 参数也是kernel_size和步长
4.2.5 dropout层:
torch.nn.Dropout(p) # 参数p指定丢失概率
4.2.6 BN层:
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# affine定义了BN层的参数γ和β是否是可学习的(不可学习默认是常数1和0).
4.3 模型的存储方法:
模型存储指的是将各个层放入一个容器中,这个不同的容器就是我们不同的模型存储方法。
4.3.1 Sequential:
所在模块
torch.nn.Sequential
作用
可以用于定义有序的层,而模型的前向计算就是根据顺序来计算的。
方法
其实现方法有两种:
- 直接一层一层的定义
import torch.nn as nn
net = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10),
)
print(net)
- 通过一个有序字典加入
import collections
import torch.nn as nn
net2 = nn.Sequential(collections.OrderedDict([
('fc1', nn.Linear(784, 256)),
('relu1', nn.ReLU()),
('fc2', nn.Linear(256, 10))
]))
print(net2)
优缺点
使用Sequential定义模型的好处在于简单、易读,同时使用Sequential定义的模型不需要再写forward,因为顺序已经定义好了(这一点后面说)。
但使用Sequential也会使得模型定义丧失灵活性,比如需要在模型中间加入一个外部输入时就不适合用Sequential的方式实现。
4.3.2 ModuleList:
所处模块
torch.nn.ModuleList
作用
ModuleList 接收一个子模块(或层,需属于nn.Module类)的列表作为输入,然后也可以类似List那样进行append和extend操作。同时,子模块或层的权重也会自动添加到网络中来。
方法
首先,先定义一个ModuleList:
net = nn.ModuleList([nn.Linear(784, 256), nn.ReLU()])
net.append(nn.Linear(256, 10)) # # 类似List的append操作
print(net[-1]) # 类似List的索引访问
print(net)
然后,需要定义前向方法才算形成一个网络:
class model(nn.Module):
def __init__(self, ...):
super().__init__()
self.modulelist = ...
def forward(self, x):
# 指定计算的顺序即可
for layer in self.modulelist:
x = layer(x)
return x
这里表明了计算方法就是输出数据 = 层(输入数据)(后面说)
4.3.3 ModuleDict:
模块
torch.nn.ModuleDict
作用
ModuleDict和ModuleList的作用类似,只是ModuleDict能够更方便地为神经网络的层添加名称。
方法
首先,还是先定义ModuleDict,不然此时接收的为字典:
net = nn.ModuleDict({
'linear': nn.Linear(784, 256),
'act': nn.ReLU(),
})
net['output'] = nn.Linear(256, 10) # 添加
print(net['linear']) # 访问
print(net.output) # 访问
print(net)
然后,就是定义顺序,这一点和上面的ModuleList相同。
4.4 模型定义:
上面的方法,诸如Sequnetial\ModuleList等,其实是模型层的容纳器,而不是我们的模型对象。
构建模型对象,需要自定义模型类,只是这个类需要继承自torch.nn.Module,另外这个类还有一些必须定义的方法和常用的方法:
import torch
from torch import nn
class MLP(nn.Module):
# 声明带有模型参数的层
def __init__(self):
# 调用MLP父类Block的构造函数来进行必要的初始化。这样在构造实例时还可以指定其他函数
super(MLP, self).__init__()
# 然后,我们需要在这里把我们的神经网络的各个层定义出来,可以使用sequential来定义
self.model = nn.Sequnetial(xxxxxx)
# 定义模型的前向计算,即如何根据输入x计算返回所需要的模型输出
# 即,我们必须把我们的模型存储对象中的各个层定义一个顺序
def forward(self, x):
pass
**上面两个方法是必须定义的。**另外,前向算法定义顺序,对于不同的存储方法来说是不同的:
# 比如Sequential,本身就是按照顺序装入各个层的,因此不需要定义顺序,直接:
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequnetial(xxxxxx)
def forward(self, x):
self.model(x) # Sequential
# 而对于ModuleLIst/ModuleDIct方法,就必须为它定义顺序,你可以使用:
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.ModuleDict/ModuleList(xxxxxx)
def forward(self, x):
# 方式1
for layer in self.model:
xxx
# 方式2
x = self.model[1](x)
x = self.model[3](x)
x = self.model[2](x)
.....
另外,还有一些非常常用的方法:
self.modules()
# 返回一个迭代对象,里面的内容为当前模型的所有层
'''
ex:
for m in self.modules():
pass
'''
self.train(mode=True)
# 设置当前模式为训练模式
self.eval(mode=True)
# 设置当前模式为验证模式
'''
上面两个方法主要是针对一些算法而设置的,因为一些算法在训练与测试上表现不一致,因此才需要设置当前模型正在干什么
'''
5. 数据加载和读入:
PyTorch数据读入是通过Dataset+DataLoader的方式完成的,Dataset定义好数据的格式和数据变换形式,DataLoader用iterative的方式不断读入批次数据。
这里,也需要明确一点:由于深度学习中数据量十分庞大,因此一般不直接加载所有数据,而是分批次的加载与训练。
我们可以通过继承DataSet类来创建我们自己的数据加载函数,也可以直接调用相应方法来实现。
5.1 文件夹整理:
一般的图像数据能拿到的格式为:
大文件夹
训练集
测试集
train.txt
test.txt
其中,一般训练集和测试集不会给你命名好的文件,而是直接按照顺序存储的文件,而txt文件则是存储的图片和标签对应关系。
5.2 Dataset制作:
DataLoader一般的处理流程为:
原始数据 --- 清洗打乱顺序 --- 使之变为可迭代对象 --- 使之变为batch
针对我们上面所说的文件格式,我们要做以下预处理:
# 1. 处理train.txt中的“图片名字 标签”,将两者进行一定的存储
# 2. 将名字、标签分开存储于两个列表中
# 3. 将图片名字与绝对路径拼接成为一个真实可靠的路径列表
下面,开始制作Dataset类:
# 1. 导入库
from torch.utils.data import Dataset,DataLoader
# 2. 定义类
class MyDataset(Dataset):
def __init__(self,root_dir,ann_file,transform=None):
self.ann_file = ann_file # 图片名字
self.root_dir = root_dir # 绝对路径(不含文件名字)
self.img_lable = self.load_annotations() # 图像名字和标签字典,key为图片名字,value为标签值
self.img = [os.path.join(self.root_dir,img) for img in list(self.img_label.keys())]
self.img = [label for label in list(self.img_label.values())]
self.transform = transform # 对数据的预处理,有则写,无则不写
def __len__(self):
# 返回数据的样本个数,这是调用len(xxx)返回的结果(个人认为)
return len(self.img)
def __getitem__(self,idx):
# idx为固定的参数,每次调用的时候会随机参数一个idx来进行索引
# 必须定义的函数,表示你迭代时获取的值
image = Image.open(self.img[idx]) # 打开图片
label = self.label[idx] # 获取标签值
if self.transform:
# 如果有预处理+转为tensor格式
image = self.transform(image)
# 转为tensor数据
label = torch.from_numpy(np.array(label))
return image,label
def load_annotations(self):
# 自定义的函数,主要是处理train,txt文件
# 返回的是我们上面所说预处理第一步
data_infos = {}
with open(self.ann_file) as f:
samples = [x.strip().split(' ') for x in f.readlines()]
for filename,gt_label in samples:
data_infos[filename] = np.array(gt_label,dtype=np.int64)
return data_infos
5.3 DataLoader使用:
当我们定义好了Dataset后,就可以使用DataLoader来加载我们的数据了。
在用之前可以先测试一下:
# 1. 实例化Dataset
train_dataset = MyDataset(...)
# 2. 实例化DataLoader
train_loader = DataLoader(train_dataset,batch_szie=64,shuffle=True)
'''
必须指定参数:
batch_size: 每批的数据个数
shuffle: 是否打乱数据
'''
# 3. 小迭代试试
image,label = iter(train_loader).next()
如果真实训练的话,大致这么写:
for epoch in range(num):
# 表示训练多少次
for image,label in train_loader:
# 开始训练
xxxxxx
详细参数介绍:
* num_workers:(数据类型 Int)
使用多少个子进程来导入数据
* drop_last:(数据类型 bool)
丢弃最后数据
5.4 其它方法—ImageFloder:
ImageFolder假设所有的文件按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类名,这样可以使用该方法实现快速读取数据和加载数据。
方法
dataset = ImageFolder()
'''
主要参数:
root:在root指定的路径下寻找图片
返回值:
dataset对象,但是这个对象有几个常用方法:
dataset.classes --- 根据文件夹名字返回值
dataset.class_to_idx --- 按照顺序将类别定义为索引
dataset.imgs --- 图片路径和标签,返回一个列表,里面为元组
'''
示例
from torchvision.dataset import ImageFloder
dataset = ImageFloder('./xxx/')
dataloader = DataLoader(dataset,batch_size=64,shuffle=True)
for image,label in dataloader:
xxxx
5.5 自带数据使用:
加载MNIST数据集
import torchvision
import torch
import torchvision.transforms as transforms
batch_size = 256
train_dataset = torchvision.datasets.MNIST(root='../../data',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.MNIST(root='../../data',
train=False,
transform=transforms.ToTensor())
# Data loader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
CIFAR-10
from torchvision import datasets
cifar10 = datasets.CIFAR10(root="C:\\cifar10_dataset", train=True, download=True)
'''
参数:
root: cifar10数据集存放目录
train: True,表示加载训练数据集,False,表示加载验证数据集
download: True,表示cifar10数据集在root指定的文件夹不存在时,会自动下载
'''
6. 模型训练和评估:
当你完成了模型的定义、构建、参数初始化、损失函数设定等操作后,就可以进行模型的训练。
模型训练方法很简单,大体套路为:
# 1. 设置模型状态
model.train()
# 2. 数据加载、梯度训练、模型训练、计算损失值、参数更新
train_loss = 0
for data, label in train_loader:
# 将数据放到GPU上
data, label = data.cuda(), label.cuda()
# 梯度清零
optimizer.zero_grad()
# 将数据送入模型中
output = model(data)
# 计算损失函数值
loss = criterion(label, output)
# 反向传播,更新参数
loss.backward()
optimizer.step()
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(train_loader.dataset)
7. 可视化:
7.1 torchinfo:
torchinfo可视化网络结构
首先,需要按照torchinfo模块
pip install torchinfo
其次,可以使用它来查看网络结构:
torchinfo.summary(model.input_size)
# model : 模型对象
# input_size : 输入大小
7.2 tensorboard:
tensorboard可视化训练
首先,需要安装tensorboard工具(也可以使用pytorch自带的tensorboard):
pip install tensorboardX
我们可以将TensorBoard看做一个记录员,它可以记录我们指定的数据,包括模型每一层的feature map,权重,以及训练loss等等。TensorBoard将记录下来的内容保存在一个用户指定的文件夹里,程序不断运行中TensorBoard会不断记录。记录下的内容可以通过网页的形式加以可视化。
首先,我们需要对它进行配置:
# 导入模块
from tensorboardX import SummaryWriter
# 指定保存的文件夹
writer = SummaryWriter(路径)
然后,使用它:
- 当我们创建了模型后,可以显示它的模型结构:
writer.add_graph(model, input_to_model = torch.rand(1, 3, 224, 224))
# input_to_model : 输入大小
writer.close()
- 也可以显示连续变量的图像
writer = SummaryWriter('./pytorch_tb')
for i in range(500):
x = i
y = x**2
writer.add_scalar("x", x, i) #日志中记录x在第step i 的值
writer.add_scalar("y", y, i) #日志中记录y在第step i 的值
writer.close()
# 上面的效果是两张图显示
最后,启动它:
tensorboard --logdir=/path/to/logs/ --port=xxxx
# /path/to/logs 中 path是保存的文件夹路径,需要修改,其它不用改
# --port : 是服务器使用的时候修改
7.3 举例:
实操中的心得:
- 一般可视化变量,都是可视化损失值,但是注意,损失值的索引(就是第三个参数),不能重复,一旦重复,就会重复
- 一般不指定路径,默认是在当前文件夹下创建一个名为runs的文件夹
- 可视化网络架构,需要给他一个输入,一般给batch_data 即可,见下面的代码
- 看可视化,需要调用cmd命令
- 具体的可视化结果,看下图
# 导包
import time
import torch
from torch import nn
from torch import optim
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
import torchvision.transforms as transforms
# 导入可视化
from tensorboardX import SummaryWriter
# 创建模型
class LeNet(nn.Module):
def __init__(self):
super(LeNet,self).__init__()
# 定义模型
self.features = nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=6,kernel_size=(5,5),stride=1,padding=2),
nn.Sigmoid(),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(in_channels=6,out_channels=16,kernel_size=(5,5),stride=1),
nn.Sigmoid(),
nn.MaxPool2d(kernel_size=2,stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(in_features=400, out_features=120),
nn.Sigmoid(),
nn.Linear(in_features=120, out_features=84),
nn.Sigmoid(),
nn.Linear(in_features=84, out_features=10)
)
def forward(self,x):
# 定义前向算法
x = self.features(x)
# print(x.shape)
x = torch.flatten(x,1)
# print(x.shape)
result = self.classifier(x)
return result
# 下载数据集或者加载数据集
train_dataset = MNIST(root='../data',train=True,transform=transforms.ToTensor(),download=True)
test_dataset = MNIST(root='../data',train=False,transform=transforms.ToTensor())
# 加载数据: 分批次,每批256个数据
batch_size = 32
train_loader = DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)
test_loader = DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=False)
# start time
start_time = time.time()
# 创建模型
model = LeNet()
# 模型放入GPU中
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 定义损失函数
loss_func = nn.CrossEntropyLoss()
loss_list = [] # 用来存储损失值
# 定义优化器
SGD = optim.Adam(params=model.parameters(),lr=0.001)
# 初始化可视化对象
writer = SummaryWriter() # 路径一般默认,不过也可以指定
# 训练指定次数
x = 0
for i in range(10):
loss_temp = 0 # 定义一个损失值,用来打印查看
# 其中j是迭代次数,data和label都是批量的,每批32个
for j,(batch_data,batch_label) in enumerate(train_loader):
# 启用GPU
batch_data,batch_label = batch_data.cuda(),batch_label.cuda()
# 清空梯度
SGD.zero_grad()
# 模型训练
prediction = model(batch_data)
# 计算损失
loss = loss_func(prediction,batch_label)
loss_temp += loss
# BP算法
loss.backward()
# 更新梯度
SGD.step()
if (j + 1) % 200 == 0:
print('第%d次训练,第%d批次,损失值: %.3f' % (i + 1, j + 1, loss_temp / 200))
# 可视化1:一般添加loss值
writer.add_scalar('200_step_loss',loss_temp / 200,x)
x += 1
loss_temp = 0
# end_time
end_time = time.time()
print('训练花了: %d s' % int((end_time-start_time)))
# 可视化2:模型结构
writer.add_graph(model,input_to_model=batch_data)
# 关闭可视化
writer.close()
来看看结果:



8. 调用GPU:
8.1 检测是否可以使用GPU:
检测代码:
import torch
# 检测是否可以使用GPU
print(torch.cuda.is_available())
8.2 查看GPU数量和名字:
代码:
# 查看GPU数量,索引号从0开始
print(torch.cuda.current_device())
# 根据索引号查看GPU名字
print(torch.cuda.get_device_name(0))
8.3 调用步骤:
核心步骤如下:
# 1.创建模型
model = Net()
# 2.定义device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 3.将模型加载到GPU(所定义的device)
model = model.to(device)
# 4.将输入和输出加载到GPU
inputs, target = inputs.to(device), target.to(device)
下面仔细说说怎么用:
- cuda:0 和cuda区别
device = torch.device('cuda')
device = torch.device('cuda:0')
'''
对于单卡计算机都一样,但是对于多卡来说,你要使用哪张GPU就需要指定了
当然,你也可以指定CPU,比如:device = torch.device('cpu')
'''
- 关于
to方法的一些注意点
# 1. 想要将一个张量放到GPU上,可以使用to方法,也可以使用cuda,看下面代码:
import torch
# 创建一个device
device = torch.device('cuda:0')
# 创建一个tensor
a = torch.randn((3,4)).to(device)
# 等价于 a = a.cuda(),同样返回新值
# 等价于torch.randn((3,4),device=device)
print(a.device) # cuda:0
# 注意: to()方法返回一个新值,而不是修改原来的a
**关于如何使用:**基本上就是先把模型放入GPU,再把数据放进GPU里面,其余的操作都是一样的。
比如伪代码:
# 创建模型
model = MyModel()
# 模型放入GPU
model = model.to(deivce)
# 训练
for image,label in train_loader:
image,label = image.to(device),label.to(device)
# 正常训练
9. torchvision模块:
9.1 transforms常用方法:
常用的方法:

另外,有一个类似于sequential的方法:
transforms.Compose([
# transforms.xxx
])
9.2 models常用方法:
torchvision中models库是一个包含了常见的经典网络的库,比如我们熟知的AlexNet、VGG、ResNet等等都有。
调用的方法很简单,首先知道网络名字,然后按照下面格式调用即可:
torchvision.models.alexnet
只是,相关的参数还需要自己去查文档。
另外,根据查看源码,可以知道调用这个方法和自己实现其实差不多的。
10. 模型保存与加载:
10.1 保存和加载整个模型:
# 保存和加载整个模型
torch.save(model_object, 'model.pkl')
model = torch.load('model.pkl')
10.2 保存和加载模型参数:
# 仅保存和加载模型参数(推荐使用)
torch.save(model_object.state_dict(), 'params.pkl')
model_object.load_state_dict(torch.load('params.pkl'))
说说怎么用:
- cuda:0 和cuda区别
device = torch.device('cuda')
device = torch.device('cuda:0')
'''
对于单卡计算机都一样,但是对于多卡来说,你要使用哪张GPU就需要指定了
当然,你也可以指定CPU,比如:device = torch.device('cpu')
'''
- 关于
to方法的一些注意点
# 1. 想要将一个张量放到GPU上,可以使用to方法,也可以使用cuda,看下面代码:
import torch
# 创建一个device
device = torch.device('cuda:0')
# 创建一个tensor
a = torch.randn((3,4)).to(device)
# 等价于 a = a.cuda(),同样返回新值
# 等价于torch.randn((3,4),device=device)
print(a.device) # cuda:0
# 注意: to()方法返回一个新值,而不是修改原来的a
**关于如何使用:**基本上就是先把模型放入GPU,再把数据放进GPU里面,其余的操作都是一样的。
比如伪代码:
# 创建模型
model = MyModel()
# 模型放入GPU
model = model.to(deivce)
# 训练
for image,label in train_loader:
image,label = image.to(device),label.to(device)
# 正常训练
9. torchvision模块:
9.1 transforms常用方法:
常用的方法:
[外链图片转存中…(img-CpvdHnXg-1690970949373)]
另外,有一个类似于sequential的方法:
transforms.Compose([
# transforms.xxx
])
9.2 models常用方法:
torchvision中models库是一个包含了常见的经典网络的库,比如我们熟知的AlexNet、VGG、ResNet等等都有。
调用的方法很简单,首先知道网络名字,然后按照下面格式调用即可:
torchvision.models.alexnet
只是,相关的参数还需要自己去查文档。
另外,根据查看源码,可以知道调用这个方法和自己实现其实差不多的。
10. 模型保存与加载:
10.1 保存和加载整个模型:
# 保存和加载整个模型
torch.save(model_object, 'model.pkl')
model = torch.load('model.pkl')
10.2 保存和加载模型参数:
# 仅保存和加载模型参数(推荐使用)
torch.save(model_object.state_dict(), 'params.pkl')
model_object.load_state_dict(torch.load('params.pkl'))