专题:哈希表
题目:有效的字母异位词
给定两个字符串
s和t,编写一个函数来判断t是否是s的字母异位词。例如 输入: s = "anagram", t = "nagaram" 输出: true
说明: 你可以假设字符串只包含小写字母。
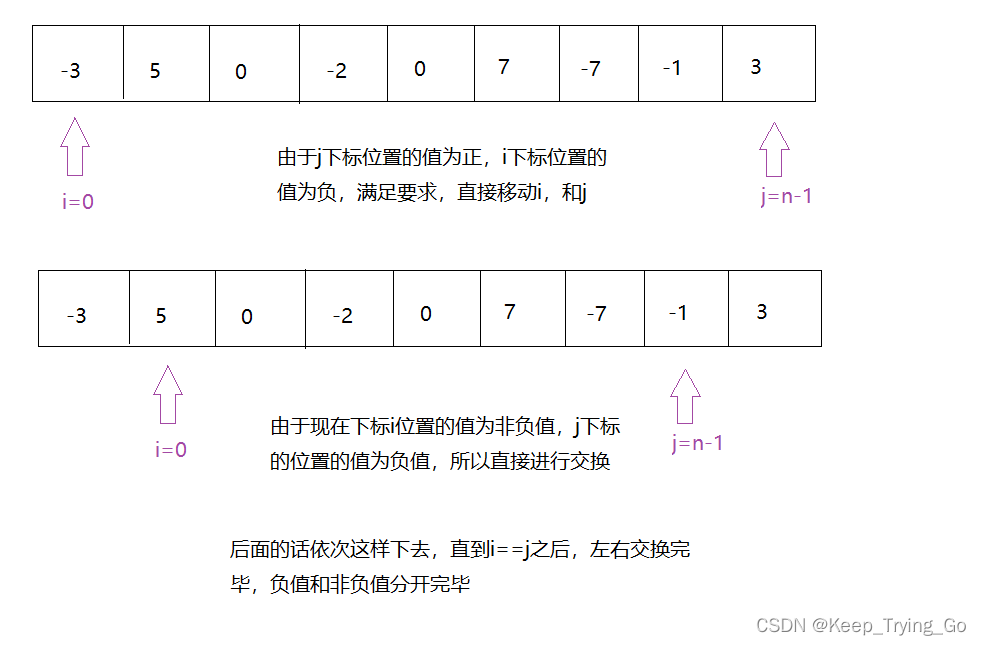
题目理解:因为只要小写字母,一共就26个,所以我们可以采用开辟一个大小是26的数组,充当哈希表,来记录元素的个数,很方便。我们可以先遍历数组s然后,它里面出现的元素减‘a’字符,两个字符的差就是一个整数,可以充当哈希表的下标,然后在对于 下标的位置执行++操作直到遍历完第一个数组;遍历第2个数组的时候,继续利用 数组元素减‘a’字符,差值充当哈希表的下标,对对应下标的元素执行--操作,直到循环完毕。 最后查看哈希表数组里面元素,如果有不等于0的元素,说明两个数组 不是有效字符异位词。
细节注意:数组哈希表,里面保存的是整形数字,而不是字符。int hush [26]={0};
哈希数组初始化为0,真的很很重要!!!!要不然后面没办法判断!
代码实现:
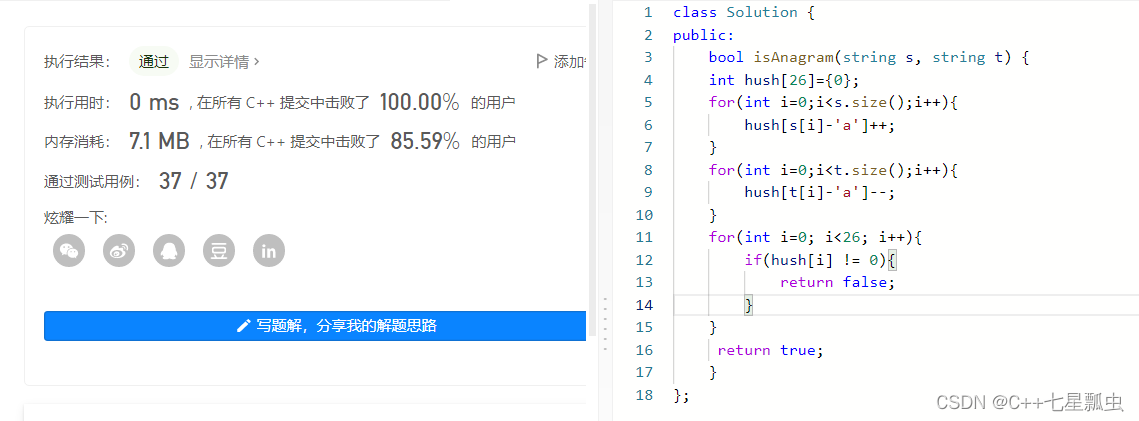
学到知识:把要处理的数据 和 哈希表的下标 产生联系,并且在要处理的数据 对应的哈希表的下标 处的元素执行++或--操作。哈希表核心:(在特定的位置,记录特定元素的个数)
题目:两个数组的交集
给定两个数组
nums1和nums2,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。输入:nums1 = [1,2,2,1], nums2 = [2,2] 输出:[2]
题目理解:因为数组可能特别大特别大(此时没有说明数组的大小时),而且要求结果去重 并且不考虑输出的顺序,此时我们就会考虑使用unordered_set。
注意点:
使用数组来做哈希的题目,是因为题目都限制了数值的大小。
而这道题目没有限制数值的大小,就无法使用数组来做哈希表了。
而且如果哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费。
细节注意:将数据插入unordered_set 里面,他就会自动去重,然后以数组形式输出的时候,需要vector<int>(set.begin(),set.end())进行输出。
代码实现:
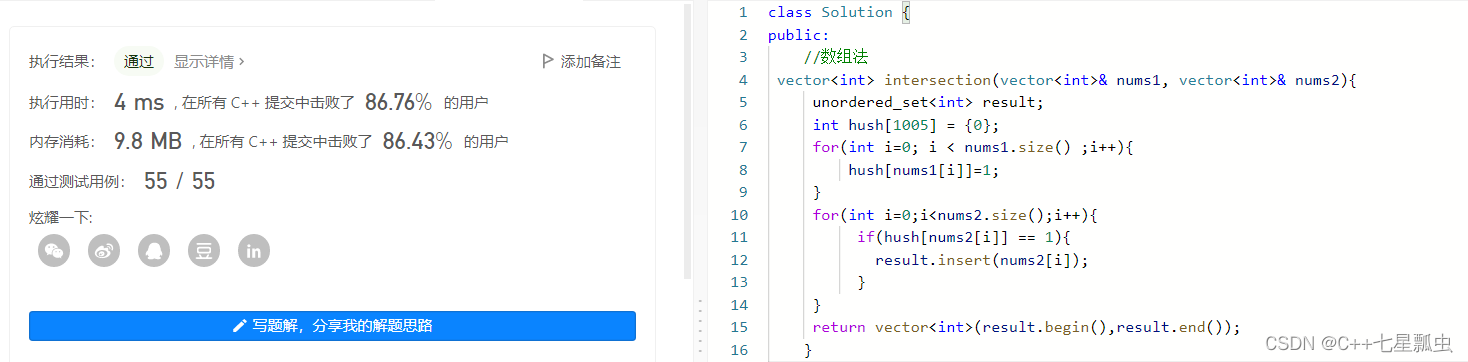
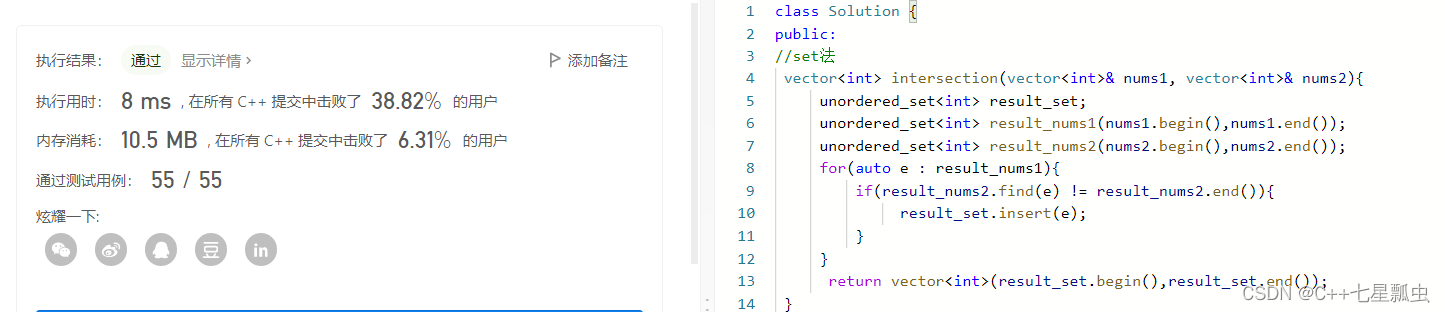
很多娃娃说:那么遇到哈希表问题,我直接使用unordered_set就好了啊,他能自动去重,还可以使用find()直接查找,多方便。但是问题就是,set它消费时间特别多,效率不高。一般情况,如果能使用数组的情况下,尽可能使用数组。
题目:快乐数
如果 n 是快乐数就返回 True ;不是,则返回 False 。
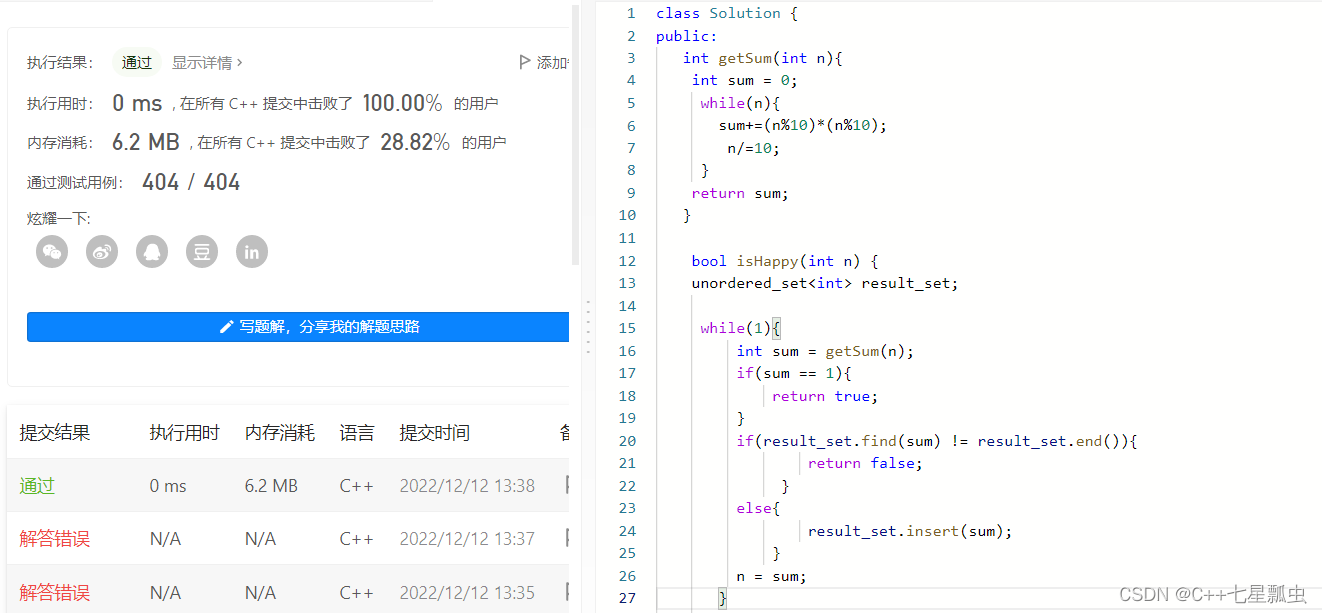
「快乐数」定义为:对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和,然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。如果 可以变为 1,那么这个数就是快乐数。
题目解析:核心就是,这个快乐数的计算过程中的结果有可能是一个循环。所以我们需要把每次的计算结果的值,保存在一个地方,然后每次得到新的值,就去判断,这个值是不是和以前计算的结果相同,相同说明就已经循环了,退出。不相同继续执行。我们就用unordered_set 保存 每次计算的结果。
细节注意: 就是这个getSum的思想。 isHappy 思想很简单,但是代码操作还要注意!!
题目:两数之和
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
例如:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
题目理解:给定一个数组,给定一个目标值,返回数组中和为目标值的两个数组元素的下标,有多对的时候,只返回第一次出现的元素下标。因为问题是,我遍历当前这个数组,然后每到一个元素,我就要判断我以前遍历过的数组元素里面,有没有和(目标值-当前元素)大小一样的值。如果有的话,返回当前元素 和 查找到的那个元素的 下标。如果没查到,就把当前的 数组元素值 和 元素下标 插入到 map里面(插入key值用来查找,vale用来记录元素对应的数组下标,需要一次插入两个数据,所以使用map)。
核心原理:就是只有一个数组,我们遍历这个数组,把遍历过的元素的值和下标,保存进map这个容器里面 map.insert(pair<int,int> key,vale)。然后遍历数组过程,每到一个元素,我就去遍历查找一下map,看里面有没有和(目标值-当前数组元素值)大小一样的值,如果有的话,就返回map里面那个key值对应的vale值,所以使用map.
细节注意:为啥使用哈希表?:因为我们要在遍历数组的时候,要将遍历过的元素的值和下标保存在一个容器里面,并且要去查找当前的元素对应(目标值-当前元素的值)是否在另一个容器里面出现过。
为啥使用使用map?:因为一次保存两个数组map<int,int>(key,vale);key用来查找,vale值用来赋值。
为啥选择unordered_map?:它的底层实现是哈希表,查找O(1),去重并且不要求有序;
代码实现:

总结:快乐学习,才能养成习惯,


![[附源码]JAVA毕业设计疫情期间高校师生外出请假管理系统录屏(系统+LW)](https://img-blog.csdnimg.cn/f0692fc748b54906bd9198b688bbb252.png)