爬虫学习建议:
在编写python爬虫程序时,只需要做以下两件事:
- 发送GET请求,获取HTML [第一类]
- 解析HTML,获取数据 [第二类]
-
这两件事,python都有相应的库帮你去做,你只需要知道如何去用它们就可以了。
爬虫目前涉及两种一是获取网页类的如urllib库,requests库,对网页进行获取,获取内容,保存,响应等。
二、解析网页内容:是网页中有很多内容,爬虫的本质是选择我需要的内容,例如我只想网页中的一部分图片,一部分视频或者一部分特殊的内容,这个选择的“部分”主要有1.正则表达式 2.xpath 3.BeautifulSoup 4.jsonparh 5.selenium
前期练习的时候,可以使用requests库+正则表达式 进行练习
后期使用的过程中,建议requests库+xpath库+Xpath Helper【浏览器工具】
工作中建议重点:requests库+xpath库+Xpath Helper【浏览器工具】+selenium结合使用
个人建议:
背景内容:
Python爬虫中Xpath的用法,相信每一个写爬虫、或者是做网页分析的人,都会因为在定位、获取XPath路径上花费大量的时间,在没有这些辅助工具的日子里,我们只能通过搜索HTML源代码,定位一些id,class属性去找到对应的位置,非常的麻烦,
一款插件Chrome中的一种爬虫网页解析工具:XPath Helper
XPath Helper插件是一款免费的Chrome爬虫网页解析工具,可以帮助用户解决在获取XPath路径时无法正常定位等问题安装了XPath Helper后就能轻松获取HTML元素的XPath,该插件主要能帮助我们在各类网站上查看的页面元素来提取查询其代码,同时我们还能对查询出来的代码进行编辑,而编辑出的结果将立即显示在旁边的结果框中,也很方便的帮助我们判断我们的XPath语句是否书写正确
1.Xpath Helper的安装【工具的安装】
在网上找到的下载地址,你可以根据实际情况进行下载
https://chrome.zzzmh.cn/info/hgimnogjllphhhkhlmebbmlgjoejdpjl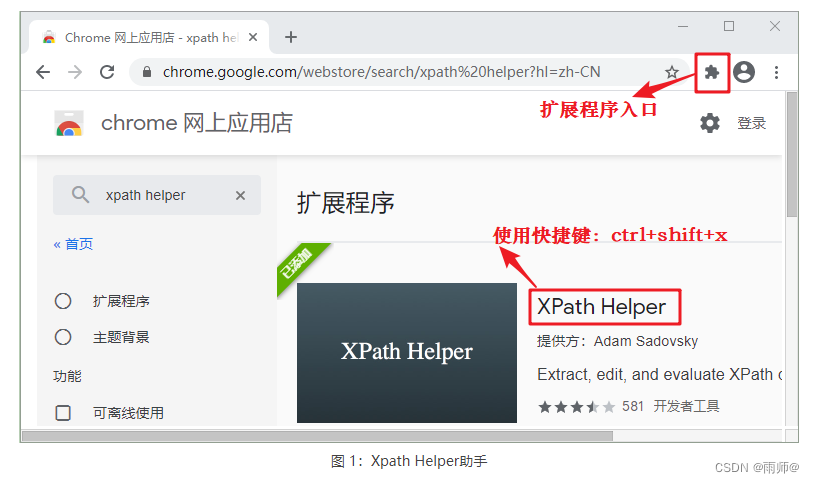
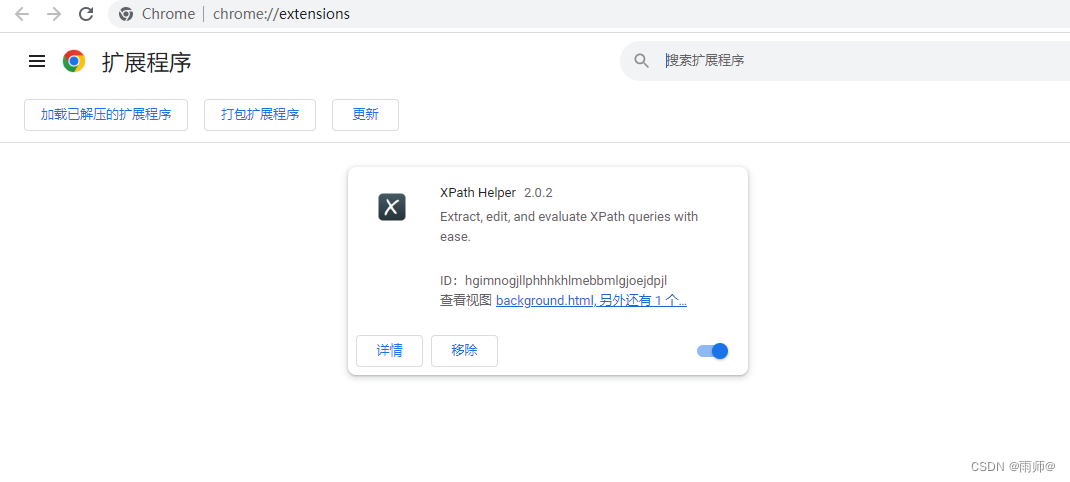
安装完毕后,在需要匹配数据的页面处,使用快捷键打开助手工具(快捷键:ctrl+shift+x)
2.Xpath Helper使用
涉及到的素材仅限于学习---仅限于学习---

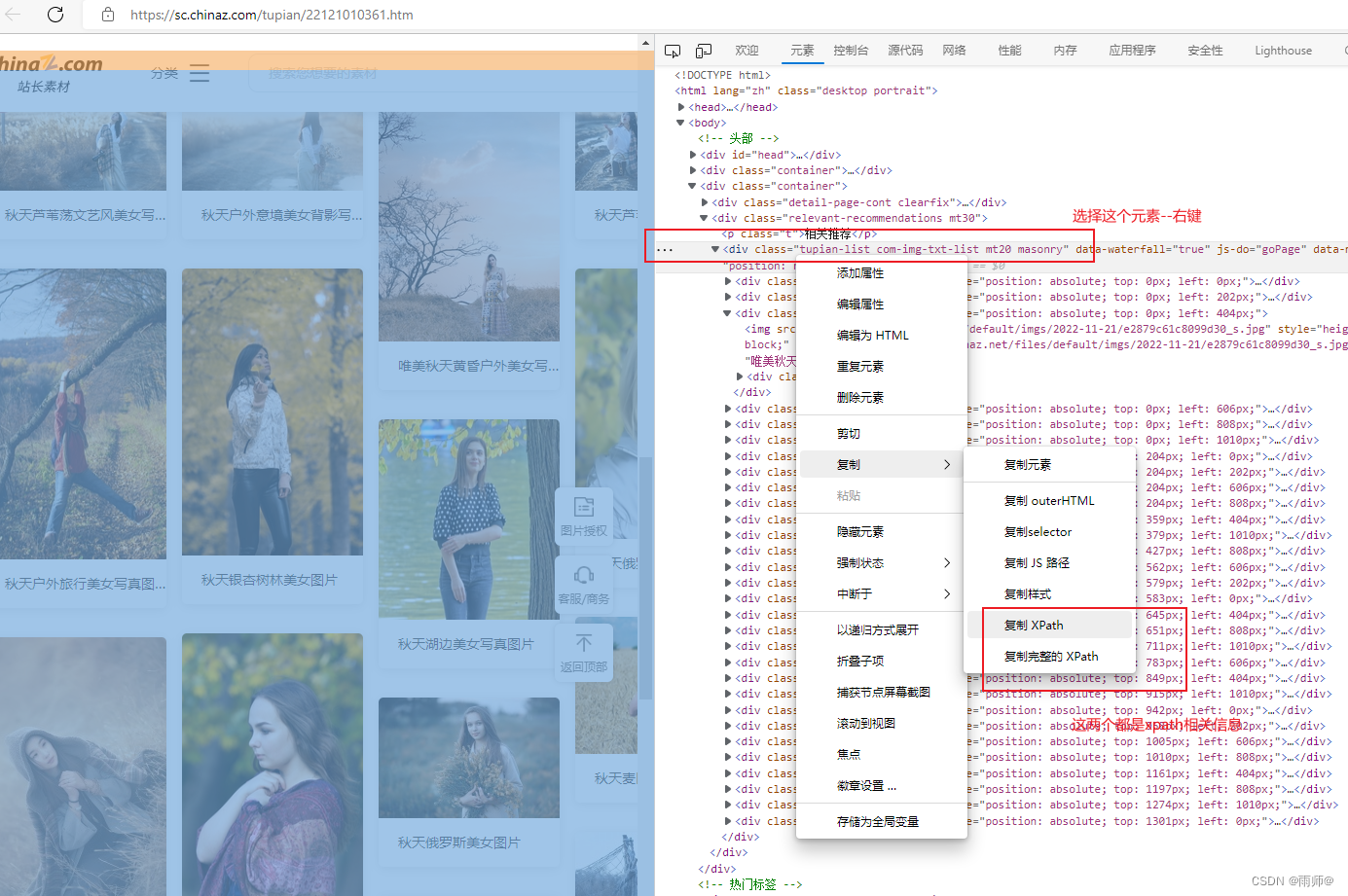
把刚刚复制的xpath内容复制到Xpath Helper工具中,观察结果
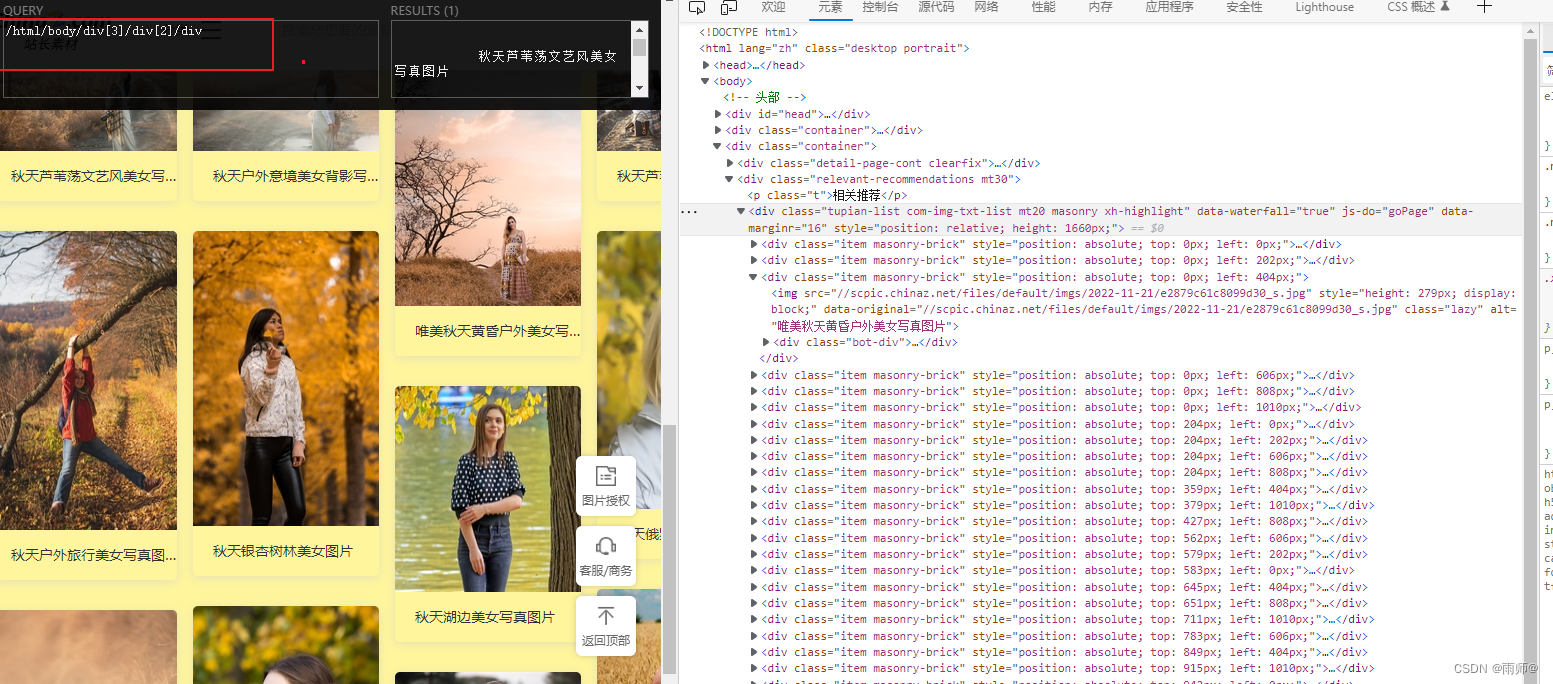
3.xpath的语法
XPath(XML Path Language - XML路径语言),它是一种用来确定XML文档中某部分位置的语言。
Xpath以XML为基础,提供用户在数据结构树中寻找节点的能力,Xpath被很多开发者亲切的称为小型查询语言。xpath可以使用路径表达式在XML上选取节点,从而达到确认元素的目的,我们先来介绍以下语法规则
语法规则:
| 表达式 | 作用 |
|---|---|
| nodename | 选取此层级节点下的所有子节点 |
| / | 代表从根节点进行选取 |
| // | 可以理解为匹配,就是在所有节点中选取此节点,直到匹配为止 |
| . | 选取当前节点 |
| … | 选取当前节点上一层(上一级目录) |
| @ | 选取属性(也是匹配) |
标签定位:
| 方式 | 效果 |
| /html/body/div | 表示从根节点开始寻找,标签与标签之间/表示一个层级 |
| /html//div | 表示多个层级 作用于两个标签之间(也可以理解为在html下进行匹配寻找标签div) |
| //div | 从任意节点开始寻找,也就是查找所有的div标签 |
| ./div | 表示从当前的标签开始寻找div |
属性定位
| 需求 | 格式 |
| 定位div中属性名为href,属性值为‘www.baidu.com’的div标签 | @属性名=属性值 |
| href为属性名 'www.baidu.com’为属性值 | /html/body/div[href=‘www.baidu.com’] |
索引定位
| 定位ul下第二个li标签(下图) | //ul/li[2] |
| 索引值开始位置为 | 1 |
取文本内容
| 方法 | 效果 |
| /text() | 获取标签下直系的标签内容 |
| //text() | 获取标签中所有的文本内容 |
| string() | 获取标签中所有的文本内容 |
4.python中使用
使用步骤:
1.安装lxml库
pip install lxml
2.导入lxml
from lxml import etree
3.解析文件
3.1解析本地文件(离线文件)
html_tee=etree.parse("xxx.html")
3.2解析网络文件 (互联网网址)
html_tee=etree.HTML(response.read().decode("utf-8"))
4.加载文件
html_tee.xpath(路径)






![[附源码]Python计算机毕业设计单位库房管理系统Django(程序+LW)](https://img-blog.csdnimg.cn/73a8e59a5ca64bba85ca8d0c1aae9fc3.png)