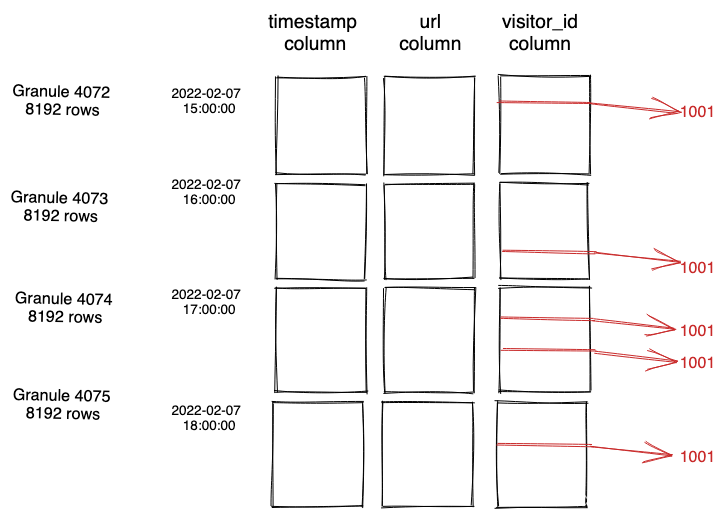
这一小章主要阐述下如何组织上述分析后的模型。
使用聚合(Aggergate)进行建模,并且在设计中结合工厂(Factory)和资源库(Repositiory,注意Orm映射出的持久化对象不是领域模型的范围,在后续章节中会详细阐述这两者的区别),这样就能够把生命周期做为一个原子单元进行模型对象的操作。
通常,Aggergate用于划分范围,这个范围内的模型元素在生命周期各个阶段都应维护其固定规则和事务一致性 。Factory和Repositiory在Aggergate基础上进行操作,将特定生命周期转换的复杂性封装起来。下图是一张整体构建思路:
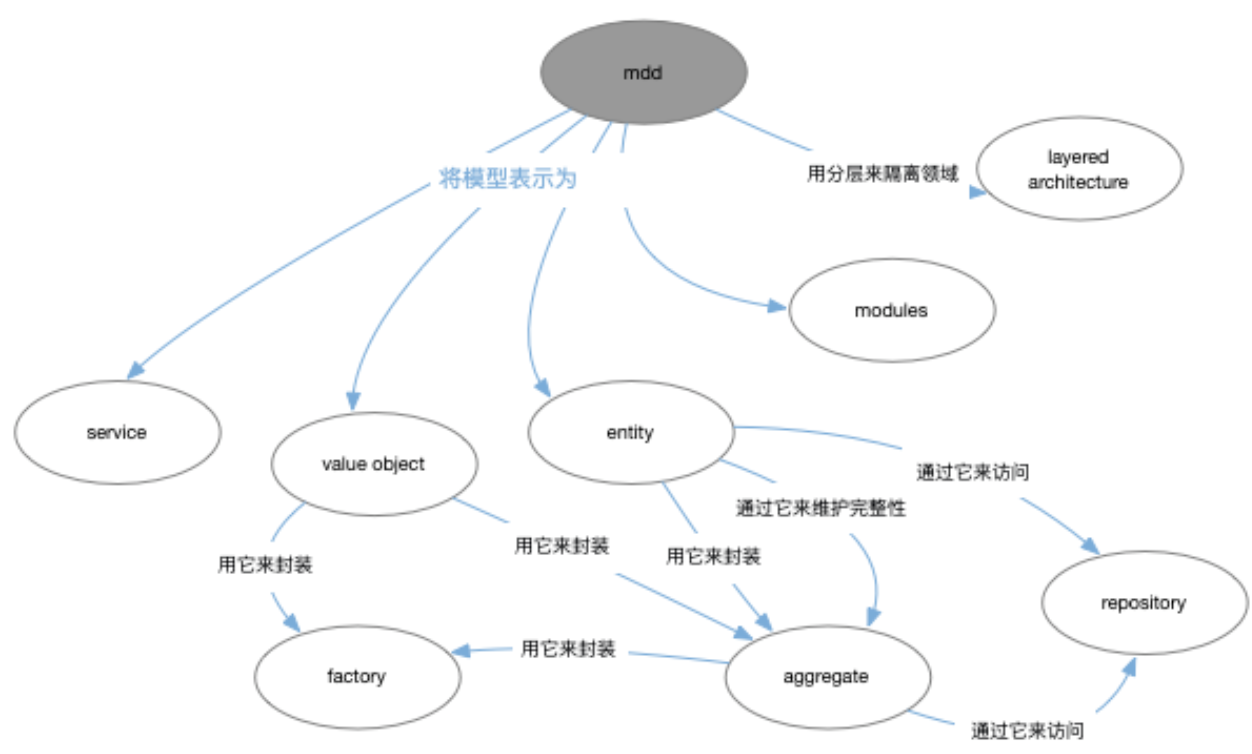
- 聚合Aggregate:定义清晰的关联项和边界
- 工厂Factory:创建和重建复杂对象,并用aggergate来封装其内部结构
- 资源库Repository:提供检索和持久化,可以委托给Factory来创建对象
一、聚合
聚合的识别和创建已在《快速开始-战术设计》章节详细描述过,此处不在累述,在本小节中笔者试图从概念角度讲述这个主题,希望可以加深读者对聚合的理想。首先需要强调的一点,在DDD中聚合是一个可选的模块,实现时需要在代码复杂性和是否应用聚合之间做出权衡。
聚合通过定义清晰的关系避免混乱和保持模型的高内聚。每个聚合都包含一个特定的根实体(聚合根)和边界(内部都有什么属性)。
- 对外引用:聚合根是唯一允许外部对象保持对聚合引用的对象,通过他来控制外界对内部成员的访问,不能根引用绕过它来修改内部对象。这种设计有利于维护业务规则的完整性,设计时尽量减少非必要的关联,有助于对象间的遍历和复杂性;
- 聚合内部:在聚合内部对象之间则可以相互引用,不同的对象可以有唯一的标识,但只有在内部才能区分开,对外部是不可见的。
1.1、创建聚合需遵循的原则
- 在聚合边界内保护业务规则不变性:由业务最终决定,技术处理上要保证事务的一致性;
- 聚合要设计的小巧:职责单一性,这是一个决策问题;
- 只能通过标识符引用其它聚合:出于容器的考虑,聚合间最好是外键引用,而不是实体引用,同时尽量消除冗余字段,这也是一个决策问题;
- 使用最终一致性更新其它聚合:避免复杂性,最常用的是异步和消息机制;
1.2、程序实现时的注意事项
1.2.1、创建行为
- 迪米特法则:强调了最小知识原则,任何对象的任何方法只能调用:1、对象本身;2、所传入的参数对象;3、它所创建的对象;4、自身包含的对象的方法;
- 告诉而非询问原则:客户端不应该先询问执行端再决定是否进行某种操作,这个询问应该由执行端来决定,它只需告诉客户端0和1即可;
1.2.2、并发控制
- 为聚合创建版本号,但一般没有必要,比较复杂。
1.2.3、避免依赖注入
- 这主要是出于性能考虑,不要在聚合中注意资源库和领域服务;可在调用聚合命令之前先查询此聚合命令执行的前置条件,然后再执行的方式来解决。如果需要其它引用,可把其它聚合以参数的方式传入到聚合中的方法中;
二、工厂
如果创建实体或聚合的过程过于复杂,在程序设计时有必要将创建职责剥离出来,然后分配给一个单独的对象为领域对象减负,该对象本身并不承担领域模型中的职责,但是依然是领域设计的一部分。由此对象提供一个创建对象的方法/接口,该接口封装了所有创建对象的复杂操作过程,一次性地创建整个聚合,并且确保它的不变条件得到满足。此过程还要做到用户无感知。
这个被剥离出来的对象就是工厂,概念上讲工厂不受限界上下文的约束;所以不建议创建单独的Factory类,最好的方式是在领域服务(受限界上下文限制)或聚合中添加工厂方法。另外工厂方法本身是可替换的,所以在工厂方法实现时不建议做防御编程以及任何业务规则 ,这个职责应该由各个领域模型来分担,但被创建对象的完整性检查应该由工厂负责。使用用工厂方法除了能保证安全性等,还能简化客户端调用。通用的工厂设计如下:
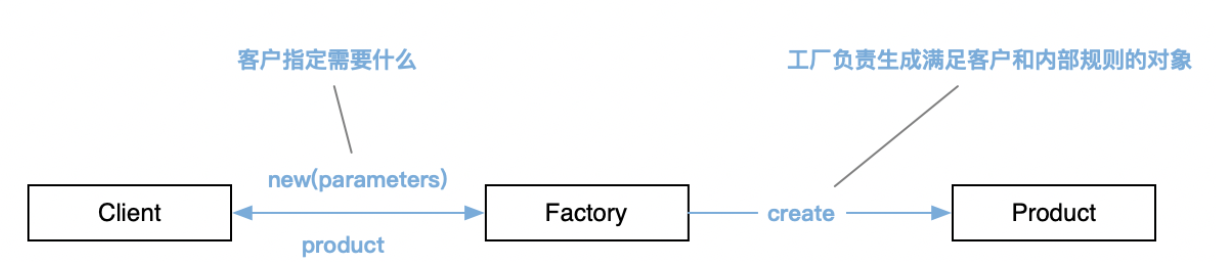
2.1、创建工厂方法的方式
这里说的工厂不是软件设计模式中的工厂模式,是一种概念其意义在于解耦,只要满足这个条件的实现都可以认为是工厂,工厂的实现需要满足两个条件:创建方法必须是原子的;创建的东西最好是具体的;工厂一般有三种创建方式:
- 工厂方法:
- 抽象工厂:
- 构建函数:
2.2、聚合中的工厂方法
一般适用于创建被引用的聚合,且创建过程中与其它上下文没有太多关系;下面是一个简单的示例,在Calendar聚合类中创建CaendarEntry聚合。但聚合里不建议访问领域服务;
public class Calendar extends EventSourcedRootEntity {
public CalendarEntry scheduleCalendarEntry(
CalendarIdentityService aCalendarIdentityService,
String aDescription,
String aLocation,
Owner anOwner,
TimeSpan aTimeSpan,
Repetition aRepetition,
Alarm anAlarm,
Set<Participant> anInvitees) {
CalendarEntry calendarEntry =
new CalendarEntry(
this.tenant(),
this.calendarId(),
aCalendarIdentityService.nextCalendarEntryId(),//不建议在工厂方法中访问领域服务
aDescription,
aLocation,
anOwner,
aTimeSpan,
aRepetition,
anAlarm,
anInvitees);
return calendarEntry;
}
}如果由于特殊原因需要要在聚合中访问service,则建议把上面的代码优化成如下方式。
public class Calendar extends EventSourcedRootEntity {
public CalendarEntry scheduleCalendarEntry(
CalendarIdentityService aCalendarIdentityService,
String aDescription,
String aLocation,
Owner anOwner,
TimeSpan aTimeSpan,
Repetition aRepetition,
Alarm anAlarm,
Set<Participant> anInvitees) {
CalendarEntry calendarEntry =
new CalendarEntry(
this.tenant(),
this.calendarId(),
getProductgetProduct(productId),//***
aDescription,
aLocation,
anOwner,
aTimeSpan,
aRepetition,
anAlarm,
anInvitees);
return calendarEntry;
}
public Product getProduct(Long productId){
return new AggregateService().getProduct(productId);
}
}2.3、领域服务中的工厂方法
适合创建顶层聚合或是创建过程中需要与其它上下文进行通信。最好的方式是在领域服务(受限定上下文限制)中使用工厂方法。顺理成章的也可以处理防腐层、发布语言、开放主机服务等相关内容。从是否使用工厂方法的维度来分,领域服务也可分为工厂和职能两大类。下面是一个简单的示例:
public class CalendarApplicationService {
private CalendarRepository calendarRepository;
private CalendarEntryRepository calendarEntryRepository;
private CalendarIdentityService calendarIdentityService;
private CollaboratorService collaboratorService;
public void scheduleCalendarEntry(
String aTenantId,
String aCalendarId,
String aDescription,
String aLocation,
String anOwnerId,
Date aTimeSpanBegins,
Date aTimeSpanEnds,
String aRepeatType,
Date aRepeatEndsOnDate,
String anAlarmType,
int anAlarmUnits,
Set<String> aParticipantsToInvite,
CalendarCommandResult aCalendarCommandResult) {
Tenant tenant = new Tenant(aTenantId);
Calendar calendar =
this.calendarRepository()
.calendarOfId(
tenant,
new CalendarId(aCalendarId));
CalendarEntry calendarEntry =
calendar.scheduleCalendarEntry(
this.calendarIdentityService(),
aDescription,
aLocation,
this.collaboratorService().ownerFrom(tenant, anOwnerId),
new TimeSpan(aTimeSpanBegins, aTimeSpanEnds),
new Repetition(RepeatType.valueOf(aRepeatType), aRepeatEndsOnDate),
new Alarm(AlarmUnitsType.valueOf(anAlarmType), anAlarmUnits),
this.inviteesFrom(tenant, aParticipantsToInvite));
this.calendarEntryRepository().save(calendarEntry);
aCalendarCommandResult.resultingCalendarId(aCalendarId);
aCalendarCommandResult.resultingCalendarEntryId(calendarEntry.calendarEntryId().id());
}
}三、资源库
资源库通常表示一个安全的存储区域,原则上只为聚合创建资源库,他们之间存在一对一的关系。在设计时要考虑如何向资源库中添加行为、层级资源库的设计、资源库与Dao在概念上的区别等;这只是一种设计原则,具体还是要根据软件的复杂度来评判。概念上资源库不是Dao,但在代码实现上又非常类似,所以资源库的设计实现往往是DDD实践过程中打破领域设计的最大风险。
另外在设计时简单的业务可能只需要简单的存储即可,即Dao可以直接使用领域对象,复杂的可能需要用到按聚合创建资源库这种设计模式。所以在建立资源库时有面向集合(collection-oriented)和面向持久化(persistence-oriented)两种设计方式。
在平衡性能与聚合的大小时,当不易通过遍历的方式来访问某些聚合的时候,就需要使用这资源库,所以资源库经常被设计成用来查找而不是更新。
3.1、资源库设计的注意事项
- 资源库是领域的概念;
- 不同的聚合有不同的资源库,两个或多个聚合位于同一个对象层级时可以共享同一个资源库
- 在第二条成立的前提下,比较合适选用适配器架构 ;
- 资源库的设计要体出可替换的原则,程序表现为资源库的接口定义在领域层,实现拿到基础层实现(注意与适配器架构的区别);
3.2、面向集合的资源库设计
一个资源库应该模拟一个SET集合。无论采用什么类型的持久化机制,我们都不应该允许多次添加同一个聚合实例。另外,当从资源库中获取到一个对象并对其进行修改时,我们并不需要重新保存此对象到资源库中。
在一个聚合中不应该存在一个显示的持久化接口调用,而应该用类似Hibernate那种会话机制实现隐式读时复制或隐式写时复制的方式。前者是读时创建一个副本当客户端提交时,对比这两个版本决定是否更新到DB中;后者是利用一个委托对象管理持久化对象,当持久化对象首次被调用时生成一个副本。
public interface GroupRepository {
public void add(Group aGroup);
public Collection<Group> allGroups(TenantId aTenantId);
public Group groupNamed(TenantId aTenantId, String aName);
public void remove(Group aGroup);
}public class HibernateGroupRepository
extends AbstractHibernateSession
implements GroupRepository {
public HibernateGroupRepository() {
super();
}
@Override
public void add(Group aGroup) {
try {
this.session().saveOrUpdate(aGroup);
} catch (ConstraintViolationException e) {
throw new IllegalStateException("Group is not unique.", e);
}
}
}3.3、面向持久化的资源库设计
如果持久化技术框架不支持对象变化的跟踪,无论是显式还是隐匿的,那么采用面向集全资源库便不合适了,此时最好采用基于操作的资源库—面向持久化的资源库,这是现阶段普遍采用的方式,实现技术多为mybatis。在向数据存储中添加新建对象或修改时,必须显示的调用save方法,
和面向集合的设计的一个区别就是,是否需要显示调用save方法。
3.4、资源库设计时的事务的管理
相对来说领域模型和领域层的操作比较细粒度,事务的管理应该是以粗粒度的方式放在应用层中比较合适,实现时可以硬编码也可以采用声明的方式,但是在分布式系统中,不建议过多的使用事务,而是采用最终一致性设计,示例如下:
public class AccessApplicationService {
@Autowired
private GroupRepository groupRepository;
@Autowired
private UserRepository userRepository;
public AccessApplicationService() {
super();
}
@Transactional
public void assignUserToRole(AssignUserToRoleCommand aCommand) {
//领域模型
TenantId tenantId = new TenantId(aCommand.getTenantId());
User user =
this.userRepository().userWithUsername(
tenantId,
aCommand.getUsername());
if (user != null) {
Role role = this.roleRepository().roleNamed(
tenantId,
aCommand.getRoleName());
if (role != null) {
role.assignUser(user);
}
}
}
@Transactional(readOnly=true)
public boolean isUserInRole(
String aTenantId,
String aUsername,
String aRoleName) {
User user = this.userInRole(aTenantId, aUsername, aRoleName);
return user != null;
}
}3.5、资源库VS数据访问对象(DAO)
虽然Dao和面向集合持久化的资源库在代码实现上有可能是是一样的,但一定要弄清它们之间的概念区别,因为它会影响我们的程序设计:
- Dao是针对数据的,它只是对DB的一层封装。而资源库更加面向对象;
- 资源库是领域模型的一部分,而Dao并不领域范畴内的东西;
- 以上定位会影响包结构的设计以及调用关系。比如Dao通常会把接口和实现单独管理,而资源库则会用领域层来管理资源库;
END,至此DDD中相关的概念和基础知识全部讲解了,后续笔者会侧重实践落地,分专题讲述下笔者在实践DDD中关于架构设计、考核、流程制定等相关的内容。