1总述
Zero Redundancy Optimizer: 提高了可以被有效训练的模型的大小,极大提高了模型训练的速度。
- 保持了较小的通信量
- 保持较高的计算粒度
数据并行DP
- 并没有减少每个device上的内存占用
- 当模型有1.4B 参数时,就会超过GPU的32GB显存
- 通过PP, MP, CPU-offload 方式解决,降低了功能性,可用性和计算效率
模型并行MP
- 垂直切分模型,将每一层上的计算和参数分到多个设备上
- 在同一个work node之内,带宽较高,可以使用MP,但是如果跨界点,MP的效率将大大降低
大模型中的内存占用
-
model states :
- optimizer states:比如Adam 算法中的动量和方差
- 梯度
- 参数
-
residual states:
- 激活值
- 临时的buffer
- 没有利用的内存碎片
优化Model states Memory
- Model states 占用了训练过程中的最多内存。
- 使用DP会在多个设备上存在整个model states的拷贝
- MP 将model states在各个设备上进行切分,但是计算粒度很细,通信量很大。
这些方法都在整个训练过程中,静态维持着 model states, 相反ZeRO将model states切分,在有些设备上丢弃掉不属于自己的model states
ZeRO-DP: 实现和数据并行一样的通信量,和模型并行一样的内存效率。
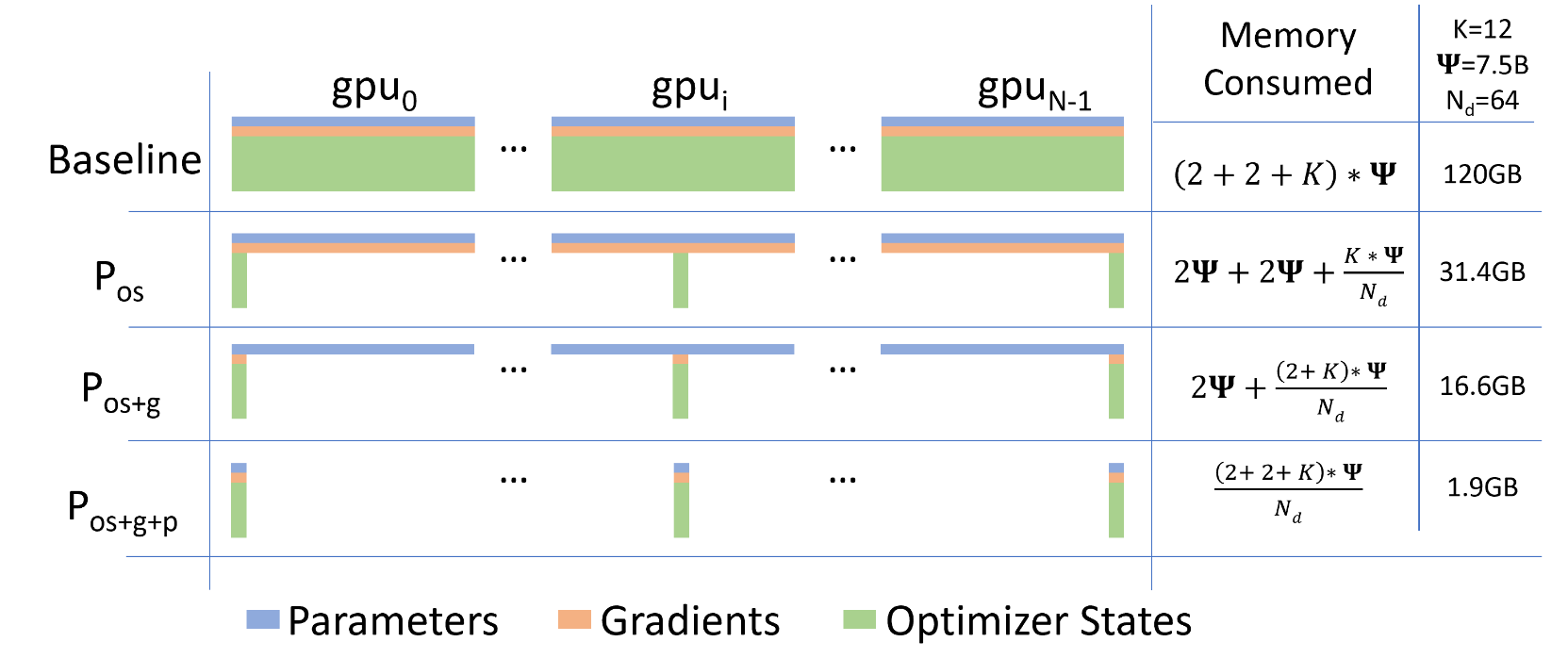
ZeRO-DP 有三种主要策略, 这三种策略逐层开启:
- Optimizer State Partition: 将内存消耗减少4倍, 通信量保持不变
- Gradiant Partition: 将内存消耗减少8倍,保持通信量不变
- Parameter Partition: 内存消耗按照 DP的并行度线性缩减。通信量将变成原先的1.5倍
优化 Residual States Memory
ZeRO-R
- 需要存储激活值,以便于反向传播的计算。使用检查点对于大模型来说还不够用。将激活值进行划分,以去除MP方法中的重复激活值。( 这里还是有点不太懂,最好还是能深入看一下模型并行的细节)
- 将临时 buffer 固定到合适的大小,在内存占用和计算效率之间实现balance
- 由于有的数据memory的生命周期较长,比如参数所占用的内存。但是中间结果占用内存的生命周期短。这种不同生命周期的内存相互交错会造成内存的碎片化。因此,在内存中预先开辟指定大小的内存,用于长生命周期的内存分配。此外,这样做也减少了在分配内存时,硬件查找空余内存的时间。
使用ZeRO-DP的方式,我们可以在通用GPU上容纳较大的模型,因此不需要MP对模型进行切分。并且,使用DP的方式,不切分模型也更加简单。
但是有些情况下,我们还是要使用MP,我们将ZeRO-DP与MP结合起来一起使用:
- 当模型较大时,单使用DP还是在一个GPU上不能容纳整个模型
- 如果使用单纯使用DP,DP并行度较高,每个GPU上都会计算一个mini-batch,这样会导致融合成的batch-size较大,较大的batch-size会使得收敛较为困难。
使用ZeRO和MP相结合,理论上可以将内存占用缩减 N d × N m N_d\times N_m Nd×Nm 倍
2相关工作
减少内存的非并行方法
减少激活值的内存占用
- compression
- activation checkpointing
- live analysis
CPU Offload
将model states 转移到PCU的内存上。
在ZeRO-R中,可以将激活值的检查点转移到CPU内存中。
训练的优化器 Optimizers
由于ZeRO可以减少,内存的占用,因此节省下来的内存还支持添加其他的optimizers
3 内存消耗状况分析
Model States 内存消耗
Model states消耗了大部分内存。
考虑Adam optimizer,Adam 需要保存
- the time averaged momentum
- variance of the gradients to compute the updates.
optimizer states通常消耗了大部分内存,尤其是在混合精度训练的情况下。
- the mixed-precision optimizer keeps an fp32 copy of the parameters as well as an fp32 copy of all the other optimizer states.
- 此外Adam 还有一部分fp16的参数和梯度cppy
这里占用了大部分内存,但是只有当反向传播结束后,这里的参数才需要更新。
Residual Memory消耗
- 激活值 1000亿个参数的模型,bitch-size32 ,即使使用了检查点 激活值也需要消耗60G内存。
- 临时buffer
- 内存碎片:
4 ZeRO: Insights and Overview
ZeRO的前提是,要保证效率。
ZeRO powered DP is based on three key insights:
- DP比MP拓展更加高效,是因为DP的计算粒度更大。MP的计算粒度更小。
- DP内存消耗高,相反MP将model states进行划分获得更高的内存效率
- DP MP都在训练过程中一直维护着model states
ZeRO-DP 在多个设备间将model states进行划分,每个设备上没有重复的参数。
在训练过程中,进行动态的通信,减少通信量。
减少激活值内存:
- MP 可以划分model states 但是经常会造成激活值内存的重复。 比如,如果我们将参数层纵向切分到两个GPU上,每个GPU上都需要完整的激活值输入才能进行计算,这就造成了激活值的重复。
- 对于计算强度非常大的模型,可以掩盖激活值检查点数据移动的开销
管理临时buffer
ZeRO-R使用固定大小的buffer。避免在计算过程中临时buffer使用量爆炸
管理内存碎片
- 检查点激活值的内存周期较长,普通激活值会重计算内存周期短。
- 激活值的梯度内存周期短,参数的梯度内存周期长
将检查点激活值和参数梯度移动到预先分配好的连续内存中,避免内存碎片。
5 Deep Dive into ZeRO-DP

Optimizer State Partitioning
如果使用Adam之类的算法,并且由混合精度计算等过程,就需要有一大部分内存用于存储Adam算法所需要的变量。
如果每个设备都在运用Adam算法更新后,还保留了 optimizer的参数,这就造成了参数重复。
将Adam参数分程
N
d
N_d
Nd 等分,每个设备上保留一份。每个设备上需要维护的 optimizer state大小变为原先的
1
N
d
\frac{1}{N_d}
Nd1
当需要相应的参数进行Adam 算法时,使用 all-gather.
Gradient Partitioning
在反向传播过程中,先将参数广播到各个设备上。根据参数,检查点激活值,上游梯度,计算各个设备计算上的参数梯度。将参数梯度进行reduce,结果保留到对应的设备上,其他设备丢弃参数梯度。
Parameter Partitioning
将参数进行划分,当前向或者反向传播中使用到对应参数时,将参数broadcast
6 Deep Dive into ZeRO-R
Pa Partitioned Activation Checkpointing
当使用MP时,将激活值的检查点进行划分。当再反向传播需要使用激活值时,将使用 all-gather使得每个设备上都有完整的激活值检查点。
同时还可以使用CPU-offload技术。
Cb Constant Size Buffers
输入 越大,计算效率越高。
需要在内存和计算效率之间寻求平衡。
MD: Memory Defragmentation
预先分配连续的内存区域,用于长周期内存。
7 Communication Analysis of ZeRO-DP
-
当使用Pos、Pg时,ZeRO-DP没有引入任何额外的通信量
-
当使用Pos、Pg还使用Pp时,ZeRO-DP的通信量是原先的1.5倍