文章目录
- 一、Pytorch简介
- 二、安装
- 2.1 安装GPU环境
- 2.2 安装Pytorch
- 2.3 测试
- 三、Tensor
- 3.1 Tensor创建
- 3.1.1 torch.tensor() && torch.tensor([])
- 3.1.2 torch.randn && torch.randperm
- 3.1.3 torch.range(begin,end,step)
- 3.1.4 指定numpy
- 3.2 Tensor运算
- 3.2.1 A.add() && A.add_()
- 3.2.2 torch.stack
- 四、CUDA
- 五、其他技巧
- 5.1 自动微分
- 5.1.1 backward求导
- 5.1.2 autograd.grad求导
- 5.2 求最小值
- 5.3 Pytorch层次结构
- 六、数据
- 6.1 Dataset and DataLoader
- 6.2 数据读取与预处理
- 6.3 Pytorch数据处理工具
- 七、torch.nn
- 八、模型保存
- 8.1 状态字典state_dict
- 8.2 加载/保存状态字典(state_dict)
- 8.3 加载/保存整个模型
- 参考
一、Pytorch简介
Torch是一个经典的对多维矩阵数据进行操作的张量( tensor ) 库。
Pytorch的计算图是动态的,可以根据计算需要实时改变计算图。
二、安装
2.1 安装GPU环境
conda环境、CUDA环境和 CUDNN环境
2.2 安装Pytorch
https://pytorch.org/
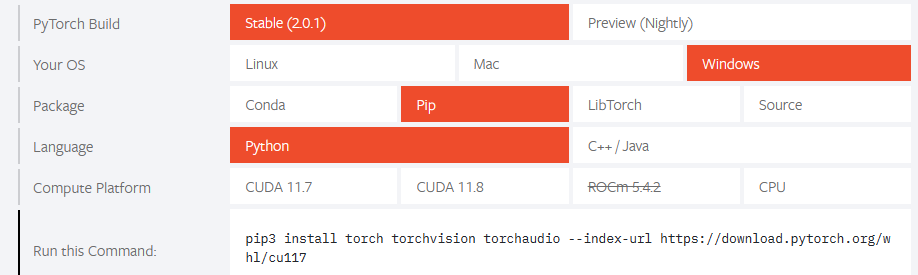
官网会自动显示符合电脑配置的Pytorch版本
2.3 测试
import torch
print(torch.__version__) # pytorch版本
print(torch.version.cuda) # cuda版本
print(torch.cuda.is_available()) # 查看cuda是否可用

这里使用的是CPU版本
三、Tensor
Tensor张量是Pytorch里最基本的数据结构,是一个多维矩阵。
基本数据类型

3.1 Tensor创建
- 全0
torch.zeros(3,3) - 全1
torch.ones(3,3) - 单位矩阵
torch.eye(3,3) - 基础
torch.Tensor([1,3]) # 将序列[1,3]转换为tensor - 指定数据类型
torch.IntTensor([1,2]) - 随机数
torch.randn(3,3) - n数字随机排序
torch.randperm(n) - 根据A的尺寸创建
A.new_ones(size=B.size())
3.1.1 torch.tensor() && torch.tensor([])
主要区别在于创建的对象的size和value不同
torch.Tensor(2,3) # 2行3列
torch.Tensor([2,3]) # 将列表[2,3]转换为tensor
3.1.2 torch.randn && torch.randperm
torch.randn生成的数据类型为浮点型,生成的数据取值满足均值为0,方差为1的正态分布。
torch.randn(2,3)
torch.randperm(n)创建一个n个整数,随机排列的Tensor
torch.randperm(10)
3.1.3 torch.range(begin,end,step)
生成一个一维的Tensor,三个参数分别为起始位置,终止位置和步长。
torch.range(1,10,2)
# tensor([1.,3.,5.,7.,9.])
3.1.4 指定numpy
需要创建指定的Tensor,可以使用numpy
torch.tensor(np.arange(15).reshape(3,5))
3.2 Tensor运算
- torch.abs(A)
绝对值 - torch.add(A,B)
相加,A和B既可以是Tensor也可以是标量 - torch.clamp(A,max,min)
裁剪,A中的数据如果小于min或者大于max,则变成min或者max,保证范围在[min,max] - torch.div(A,B)
相除,A/B, A和B既可以是Tensor也可以是标量 - torch.mul(A,B)
点乘,A*B, A和B既可以是Tensor也可以是标量 - torch.pow(A,n)
求幂, A的n次方 - torch.mm(A,B.T)
矩阵叉乘 - torch.mv(A,B)
矩阵与向量相乘,A是矩阵,B是向量,这里的B需不需要转置都是可以的 - A.item()
将Tensor转换为基本数据类型,Tensor中只有一个元素的时候才可以使用,一般用于在Tensor中取出数值。 - A.numpy()
将Tensor转换成Numpy类型 - A.size()
查看尺寸 - A.shape()
查看尺寸 - A.dtype()
查看数据类型 - A.view()
重构张量尺寸,类似于Numpy中的reshape - A.transpose(0,1)
行列交换 - A[1:] && A[-1,-1] = 100
切片,类似Numpy中的操作 - A.zero_()
归零化 - torch.stack((A,B),sim=-1)
拼接升维 - torch.diag(A)
对A对角线元素形成一个一维向量 - torch.diag_embed(A)
将一维向量放到对角线上,其余数值为0的Tensor - torch.unsqueeze()
- torch.squeeze()
3.2.1 A.add() && A.add_()
所有带_符号的操作都会对原数据进行修改
b.add(1)
b.add_(1)
3.2.2 torch.stack
stack为拼接函数,函数第一个参数为需要拼接的Tensor, 第二个参数为分到哪个维度
C1 = torch.stack((A,B).dim=0) # -1 默认是按最后一个维度
四、CUDA
CUDA是一种操作GPU的软件架构,Pytorch配合GPU环境,模型的训练速度会大大加快。
import torch
# 测试GPU环境是否可用
print(torch.__version__) # pytorch版本
print(torch.version.cuda) # cuda版本
print(torch.cuda.is_available()) # 查看cuda是否可用
# 使用GPU or CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 判断某个对象是在什么环境中运行的
a.device
# 将对象的环境设置为device环境
A = A.to(device)
# 将对象环境设置为CPU
A.cpu().device
# 若一个没有环境的对象与另一个有环境A的对象进行交互,则环境全变为环境A
a + b.to(device)
# cuda环境下tensor不能直接转换为numpy类型,必须要先转换成CPU环境中
a.cpu().numpy()
# 创建CUDA型的tensor
torch.tensor([1,2],device)
五、其他技巧
5.1 自动微分
神经网络依赖反向传播求梯度来更新网络的参数。
在Pytorch中,提供了两种求梯度的方式
- backward,将求得的结果保存在自变量的grad属性中
- torch.autograd.grad
5.1.1 backward求导
使用backward进行求导,针对两种对象:标量Tensor和非标量Tensor求导。
两者的主要区别在于非标量Tensor求导加了一个gradient的Tensor, 其尺寸与自变量X的尺寸一致,在求完导后,需要与gradient进行点积,只是一般的求导的话,设置的gradient的Tensor元素值全部为1。
import numpu as np
import torch
# 标量Tensor求导
# 求f(x) = a*x**2 + b*x + c 的导数
x = torch.tensor(-2.0,requires_grad=True) # 需要添加requires_grad
a = torch.tensor(1.0)
b = torch.tensor(2.0)
c = torch.tensor(3.0)
y = a * torch.pow(x,2) + b*x +c
y.backward() # backward求得的梯度会存储在自变量x的grad属性中
dy_dx = x.grad
# 非标量Tensor求导
# 求f(x) = a*x**2 + b*x + c 的导数
x = torch.tensor([[-2.0,-1.0],[0.0,1.0]],requires_grad=True)
a = torch.tensor(1.0)
b = torch.tensor(2.0)
c = torch.tensor(3.0)
gradient = torch.tensor([[1.0,1.0],[1.0,1.0]])
y = a * torch.pow(x,2) + b*x +c
y.backward(gradient = gradient) # backward求得的梯度会存储在自变量x的grad属性中
dy_dx = x.grad
# 使用标量求导方式解决非标量求导
# 求f(x) = a*x**2 + b*x + c 的导数
x = torch.tensor([[-2.0,-1.0],[0.0,1.0]],requires_grad=True)
a = torch.tensor(1.0)
b = torch.tensor(2.0)
c = torch.tensor(3.0)
gradient = torch.tensor([[1.0,1.0],[1.0,1.0]])
y = a * torch.pow(x,2) + b*x +c
z = torch.sum(y*gradient)
z.backward()
dy_dx = x.grad
5.1.2 autograd.grad求导
import torch
# 单个自变量求导
# 求f(x) = a*x**4 + b*x + c的导数
x = torch.tensor(1.0,requires_grad=True)
a = torch.tensor(1.0)
b = torch.tensor(2.0)
c = torch.tensor(3.0)
y = a * torch.pow(x,4) + b*x + c
# create_graph设置为True,允许创建更高阶的导数
# 求一阶导
dy_dx = torch.autograd.grad(y,x,create_graph=True)[0]
# 求二阶导
dy2_dx2 = torch.autograd.grad(dy_dx ,x,create_graph=True)[0]
# 求三阶导
dy_dx3 = torch.autograd.grad(dy2_dx2 ,x)[0] # 不再求更高阶导
# 多个自变量求偏导
x1 = torch.tensor(1.0,requires_grad=True)
x2 = torch.tensor(2.0,requires_grad=True)
y1 = x1 * x2
y2 = x1 + x2
# 只有一个因变量,正常求偏导
dy1_dx1,dy1_dx2 = torch.autograd(outputs=y1,inputs=[x1,x2],retain_graph=True)
# 若有多个因变量,则对于每个因变量,会将求偏导的结果加起来
dy1_dx,dy2_dx = torch.autograd.grad(outputs=[y1,y2],inputs=[x1,x2])
5.2 求最小值
使用自动微分机制配套使用SGD随机梯度下降来求最小值。
# 利用自动微分和优化器求最小值
import numpy as np
import torch
# f(x) = a*x**2 + b*x + c 的最小值
x = torch.tensor(0.0,requires_grad=True) # x需要被求导
a = torch.tensor(1.0)
b = torch.tensor(-2.0)
c = torch.tensor(1.0)
optimizer = torch.optim.SGD(params=[x],lr=0.01) # SGD为随机梯度下降,lr学习率
def f(x):
result = a*torch.pow(x,2) + b*x +c
return result
for i in range(500):
optimizer.zero_grad() # 将模型的参数初始化为0
y = f(x)
y.backward() # 反向传播计算梯度
optimizer.step() # 更新所有的参数
print("y=",y.data,"->","x=",x.data)
5.3 Pytorch层次结构
Pytorch一共有5个不同的层次结构,分别为硬件层、内核层、低阶API、中阶API和高阶API(torchkeras)。
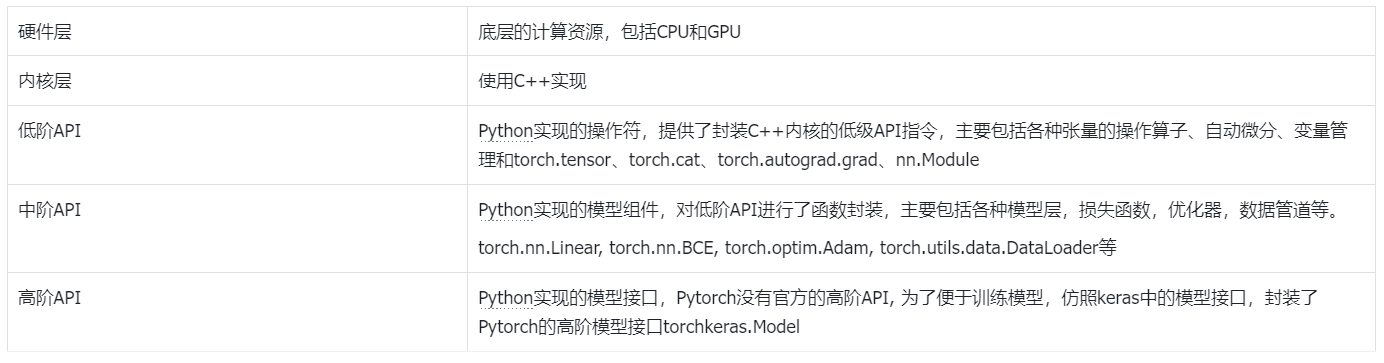
六、数据
Pytorch 通过Dataset和DataLoader进行构建数据管道。
6.1 Dataset and DataLoader
- DataSet 一个数据集抽象类,所有自定义的Dataset都需要继承它,并且重写__getitem__()或者__get_sample__()这个类方法
- DataLoader 一个可迭代的数据装载器。在训练的时候,每个for循环迭代,就从DataLoader中获取一个batch_size大小的数据。
6.2 数据读取与预处理
DataLoader的参数
DataLoader(
dataset, # 数据集,数据从哪里来,以及如何读取 【需要关注】
batch_size=1, # 批次大小,默认1 【需要关注】
shuffle=False, # 每个epoch是否乱序 【需要关注】
sampler=None, # 样本采样函数,一般无需设置
batch_sampler=None, # 批次采样函数,一般无需设置
num_workers=0, # 使用多进程读取数据,设置的进程数 【需要关注】
collate_fn=None, # 整理一个批次数据的函数
pin_memory=False, # 是否设置为锁业内存。默认为False,锁业内存不会使用虚拟内存,
# 从锁业内存拷贝到GPU上速度会更快
drop_last = False, # 是否丢弃最后一个样本数量不足的batch_size批次数据 【需要关注】
timeout=0, # 加载一个批次数据的最长等待时间,一般无需设置
worker_init_fn=None, # 每个worker中的dataset的初始化函数,常用于IterableDataset,
# 一般不使用
multiprocessing_context=None,
);
Epoch、Iteration、Batchsize的关系

数据读取的主要流程
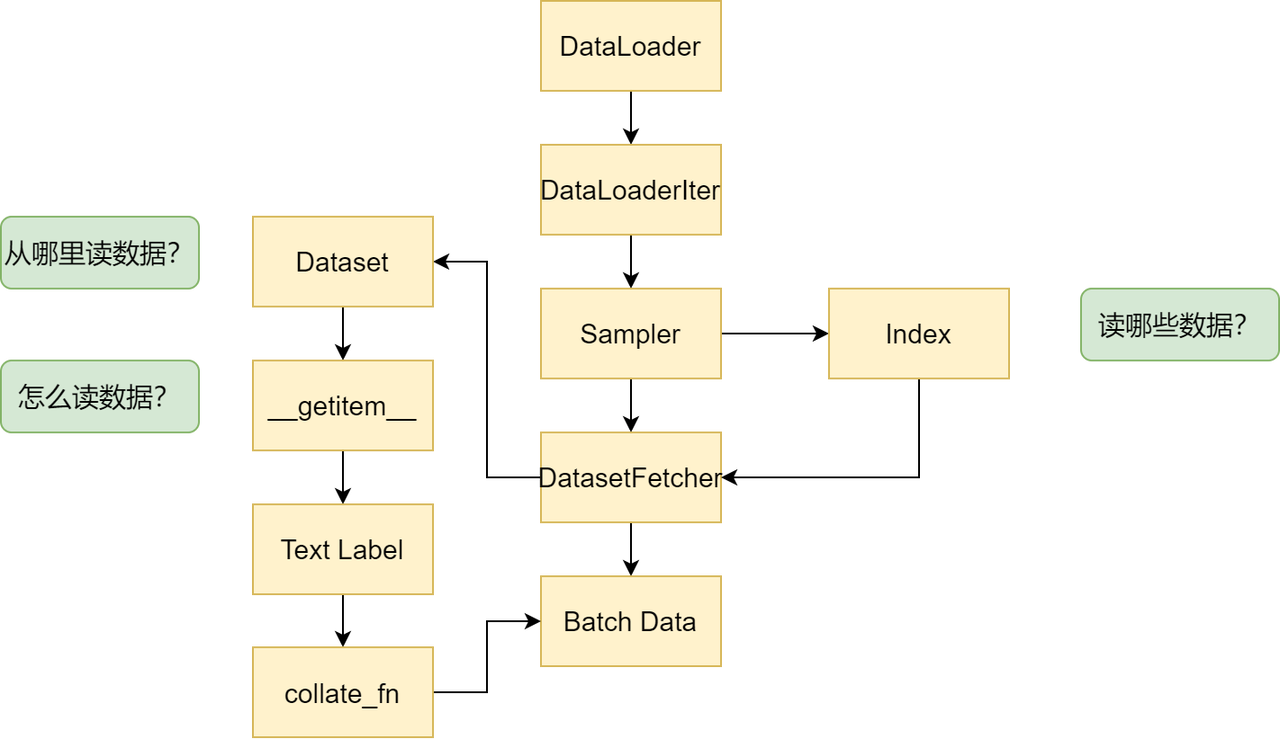
- 从DataLoader开始
- 进入DataLoaderIter,判断单线程还是多线程
- 进入Sampler进行采样,获得一批一批的索引,这些索引表示需要读取的数据
- 进入DatasetFetcher, 依据索引读取数据
- Dataset获知数据的地址
- 自定义的Dataset中会重写__getitem__()方法,针对不同的数据来进行定制化的数据读取
- 获取到数据的Text和Label
- 进入collate_fn将之前获取的个体数据进行组合成为batch
- 一个一个batch组成Batch Data
import torch
from torch.utils.data import DataLoader
from torch.utils.data.dataset import TensorDataset
# 自构建数据集
data = torch.arange(1,40)
dataset = TensorDataset(data)
dl = DataLoader(dataset,
batch_size = 10,
shuffle= True,
num_workers = 0, # 使用多进程加速报错,这里设置为0
drop_last = True)
# 数据输出
for batch in dl:
print(batch)
自定义数据集只有39条,最后一个batch的数据量小于10,被舍弃了

数据预处理主要是重写Dataset和DataLoader中的方法,实现定制化处理。
6.3 Pytorch数据处理工具
基于Pytorch已经产生了很多封装完备的工具。( 但是数据处理不是很灵活 )
七、torch.nn
torch.nn是神经网络工具箱,该工具箱建立于Autograd( 主要有自动求导和梯度反向传播功能 ),提供了网络搭建的模组、优化器等一系列功能。
搭建神经网络模型的整个流程
- 数据读取
- 定义模型
- 定义损失函数和优化器
- 模型训练
- 获取训练结果
一个FNN网络的例子(FNN每一层是全连接层)
https://blog.csdn.net/cxy2002cxy/article/details/124771834
import numpy as np
import torch
import matplotlib.pyplot as plt
from torch.utils.data import Dataset,DataLoader
# prepare the dataset
class DiabetesDataset(Dataset):
# load dataset
def __init__(self,filepath):
xy = np.loadtxt(filepath,delimiter="\t",dtype=np.float32,encoding="utf-8")
# shape[0]: rows
# shape[1]: cols
self.len = xy.shape[0]
# 归一化
for i in range(xy.shape[1]):
xy_max = np.max(xy[:,i])
xy_min = np.min(xy[:,i])
xy[:,i] = (xy[:,i]-xy_min) / (xy_max - xy_min)
self.y_max = np.max(xy[:,-1])
self.y_min = np.max(xy[:,-1])
self.x_data = torch.from_numpy(xy[:,:-1])
self.y_data = torch.from_numpy(xy[:,-1])
# get data by index
def __getitem__(self,index):
return self.x_data[index],self.y_data[index]
# get total of data
def __len__(self):
return self.len
dataset = DiabetesDataset("./data/diabetes.txt")
# param
epochs = 300
batchsize = 32
iters = dataset.len / batchsize
train_loader = DataLoader(dataset = dataset,
batch_size = batchsize,
shuffle=True,
drop_last= True,
num_workers = 0) # num_worker为多线程
# define the model
class FNNModel(torch.nn.Module):
def __init__(self):
super(FNNModel,self).__init__()
# 输入特征有10个,也就是10个维度,将其降为6个维度
self.linear1 = torch.nn.Linear(10,6)
# 6维 -> 4 维
self.linear2 = torch.nn.Linear(6,4)
# 4维 -> 2 维
self.linear3 = torch.nn.Linear(4,2)
# 2维 -> 1 维
self.linear4 = torch.nn.Linear(2,1)
# sigmoid层,作为输出层
self.sigmoid = torch.nn.Sigmoid()
# forward
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
x = self.sigmoid(self.linear4(x))
return x
model = FNNModel()
# define the criterion(标准) and optimizer
criterion = torch.nn.BCELoss(reduction="mean") # 返回损失的平均值
optimizer = torch.optim.SGD(model.parameters(),lr = 0.01)
epoch_list = []
loss_list = []
# training
if __name__ == "__main__":
for epoch in range(epochs):
# data 获取的数据为 (x,y)
loss_one_epoch = 0
for i ,data in enumerate(train_loader,0):
inputs,labels = data
y_pred = model(inputs)
loss = criterion(y_pred,labels.unsqueeze(dim=1))
loss_one_epoch += loss.item() # 累加
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_list.append(loss_one_epoch/iters) # 求个平均值
epoch_list.append(epoch)
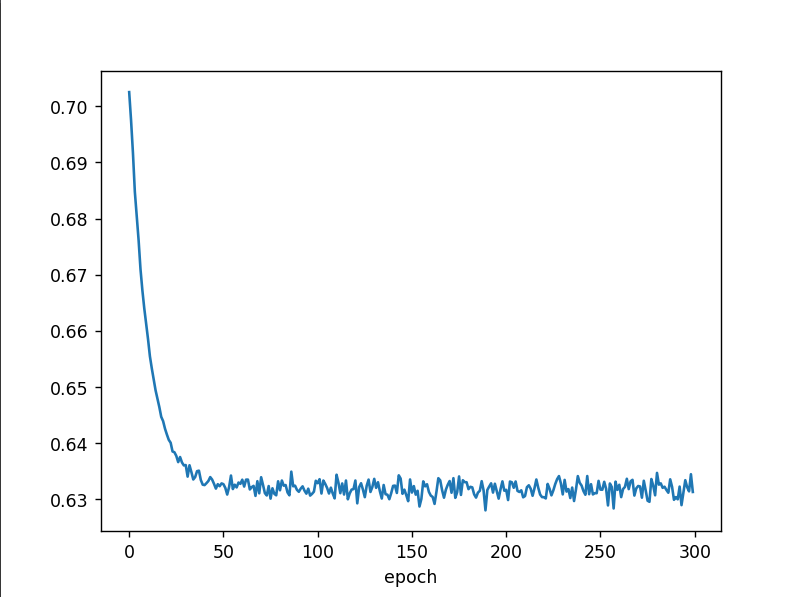
print("Epoch[{}/{}], loss:{:.6f}".format(epoch+1,epochs,loss_one_epoch/iters))
# drawing
plt.plot(epoch_list,loss_list)
plt.xlabel("epoch")
plt.show()
八、模型保存
在保存和加载模型方面主要有三个核心 的方法:
- torch.save
将对象序列化保存到磁盘中,底层通过python中的pickle来序列化,各种Models,tensors,dictionaries都可以使用该方法保存。保存的模型文件名可以是.pth,.pt,.pkl - torch.load
采用pickle将反序列化的对象从存储中加载进内存。 - torch.nn.Module.load_state_dic
采用一个反序列的state_dict()方法将模型的参数加载到模型结构上load_state_dict(state_dict,strict=True) # state_dict, 保存parameters和persistent buffers的字典 # stric 可选,bool, state_dict中的key是否和model.state_dict()返回的key一致
序列化和反序列化:
- 序列化( Serialization ) 是将对象的状态信息转换为可以存储在或者传输的形成的过程。
- 在序列化器件,对象将其当前状态写入到临时或者持久性存储区,以后可以从存储区中读取或者反序列化对象的状态,重建该对象。
8.1 状态字典state_dict
state_dict()在神经网络中可以认为是模型上训练出来的模型参数,权重和偏置值。
Pytorch中,定义的网络模型是通过继承torch.nn.Module来实现的,网络模型中包含可以学习的参数( weights、bias和一些登记的缓存 )。模型内部的可学习参数可以通过两种方式进行调用。
- model.parameters() 访问所有参数
- model.state_dict() 来为每一层和它的参数建立一个映射关系并存储在字典中,键值由每个网络层和其对应的参数张量构成。
除了模型,优化器对象( torch.optim ) 也有一个状态字典,包含优化器状态信息以及使用的超参数。
使用ResNet18,并使用与训练权重。
import torch.optim as optim
from torchvision.models import resnet18,ResNet18_Weights
# 定义模型,并使用预训练权重
model = resnet18(weights=ResNet18_Weights.DEFAULT)
# 定义优化器,随机梯度优化器
optimizer = optim.SGD(model.parameters(),lr=0.001,momentum=0.9)
# 模型的 state_dict
print(type(model.state_dict()))
for key,value in model.state_dict().items():
print(key,"\t",value,size())
# 模型的model.parameters()
print(model.parameters())
# 1. 使用for循环
for para in model.parameters():
print(para.size())
# 2. 使用list() 转换为list
# 优化器的state_dict
for key,value in optimizer.state_dict().items():
print(key,value)
- 通过.state_dict()打印模型每个网络层的名字和参数
- 通过.parameters()打印模型的每个网络层的参数
- 通过.state_dict()打印优化器每个网络层名字和参数
8.2 加载/保存状态字典(state_dict)
保存一个模型的时候,只需要保存训练模型的可学习参数即可,通过torch.save()来保存模型的状态字典。
加载模型时,通过torch.load()来加载模型的状态字典,且通过.load_state_dict()将状态字典加载到模型上。
import torch
from torchvision.models import resnet18,ResNet18_Weights
# 定义模型,并使用预训练权重
model = resnet18(weights=ResNet18_Weights.DEFAULT)
# 保存模型的state_dict
# 可以是pth,pt,pkl后缀的文件名
path = "./model.pth"
torch.save(model.state_dict(),path)
# =========加载模型 ===========
# 1. 定义模型
model = resnet18()
# 2. 加载状态字典进内存
state_dict = torch.load(path)
# 3. 将状态字典中的可学习参数加载到模型上使用
model.load_state_dict(state_dict)
8.3 加载/保存整个模型
保存整个模型对象(包括模型结构和状态字典等)
这种保存模型的做法是采用python的pickle模块来保存整个模型,方法的缺点是pickle不保存模型类别,而是保存一个包含该类的文件的路径。
在加载的时候,需要先定义一下这个模型类,否则可能会报错。
保存模型
import torch
from torchvision.models import resnet18,ResNet18_Weights
# 定义模型,并使用预训练权重
model = resnet18(weights=ResNet18_Weights.DEFAULT)
# 保存模型的全部
path = './model.pth'
torch.save(model,path)
加载模型
import torch
# 需要注意:定义一下这个类,否则会报错
from torchvision.models import resnet18
# 加载模型
path = "./model.pth"
model = torch.load(path)
参考
- Pytorch官网
https://pytorch.org/ - 清华pypi镜像:
https://mirrors.tuna.tsinghua.edu.cn/help/pypi/ - 2022 Pytorch基础入门教程
https://blog.csdn.net/ccaoshangfei/article/details/126074300 - Pytorch教程
https://blog.csdn.net/weixin_45526117/article/details/123997738 - Pytorch中文文档
https://www.pytorchtutorial.com/docs/ - 数据集
https://zhuanlan.zhihu.com/p/618818240 - pytorch保存和加载模型
https://blog.csdn.net/weixin_41012765/article/details/128008960