本周免费接了一个用户的需求,研究了一下小红书旋转验证码。刚开始小瞧了它,觉得它应该没有百度旋转验证码那么难,毕竟图像没有干扰,需要的训练样本就可以很少。然而事情并没有这么简单,所以记录一下。
首先看一下最终的效果:
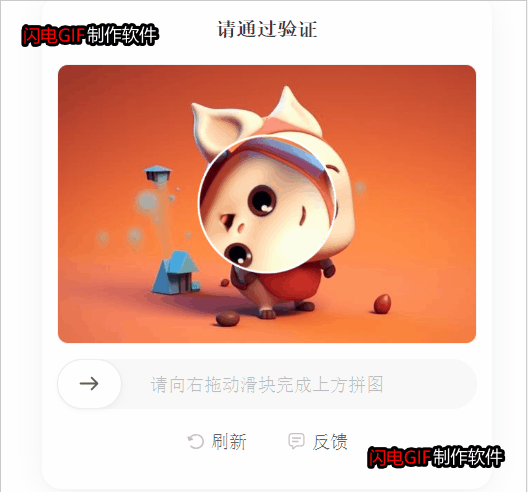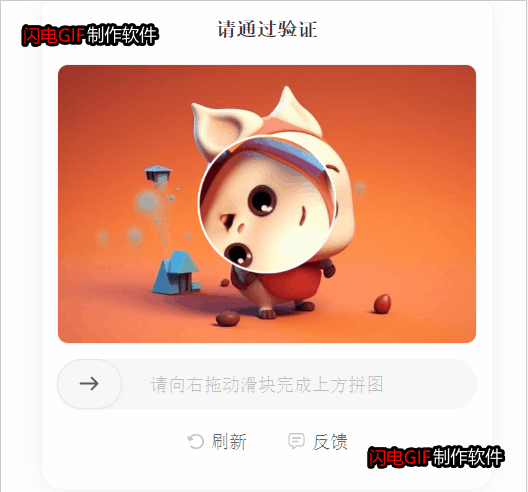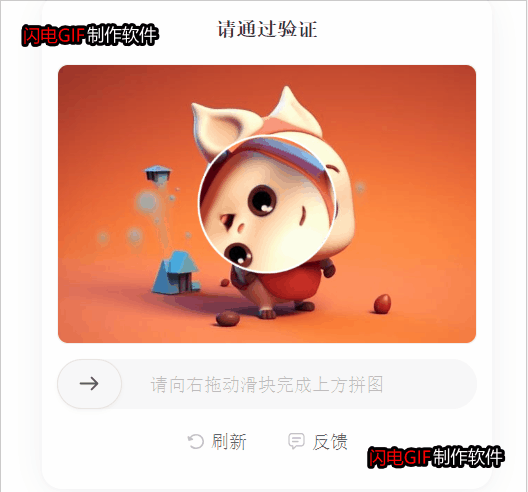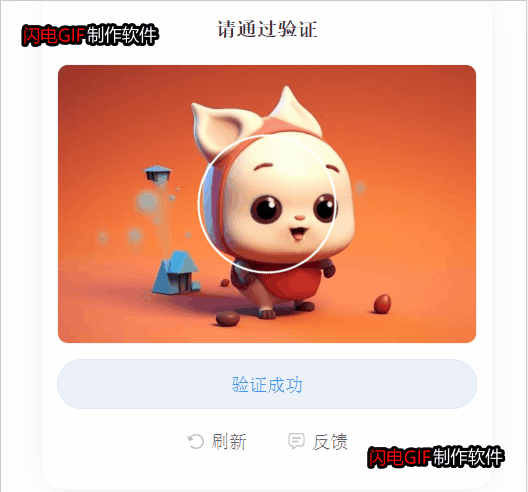
验证码识别过程
1、利用爬虫采集图像
这里最好大小图都采集,刚开始我就只采集了小图,就踩了一个坑,因为只有小图很难通过小图旋转到正确位置。并不能通过眼睛等特征来确定是否选择正了,因为有很多图片本身头的歪的。所以就会导致最终识别结果偏差较大。
(1)采集大图
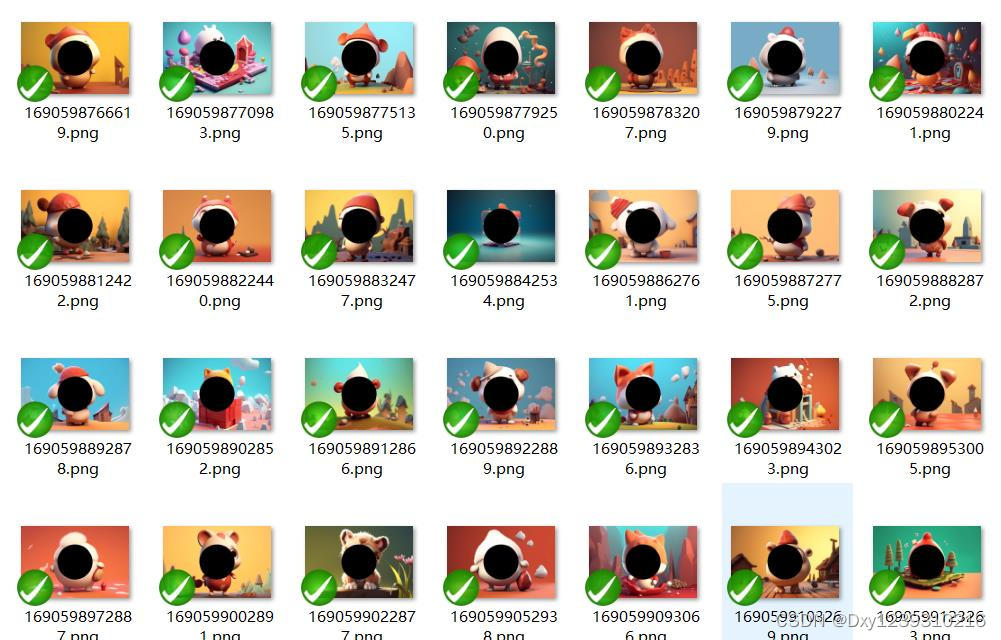
(2)采集小图
2、人工标记
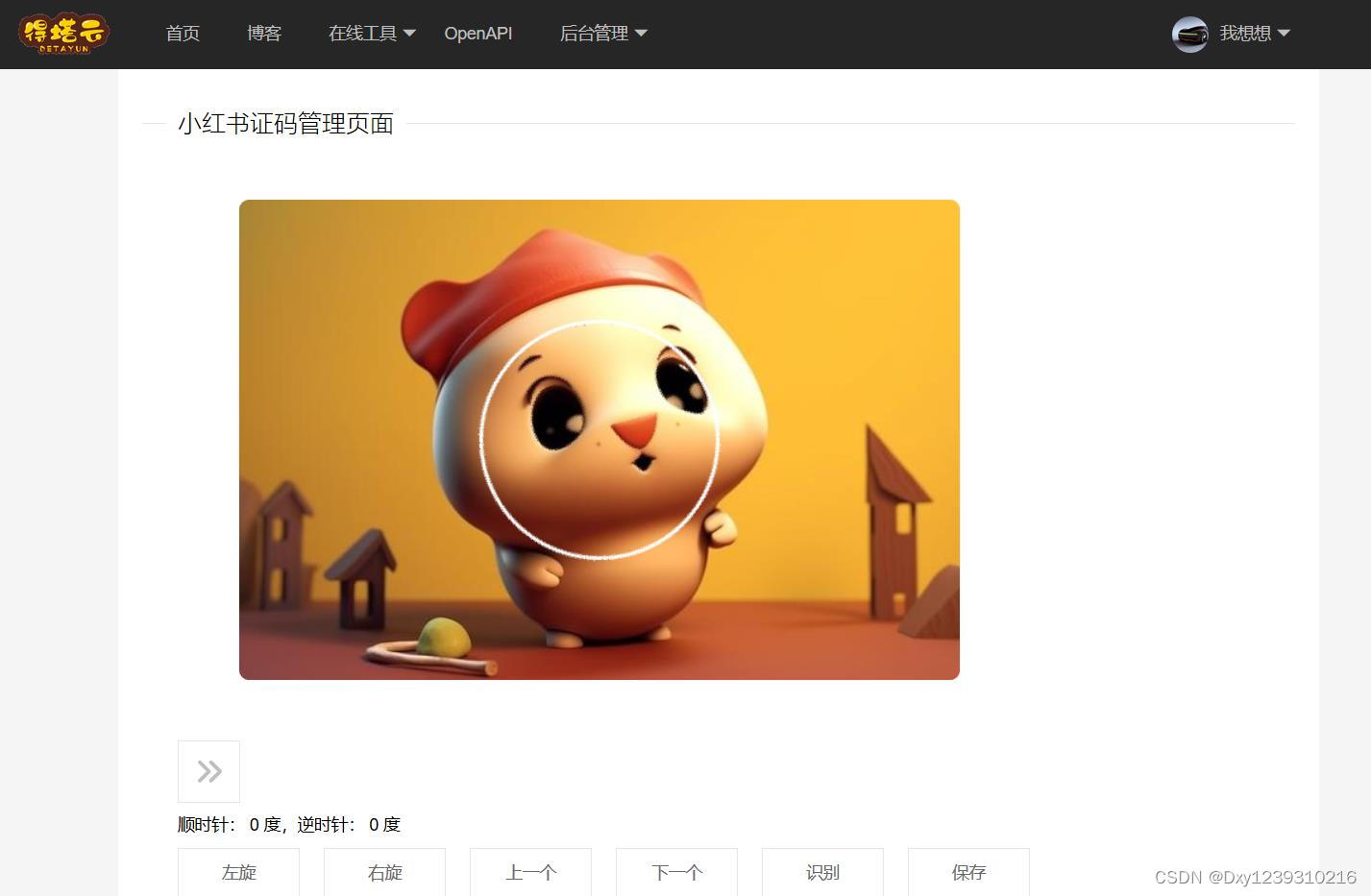
为了保证旋转到正确的角度,我还专门开发了一个标记小工具如下图。
可以通过拖动滑块旋转小图到大概位置,再通过点击按钮进行微调,旋转到绝对正确的角度。
这样能保证我标记的图片角度100%正确,只有提升了标记数据的质量,才会让最终识别的效果达到最好。
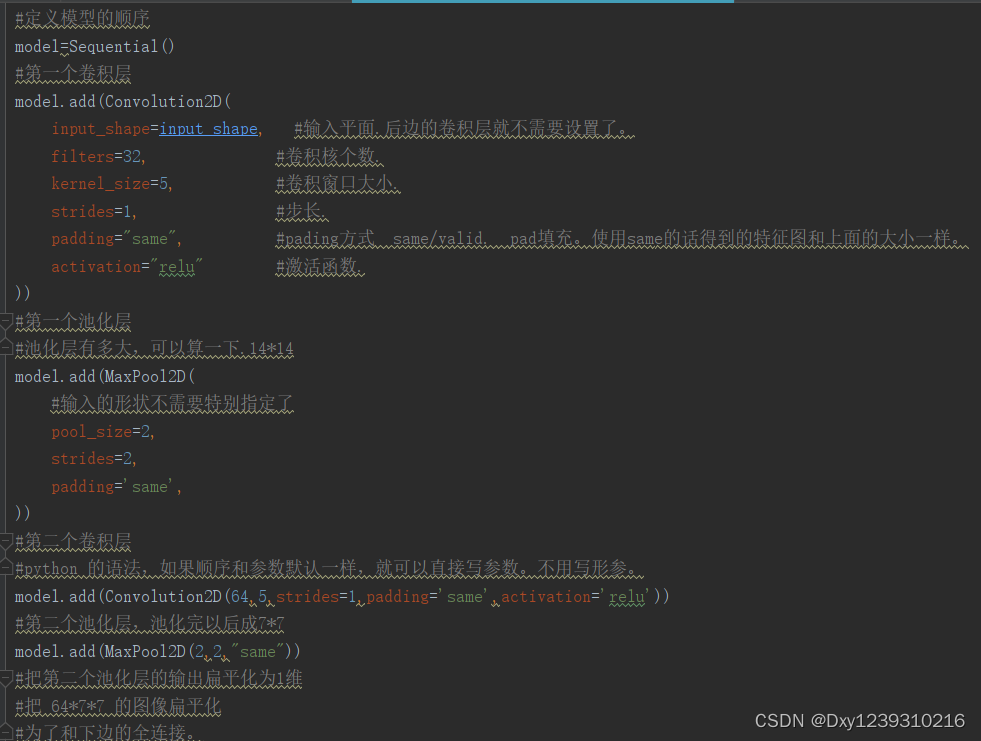
3、训练模型
4、测试验证
我们将训练好的模型用100张图片来进行测试,发现只有4张图片旋转角度有问题,所以最终模型的实际正确率为96%。
如果再想提升正确率,可以再增加训练的数据量,就需要再投入大量人力,这个投入与提升产出比需要自己权衡。
5、实战测试
这里我就直接上代码,就是文章开通动图的演示效果。我也将模型封装成了免费的接口给感兴趣的小伙伴调用:得塔云
__author__ = 'Xin Yan Deng'
import os
import sys
import time
import requests
import random
import base64
from io import BytesIO
from PIL import Image
sys.path.append(os.path.abspath(os.path.dirname(os.path.abspath(os.path.dirname(__file__)))))
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.action_chains import ActionChains
# PIL图片保存为base64编码
def PIL_base64(img, coding='utf-8'):
img_format = img.format
if img_format == None:
img_format = 'JPEG'
format_str = 'JPEG'
if 'png' == img_format.lower():
format_str = 'PNG'
if 'gif' == img_format.lower():
format_str = 'gif'
if img.mode == "P":
img = img.convert('RGB')
if img.mode == "RGBA":
format_str = 'PNG'
img_format = 'PNG'
output_buffer = BytesIO()
# img.save(output_buffer, format=format_str)
img.save(output_buffer, quality=100, format=format_str)
byte_data = output_buffer.getvalue()
base64_str = 'data:image/' + img_format.lower() + ';base64,' + base64.b64encode(byte_data).decode(coding)
return base64_str
# 验证码识别接口
def shibie(img):
url = "http://www.detayun.cn/openapi/verify_code_identify/"
data = {
# 用户的key
"key":"",
# 验证码类型
"verify_idf_id":"24",
# 样例图片
"img_base64":PIL_base64(img),
"img_byte": None,
# 中文点选,空间语义类型验证码的文本描述(这里缺省为空字符串)
"words":""
}
header = {"Content-Type": "application/json"}
# 发送请求调用接口
response = requests.post(url=url, json=data, headers=header)
print(response.text)
return response.json()
driver = webdriver.Chrome(executable_path='.\webdriver\chromedriver.exe')
# 加载防检测js
with open('.\webdriver\stealth.min.js') as f:
js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
driver.get('https://www.xiaohongshu.com/website-login/captcha?redirectPath=https%3A%2F%2Fwww.xiaohongshu.com%2Fexplore&verifyUuid=shield-4f9bcc31-0bc0-462a-843a-e60239713e46&verifyType=101&verifyBiz=461')
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
time.sleep(5)
for i in range(10):
# 等待【旋转图像】元素出现
WebDriverWait(driver, 5).until(lambda x: x.find_element_by_xpath('//div[@id="red-captcha-rotate"]/img'))
# 找到【旋转图像】元素
tag1 = driver.find_element_by_xpath('//div[@id="red-captcha-rotate"]/img')
# 获取图像链接
img_url = tag1.get_attribute('src')
print(img_url)
header = {
"Host": "picasso-static.xiaohongshu.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Cookie": "xsecappid=login; a1=1896916369fehn0yq7nomanvre3fghfkj0zubt7zx50000120287; webId=75af27905db67b6fcb29a4899d200062; web_session=030037a385d8a837e5e590cace234a6e266fd5; gid=yYjKjyK484VKyYjKjyKqK89WjidxI8vAWIl6uuC0IhFdq728ikxiTD888yJ8JYW84DySKW0Y; webBuild=2.17.8; websectiga=634d3ad75ffb42a2ade2c5e1705a73c845837578aeb31ba0e442d75c648da36a; sec_poison_id=41187a04-9f82-4fbc-8b98-d530606b7696",
"Upgrade-Insecure-Requests": "1",
"If-Modified-Since": "Thu, 06 Jul 2023 11:42:07 GMT",
"If-None-Match": '"7e53c313a9f321775e8f5e190de21081"',
"TE": "Trailers",
}
# 下载图片
response = requests.get(url=img_url, headers=header)
img = Image.open(BytesIO(response.content))
img.convert('RGB').save('train_img/{}.jpg'.format(int(time.time() * 1000)))
res = shibie(img)
angle = int(str(res['data']['res_str']).replace('顺时针旋转','').replace('度',''))
print(angle)
# img = img.rotate(360 - angle, fillcolor=(0, 0, 0))
# img.show()
# 等待【旋转图像】元素出现
WebDriverWait(driver, 5).until(lambda x: x.find_element_by_xpath('//div[@class="red-captcha-slider"]'))
# 找到【旋转图像】元素
tag2 = driver.find_element_by_xpath('//div[@class="red-captcha-slider"]')
# 滑动滑块
action = ActionChains(driver)
action.click_and_hold(tag2).perform()
time.sleep(1)
# 计算实际滑动距离 = 像素距离 + 前面空白距离
move_x = angle * 0.79
# 滑动1:直接滑动
action.move_by_offset(move_x, 5)
# 滑动2:分段滑动
# n = (random.randint(3, 5))
# move_x = move_x / n
# for i in range(n):
# action.move_by_offset(move_x, 5)
# time.sleep(0.01)
time.sleep(1)
action.release().perform()
time.sleep(2)
6、总结分析
(1)和百度相比,图片标注变简单了,图像种类比百度少了一半。
(2)和百度相比,对 selenium 检测更厉害了,我用火狐+反检测一直过不了,使用谷歌+反检测可以通过,但是滑对了也会多次验证
(3)和百度相比,滑动轨迹检测更厉害了,目前不是太确定,因为我一次快速滑动,还是分段滑动效果感觉差不多
各位大神如果对滑动提高通过率,或者有其他建议都可以给我留言,或私信我,谢谢指点。