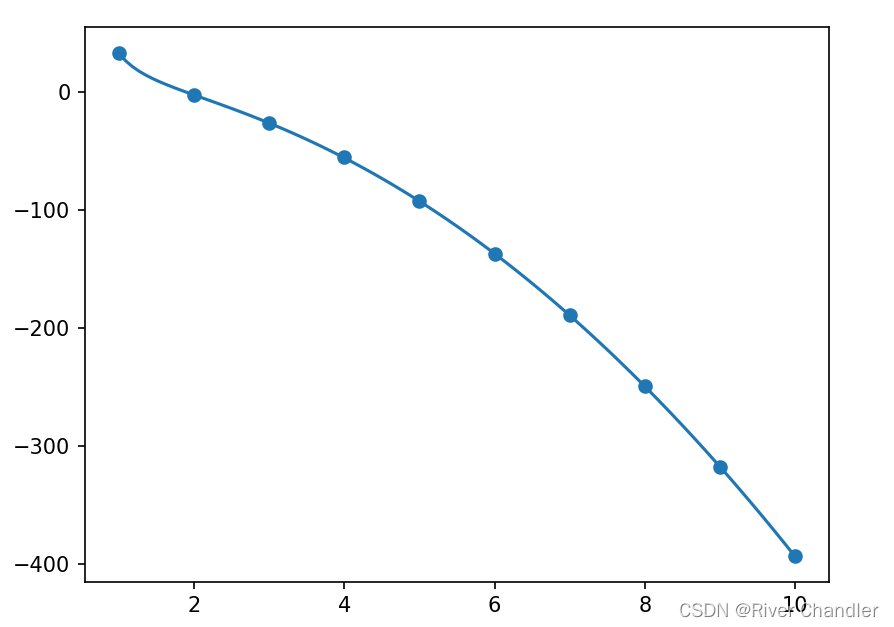
🔥 下面我只是分析讲解下这些方法的原理以及具体代码是怎么实现的,不对效果进行评价,毕竟不同任务不同数据集效果差别还是挺大的。
文章目录
- 0、hard prompt & soft prompt区别
- 1、Prefix-Tuning
- 2、Prompt-Tuning
- 3、P-tuning
- 4、P-tuning-v2
- 5、来看看adapter,lora,prefix-tuing&p-tuning-v2的结构上的区别:
0、hard prompt & soft prompt区别
- hard prompt (离散):即人类写的自然语言式的prompt。
- soft prompt (连续):可训练的权重,可以理解为伪prompt。【毕竟nn是连续的模型,在连续空间中优化离散的prompt, 难以优化到最佳效果。额也就是说所谓的hard prompt对于人类来说好理解,但模型不一定好理解,所以不妨丢给模型去学习处更好理解的prompt】
1、Prefix-Tuning
训练参数:prefix相关参数

- 在生成任务中被提出。如上图所示,在每一层transformer层加入了prefix ,它是连续的可学习权重向量(即soft prompt),训练时冻结transformer,只训练prefix。
- 所以,训练的参数是非常小的,不同类型的任务学习一个特定任务的prefix。

如上图所示:
- 对于Decoder-only的GPT,prefix只加在句首。
- 对于Encoder-Decoder的BART,不同的prefix同时加在编码器和解码器的开头。
Prefix 具体添加到模型的哪部分?
🔥 重点来了,虽然上面都是形式化的说,把prefix token加在句首,但实际实现时并不是这样的
✨ 我的理解:实际实现时,是将prefix权重向量和K, V矩阵拼接(类似past-key-value机制,但这里目的不是为了加快解码速度,因为p-tuning-v2是prefix-tuning的优化版,可以看看这里对p-tuning-v2的实际代码实现的理解【P-tuning-v2代码理解】)。通过self-attention将prefix的隐式含义编码在输出的特征中(即query维度里)。

2、Prompt-Tuning
训练参数:prompt相关参数
属于 prefix-tuning 的简化版。

它给每个任务定义了自己的Prompt,然后拼接到数据上作为输入,但只在输入层加入prompt tokens(可以是词表里没有使用的unused token,只对这些token的embedding更新),并且不需要加入 MLP 进行调整来解决难训练的问题。伪代码如下:
def soft_prompted_model(input_ids):
x = Embed(input_ids)
x = concat([soft_prompt, x], dim=seq)
return model(x)
另外地,Prompt Tuning 还提出了 Prompt Ensembling(不是指上面那个图),也就是在一个批次(Batch)里同时训练同一个任务的不同 prompt(即采用多种不同方式询问同一个问题),这样相当于训练了不同模型,比模型集成的成本小多了。
3、P-tuning
训练参数:模型本身的参数+soft prompt相关参数
可简单理解为p-tuning是prompt-tuning的改进。
对于离散的hard prompt,改变其中的某几个词,结果差异非常大。而连续的soft prompt则可在连续空间中构造和优化。 范式:soft+hard prompt。【如右图图中橙色Pi token即为soft(即pseudo token,可以是词表中的 [unused*] token)而capital为hard。】`

具体地:
- 使用Bi-LSTM对模板中的pseudo token序列进行特征抽取。
- 加上一些anchor token即hard可优化效果。
前向流程:
- 1、初始化一个模板:The capital of [X] is [mask]
- 2、替换输入:[X]处替换为输入“Britain”,即预测Britain的首都
- 3、挑选模板中的一个或多个token作为soft prompt
- 4、将所有的soft prompt 送入LSTM,获得每个soft prompt的隐状态向量h
- 5、将模板送入Bert的embedding layer,所有soft token embedding (用h代替)和其他非soft token经过bert嵌入层的embedding拼接传入后面的bert-encder ,然后预测mask。
补充知识:
- 苏剑林认为,LSTM是为了帮助模版的几个token(某种程度上)更贴近自然语言,但这并不一定要用LSTM生成,而且就算用LSTM生成也不一定达到这一点。更自然的方法是在训练下游任务的时候,不仅仅预测下游任务的目标token(如例子中的“新闻”),还应该同时做其他token的预测。
- 具体来说,如果是MLM模型,那么也随机mask掉其他的一些token来预测;如果是LM模型,则预测完整的序列,而不单单是目标词。因为模型都是经过自然语言预训练的,增加训练目标后重构的序列也会更贴近自然语言的效果。苏神测试发现,效果确实有所提升。
4、P-tuning-v2
训练参数:prompt相关参数
属于 p-tuing的deep版,可以说就是Prefix Tuning,但做了些优化。

动机:
- 缺乏规模通用性:Fail to work well on small models
- 缺乏任务普遍性:Fail to work well on hard NLU tasks
方法:
- 具体实现就类似prefix-tuning了,也是通过注入新的kv矩阵拼接到原kv矩阵中来代替说将prompt token拼接到句子的头部,类似past-key-value机制,但这里目的不是为了加快解码速度【P-tuning-v2代码理解】。
- 缺少深度提示优化。 prompt-tuning和p-tuning仅在transformer的 第一层加入soft prompt,p-tuning v2 提出 Deep Prompt Tuning的方法,在transformer 的每一层之前都加入了soft prompt。
- 这样一来,更多可学习的参数,深层结构中的Prompt能给模型预测带来更直接的影响。
对prefix-tuning的优化:
-
移除重参数化的编码器: 以前的方法利用重参数化功能来提高训练速度和鲁棒性(如:Prefix Tuning中的MLP、P-Tuning中的LSTM))。在 P-tuning v2 中,作者发现重参数化的改进很小,尤其是对于较小的模型;同时对于某些NLU任务,使用MLP会降低性能
-
不同任务采用不同的提示长度: 提示长度在P-Tuning v2中起着关键作用,不同的NLU任务会在不同的提示长度下达到其最佳性能。通常,简单的分类任务(情感分析等)偏好较短的提示(小于20个令牌);困难的序列标注任务(阅读理解等)则偏好较长的提示(大约100个令牌)
-
引入多任务学习: 先在多任务的Prompt上进行预训练,然后再适配下游任务。多任务可以提供更好的初始化来进一步提升性能
-
回归传统的分类标签范式: P-Tuning v2回归传统的CLS标签分类范式,采用随机初始化的分类头(Classification Head)应用于tokens之上,以增强通用性,可以适配到序列标注任务。
5、来看看adapter,lora,prefix-tuing&p-tuning-v2的结构上的区别:
- adapter是对每个transformer block增加了额外的权重。
- lora是对每一层的qv权重矩阵Wq, Wv增加了lora权重(图中是qk,不妨碍理解,lora论文实验测试出的最佳组合是qv)。推理时可以直接加到原权重上,就没有额外权重了。
- prefix-tuning&p-tuning-v2则是对每一层K, V矩阵操作,也是通过注入新的kv矩阵拼接到原kv矩阵中来代替说将prompt token拼接到句子的头部,类似past-key-value机制,但这里目的不是为了加快解码速度【P-tuning-v2代码理解】。