目录
- 前言
- 1. 数据结构绪论
- 1.1 数据结构的概念及分类
- 1.1.1 知识点提要
- 1.1.2 选择判断与简答归纳
- 1.1.3 算法编程题
- 1.2 算法设计与算法分析
- 1.2.1 知识点提要
- 1.2.2 选择判断与简答归纳
- 1.2.3 算法编程题
- 2. 线性表
- 2.1 线性表的概念
- 2.1.1 知识点提要
- 2.1.2 选择判断与简答归纳
- 2.1.3 算法编程题
- 2.2 顺序表
- 2.2.1 知识点提要
- 2.2.2 选择判断与简答归纳
- 2.2.3 算法编程题
- 2.3 线性表的链式存储表示
- 2.3.1 知识点提要
- 2.3.2 选择判断与简答归纳
前言
摆烂到底要摆烂到什么时候?好好学习。本篇博客不定时更新,复习资料为清华大学出版社的殷人昆编著的数据结构精讲与习题详解(C语言版)第二版。本篇博客适合对数据结构有初步了解但了解不多的同道中人阅读参考,博客中编程题给出的参考代码并不完全与书中相同,写本篇博客的初衷是为了自己备考复习方便,如有错漏,欢迎指出。
1. 数据结构绪论
1.1 数据结构的概念及分类
1.1.1 知识点提要
- 数据、数据元素和数据对象
(1)数据是信息的载体,是对客观事物的符号表示,是对所有能输入到计算机中并被计算机程序识别和处理的符号的集合。
(2)数据元素是数据的基本单位,在计算机程序中数据元素常作为一个整体进行考虑和处理,数据元素又可称为元素、结点、记录。
(3)一个数据元素可由若干数据项组成,数据项还可分为组项和基本项,组项还可以由更小的组项和基本项构成,而基本项则是具有独立含义的最小表示单位。
(4)数据元素的集合构成一个数据对象,它针对某种特定的应用。 - 数据结构
数据结构指某一数据对象中所有元素及他们之间的关系。
数据结构是指元素间的逻辑关系,与数据存储无关。
数据的存储结构是数据的逻辑结构在计算机内的表示。
操作的实现以来于数据的存储结构。 - 数据的逻辑结构分类
线性结构:一对一
树形结构:一对多
图结构:多对多
集合结构:空(集合结构的实现往往采用其他逻辑结构的存储表示) - 数据的存储结构分类
顺序存储:连续的存储区域相继存放数据元素
链式存储:附加指针
索引存储:建立索引表
散列存储:散列函数直接把数据记录的关键码映射为该元素的存放地址 - 数据类型与抽象数据类型
(1)数据类型是一个值的集合和定义在这个值集合上的一组操作的总称。
可分为两大类:
a.基本数据类型:计算机中已实现的如int等,可以直接使用
b.构造数据类型:由基本数据类型或构造数据类型组成,在应用中可视 为一种数据模型。
(2)抽象数据类型是一种构造数据类型,有三大特征:
a. 信息隐蔽
b. 数据封装
c. 使用与实先相分离
1.1.2 选择判断与简答归纳
- 存储结构是逻辑结构的计算机实现,逻辑结构独立于存储结构
- 逻辑结构相同,即使存储结构不同,也是相同的数据结构。
- 在计算机中信息必须以数据呈现。
1.1.3 算法编程题
- 编写一个C语言程序,输出字符串“Hello,world.”
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
char*hello(char *name)
{
char*value = (char*)malloc(9 + strlen(name));
sprintf(value, "Hello,%s.", name);
return value;
}
int main()
{
printf("%s\n", hello("world"));
return 0;
}
博主瞎逼逼:这个程序书中给的答案有些炫技哈,实现地非常装X。放在这给大家看一下。
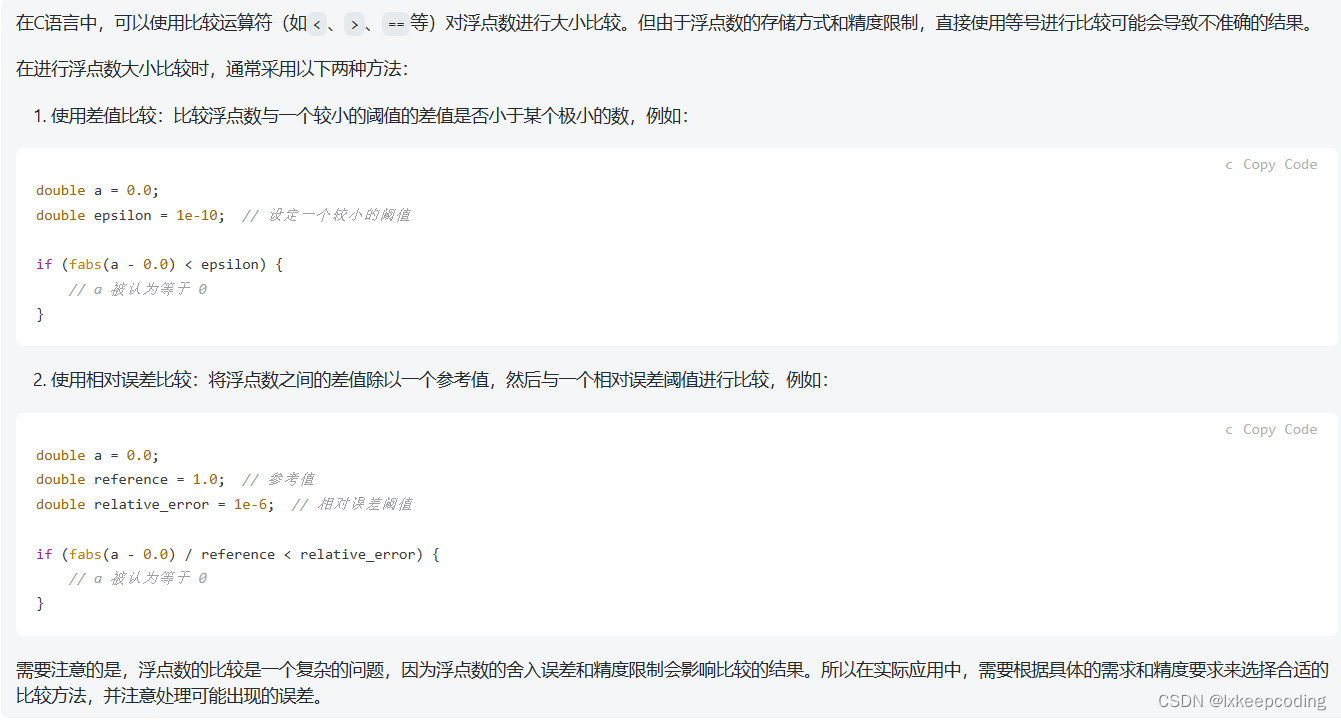
- 求一元二次方程的实数根
利用求根公式

在与0比较大小时,需要注意:
- 素数
可参考本人之前文章
找出1000以内所有素数
1.2 算法设计与算法分析
1.2.1 知识点提要
- 算法的概念
基于特定的计算模型,在信息处理过程中为了解决某一类问题而设计的一个指令序列。
5个特征:有输入、有输出、确定性、可行性、有穷性。 - 算法设计的基本方法
(1)穷举法:为避免重复试探a.按规则列举 b. 盲目列举(随时检查是否重复)
(2)迭代法
(3)递推法:
递推法求解问题有递归和非递归两种方法,递归是自顶向下的方法,非递归是迭代法计算。
(4)递归法:包括直接求解项和递归项两部分 - 算法的评价标准
正确性
健壮性
可读性
高效性
简单性 - 算法分析主要方法
(1)事后估算法
(2)事前统计法 - 时间复杂度和空间复杂度
时间复杂度
空间复杂度
1.2.2 选择判断与简答归纳
- 为解决某问题所编写的算法与为该问题编写的程序含义是相同的
- 阶乘的时间复杂度为O(N)
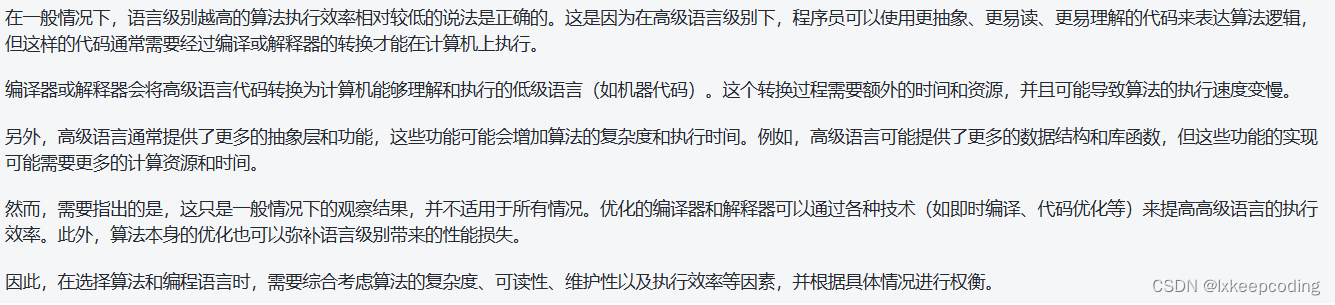
- 同一个算法,实现语言级别越高,算法执行效率越低。
- 算法可以有0个输入中的输入指算法的输入不是通过键盘或其他设备输入的,而是通过算法内部的定值语句或赋值语句所给出所需变量的初值,可被视为一种特殊的输入。
- 出错处理方式
a. exit(1)
b. 返回0、1区别正常返回还是错误返回
c. 在函数的参数表设置一个引用型的整型变量来区别正常返回还是某种错误返回
1.2.3 算法编程题
- 求正整数m,和n的最大公约数
(1)辗转相除法(欧几里得解法)
欧几里得算法(也称为辗转相除法)用于求两个整数的最大公约数(Greatest Common Divisor,简称GCD)。算法基于以下原理:两个整数a和b的最大公约数等于b和a除以b的余数的最大公约数。具体的算法步骤如下:
将较大的数记为a,较小的数记为b。
计算a除以b的余数,记为r。
若r等于0,则b即为最大公约数。
若r不等于0,则令a等于b,b等于r,然后跳转到步骤2
int gcd(int m, int n)
{
if (m <= 0 || n <= 0)
return 0;
if (m < n)
{
int temp = m;
m = n;
n = temp;
}
while (n>0)
{
int r = m%n;
m = n;
n = r;
}
return m;
}
(2)计算正整数最大公约数不会大于其中小者,基于此思路可以求解。
a.计算m和n中的小者为t
b.计算m mod t0并且n mod t0,结果为true,最大公约数为t,求解结束否则转到c
c. t值减一,转回b
int gcd(int m, int n)
{
int t = (m > n) ? n : m;
while (m%t != 0 || n%t != 0)
t--;
return t;
}
- 设有一个n个整数的数组A,设计递归算法,实现正向输出和反向输出
#include<stdio.h>
void printForward(int A[], int i, int n)
{
if (i >= n)
return;
printf("%d ", A[i]);
printForward(A, i + 1, n);
}
void printBackward(int A[], int i, int n)
{
if (i >= n)
return;
printBackward(A, i + 1, n);
printf("%d ", A[i]);
}
int main()
{
int A[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
int n = 9;
printForward(A, 0, n);
printf("\n");
printBackward(A, 0, n);
}
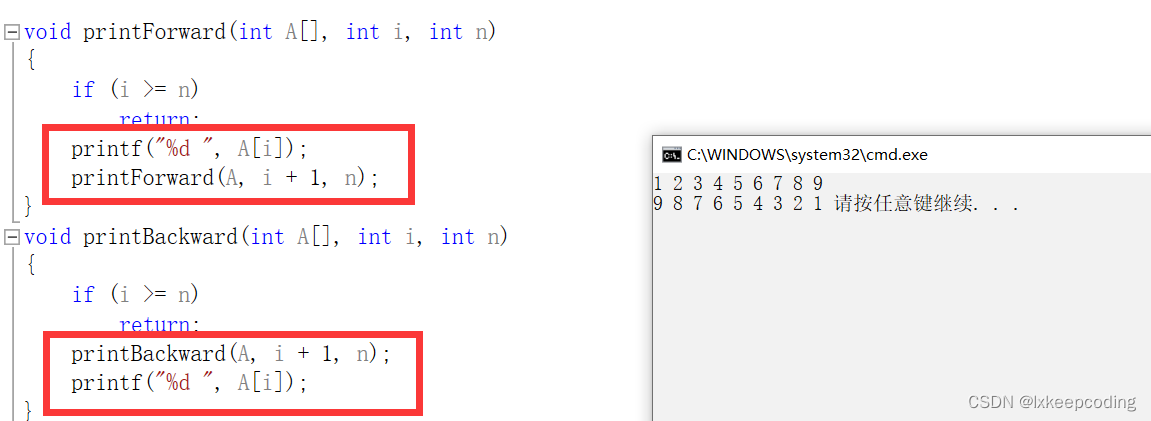
注意正向和反向输出时的语句顺序。
2. 线性表
2.1 线性表的概念
2.1.1 知识点提要
- 线性表是计算机科学中一种常见的数据结构,它是由具有相同数据类型的一组元素按照线性顺序排列而成的。线性表中的元素之间存在一对一的关系,即除了第一个元素外,每个元素都有一个前驱元素,并且除了最后一个元素外,每个元素都有一个后继元素。
线性表可以用于表示各种实际问题中的数据结构,例如数组、列表、栈和队列等。它具有灵活性和广泛的应用性,适用于各种数据存储和处理需求。
在数学上,线性表通常表示为 L=(a1, a2, …, an),其中 L 是线性表的名称,ai (1 ≤ i ≤ n) 是线性表中的元素,n 表示线性表中元素的个数,也称为线性表的长度。线性表的元素可以是任意数据类型,例如整数、浮点数、字符等。
线性表的基本操作包括:
插入:将一个元素插入到线性表的指定位置。
删除:从线性表中删除指定位置的元素。
查找:在线性表中查找指定元素,并返回其位置或者相关信息。
修改:修改线性表中指定位置的元素的值。
获取:获取线性表中指定位置的元素的值。
遍历:依次访问线性表中的每个元素。
线性表的具体实现方式有多种,包括使用数组、链表和动态数组等。选择不同的实现方式可以根据具体的需求和操作特点来进行权衡和选择。
- 线性表具有以下特点:
顺序性:线性表中的元素按照一定的顺序排列,每个元素都有一个明确的前驱和后继,形成线性的结构。这意味着线性表中的元素之间存在一一对应的关系。
有限性:线性表的长度是有限的,即线性表中元素的个数是确定的。线性表可以为空表(长度为0),也可以包含多个元素。
存储结构:线性表的元素可以使用不同的存储结构来实现,例如数组、链表、动态数组等。不同的存储结构对于线性表的操作和性能方面会有不同的影响。
可插入和可删除:线性表允许在任意位置插入新的元素,也可以从任意位置删除元素。这使得线性表具有动态性,能够灵活地调整和改变表的结构。
同质性:线性表中的元素具有相同的数据类型,即线性表中的元素类型是一致的。这使得线性表在存储和操作时更加简单和统一。
有序访问:线性表中的元素可以按照一定的顺序进行访问,可以通过下标或者迭代器等方式实现对元素的有序访问。
2.1.2 选择判断与简答归纳
- 线性表是有限序列,元素不可以是线性表
- 将两个有序线性表合并成一个有序线性表元素比较次数最少为n次,最多为2n-1次。
- 序列是集合的特殊情形。
2.1.3 算法编程题
- 两个线性表A与B,求二者并集和交集
#include <stdio.h>
// 定义线性表最大长度
#define MAX_SIZE 100
// 求并集函数
void getUnion(int a[], int b[], int m, int n) {
int c[MAX_SIZE]; // 存放并集结果的线性表
int i, j, k;
// 将线性表 A 的元素复制到结果线性表 C
for (i = 0; i < m; i++) {
c[i] = a[i];
}
k = m; // 结果线性表 C 中已有元素的个数
// 遍历线性表 B,判断是否与线性表 A 中的元素重复
for (j = 0; j < n; j++) {
int exist = 0; // 标记线性表 B 中的元素是否已存在于结果线性表 C
// 判断线性表 B 中的元素是否与结果线性表 C 中的元素重复
for (i = 0; i < m; i++) {
if (b[j] == a[i]) {
exist = 1;
break;
}
}
// 如果线性表 B 中的元素不重复,则将其加入结果线性表 C
if (!exist) {
c[k++] = b[j];
}
}
// 输出并集结果线性表 C
printf("Union: ");
for (i = 0; i < k; i++) {
printf("%d ", c[i]);
}
printf("\n");
}
// 求交集函数
void getIntersection(int a[], int b[], int m, int n) {
int c[MAX_SIZE]; // 存放交集结果的线性表
int i, j, k;
k = 0; // 结果线性表 C 中已有元素的个数
// 遍历线性表 A,判断是否与线性表 B 中的元素重复
for (i = 0; i < m; i++) {
int exist = 0; // 标记线性表 A 中的元素是否与线性表 B 中的元素重复
// 判断线性表 A 中的元素是否与线性表 B 中的元素重复
for (j = 0; j < n; j++) {
if (a[i] == b[j]) {
exist = 1;
break;
}
}
// 如果线性表 A 中的元素与线性表 B 中的元素重复,则将其加入结果线性表 C
if (exist) {
c[k++] = a[i];
}
}
// 输出交集结果线性表 C
printf("Intersection: ");
for (i = 0; i < k; i++) {
printf("%d ", c[i]);
}
printf("\n");
}
int main() {
int a[] = {1, 2, 3, 4, 5};
int b[] = {4, 5, 6, 7, 8};
int lenA = sizeof(a) / sizeof(a[0]);
int lenB = sizeof(b) / sizeof(b[0]);
getUnion(a, b, lenA, lenB);
getIntersection(a, b, lenA, lenB);
return 0;
}
2.2 顺序表
顺序表与链表往期文章
顺序表实现增删查改
2.2.1 知识点提要
- 线性表的顺序存储表示
顺序表用一组连续的存储单元依次存储线性表中的数据元素,从而使得逻辑关系相邻的物理位置也相邻。
顺序表的特点是表中各元素的逻辑顺序与其物理顺序相同。
用C语言描述时,常借用一维数组来存储。 - 顺序表静态存储
#define MAX_SIZE 100
typedef int DataType
typedef struct {
DataType data[MAX_SIZE]; // 存储顺序表元素的数组
int length; // 顺序表的长度
} SeqList;
- 顺序表动态存储
#define initSize 100
typedef int DataType
typedef struct {
DataType *data;
int maxSize,length;
} SeqList;
初始化操作
data = (DataType *)malloc(sizeof(DataType)*initSize);
maxSize = initSize;
length = 0;
- 顺序表的增删查改操作的性能如下:
增加元素(Insert):在顺序表的指定位置插入一个元素。
最好情况时间复杂度:O(1),即在顺序表最后位置插入元素。
最坏情况时间复杂度:O(n),即在顺序表的第一个位置插入元素,需要将后面的元素全部后移。
平均情况时间复杂度:O(n),需要移动平均 n/2 个元素。
空间复杂度:O(1),不需要额外的空间。
删除元素(Delete):从顺序表中删除一个元素。
最好情况时间复杂度:O(1),即删除顺序表的最后一个元素。
最坏情况时间复杂度:O(n),即删除顺序表的第一个元素,需要将后面的元素全部前移。
平均情况时间复杂度:O(n),需要移动平均 n/2 个元素。
空间复杂度:O(1),不需要额外的空间。
查找元素(Search):在顺序表中查找指定元素,并返回其位置。
最好情况时间复杂度:O(1),即在顺序表的第一个位置找到元素。
最坏情况时间复杂度:O(n),即在顺序表的最后一个位置或者不存在的情况下查找元素。
平均情况时间复杂度:O(n)。
空间复杂度:O(1),不需要额外的空间。
修改元素(Modify):修改顺序表中指定位置的元素值。
时间复杂度:O(1)。
空间复杂度:O(1),不需要额外的空间。
总体来说,顺序表的增删查改操作的时间复杂度与顺序表的长度成正比。在顺序表中插入和删除操作涉及元素的移动,所以其性能随着元素数量的增加而降低。而查找和修改操作的性能不受元素数量影响,其时间复杂度为常数时间。
需要注意的是,顺序表的插入和删除操作的性能会受到内存分配和移动元素的影响,特别是当需要频繁进行扩容和缩容时。因此,在实际应用中,如果对插入和删除操作的效率要求较高,可以考虑使用其他数据结构,如链表
2.2.2 选择判断与简答归纳
顺序表存储密度高,但插入与删除的时间效率低。
2.2.3 算法编程题
顺序表实现增删查改
#include <stdio.h>
#include <stdlib.h>
typedef struct {
int* data; // 动态数组指针
int length; // 顺序表的长度
int maxSize; // 顺序表的最大容量
} SeqList;
// 初始化顺序表
void initList(SeqList *L, int maxSize) {
L->data = (int*)malloc(maxSize * sizeof(int)); // 动态分配内存空间
L->length = 0;
L->maxSize = maxSize;
}
// 在指定位置插入元素
void insertElem(SeqList *L, int pos, int elem) {
if (pos < 0 || pos > L->length) {
printf("Error: Invalid position.\n");
return;
}
if (L->length >= L->maxSize) {
// 扩容
int* newData = (int*)realloc(L->data, (L->maxSize * 2) * sizeof(int));
if (newData == NULL) {
printf("Error: Memory reallocation failed.\n");
return;
}
L->data = newData;
L->maxSize *= 2;
}
for (int i = L->length; i > pos; i--) {
L->data[i] = L->data[i - 1]; // 元素后移
}
L->data[pos] = elem;
L->length++;
}
// 删除指定位置的元素
void deleteElem(SeqList *L, int pos) {
if (pos < 0 || pos >= L->length) {
printf("Error: Invalid position.\n");
return;
}
for (int i = pos; i < L->length - 1; i++) {
L->data[i] = L->data[i + 1]; // 元素前移
}
L->length--;
}
// 根据值查找元素的位置
int findElem(SeqList L, int elem) {
for (int i = 0; i < L.length; i++) {
if (L.data[i] == elem) {
return i;
}
}
return -1;
}
// 修改指定位置的元素值
void modifyElem(SeqList *L, int pos, int newValue) {
if (pos < 0 || pos >= L->length) {
printf("Error: Invalid position.\n");
return;
}
L->data[pos] = newValue;
}
// 输出顺序表中的所有元素
void displayList(SeqList L) {
printf("SeqList: ");
for (int i = 0; i < L.length; i++) {
printf("%d ", L.data[i]);
}
printf("\n");
}
// 释放顺序表占用的内存
void destroyList(SeqList *L) {
free(L->data); // 释放动态分配的内存空间
L->data = NULL;
L->length = 0;
L->maxSize = 0;
}
int main() {
SeqList list;
initList(&list, 5);
insertElem(&list, 0, 1);
insertElem(&list, 0, 2);
insertElem(&list, 1, 3);
insertElem(&list, 2, 4);
displayList(list); // SeqList: 2 3 4 1
deleteElem(&list, 1);
displayList(list); // SeqList: 2 4 1
int pos = findElem(list, 4);
if (pos != -1) {
printf("Element found at position %d.\n", pos);
} else {
printf("Element not found.\n");
}
modifyElem(&list, 0, 5);
displayList(list); // SeqList: 5 4 1
destroyList(&list);
return 0;
}
2.3 线性表的链式存储表示
数据结构:链表
2.3.1 知识点提要
- 线性表的链式存储表示
线性表的链式存储表示是指用指针来表示线性表的存储方式,链式存储结构由若干个节点组成,每个节点包含数据域和指针域。数据域用来存储数据元素,指针域用来存储指向下一个节点的指针。
结点所占用的存储空间连续的,但结点之间在空间上可以连续也可以不连续,逻辑相邻,但物理上不一定相邻。
具体来说,链式存储结构可以分为单链表、双向链表和循环链表。
单链表:每个节点只有一个指针域,指向下一个节点。
双向链表:每个节点有两个指针域,一个指向前驱节点,一个指向后继节点。
循环链表:尾节点的指针域指向头节点,形成一个环。
链式存储结构相比于顺序存储结构的优点在于可以动态调整存储空间,插入和删除元素的时间复杂度为O(1),但查找某个元素的时间复杂度为O(n)。因此,链式存储结构适合于数据频繁插入和删除的情况。
- 种链表的性能比较主要涉及到插入、删除和查找操作的效率问题。下面是常见链表的性能比较:
单链表(Singly Linked List):
插入:在指定位置插入元素需要遍历链表,时间复杂度为O(n),其中n是链表的长度。
删除:在指定位置删除元素需要先找到前一个节点,时间复杂度为O(n)。
查找:根据值查找元素的位置需要遍历链表,时间复杂度为O(n)。
双向链表(Doubly Linked List):
插入:在指定位置插入元素需要找到前一个节点,时间复杂度为O(n)。
删除:在指定位置删除元素需要找到前一个节点,时间复杂度为O(n)。
查找:根据值查找元素的位置需要遍历链表,时间复杂度为O(n)。
循环链表(Circular Linked List):
在循环链表中,最后一个节点的指针指向头节点。
插入:在指定位置插入元素需要遍历链表,时间复杂度为O(n)。
删除:在指定位置删除元素需要找到前一个节点,时间复杂度为O(n)。
查找:根据值查找元素的位置需要遍历链表,时间复杂度为O(n)。
静态链表(Static Linked List):
静态链表使用数组来模拟链表的结构,通过数组中元素的索引来表示节点之间的关系。
插入:在指定位置插入元素需要移动其他元素,时间复杂度为O(n)。
删除:在指定位置删除元素需要移动其他元素,时间复杂度为O(n)。
查找:根据值查找元素的位置需要遍历链表,时间复杂度为O(n)。
总体而言,各种链表的插入、删除和查找操作的时间复杂度都为O(n),其中n是链表的长度。因此,在选择链表的时候,应根据实际需求综合考虑各种链表的特点和对操作的性能要求。
2.3.2 选择判断与简答归纳
- 链表不可随机访问任何一元素。