文章目录
- 前言
- 修改点
- Preprocess
- Inference
- 另一种方法,work了。
- 一个难点,它走到了这里
- 业务化修改
- 总结
前言
之前写个yolov8的一个试用版,【深度学习】Yolov8追踪从0到1, 这要是做计数啥的,简单的一批,一套工程化的代码,给自己挖了个坑,说要实现一个基于yolov8的人/车流量统计.
现在要改进,想要做成能够处理多摄像头的,也就是多个摄像头共享一个算法来处理计数。
修改点
先修改最重要的点,前处理、推理和后处理,主要是吧原来单图片,修改成多图片的入参。yolov官方工程的track.py 注释的很清楚。Preprocess/Inference/Postprocess.

改造的整体思路是要搞清楚:
- 原输入是什么
- 原输出是什么
- 期望输入是什么
- 期望输入套到原方法是否工作良好
- 期望输出是什么
Preprocess
看150行
im0s 一个list,[array([[[125, 118, 1…ype=uint8)]
看一眼它的形状:HWC
im0s[0].shape
(1080, 1920, 3)
其输出im
im.shape
torch.Size([1, 3, 384, 640])
它的作用是将list的array 转成 torch.Tensor对象,并且转成BCHW的形状,注意这里应该是resize了,将最长边1920–>640,而短边等比例缩放到了384;
正常应该缩放到360,但不知道为啥它输出了384.(待定??)
经测试,im0s 输入修改成 [array([[[125, 118, 1…ype=uint8),array([[[125, 118, 1…ype=uint8)] 输出为:torch.Size([2, 3, 384, 640]) 满足预期。
Inference
来到了154行
input: im
im.shape
torch.Size([1, 3, 384, 640])
output:preds

preds[0]
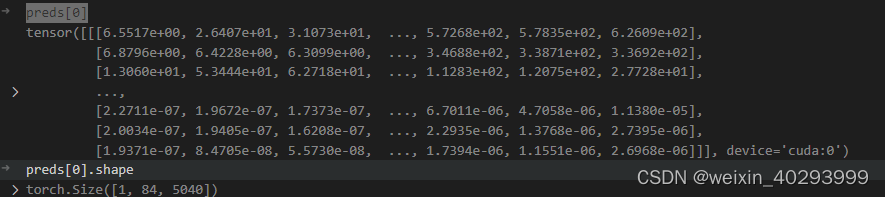
对于yolov8的结构和输出解析看这里ref:https://zhuanlan.zhihu.com/p/598566644
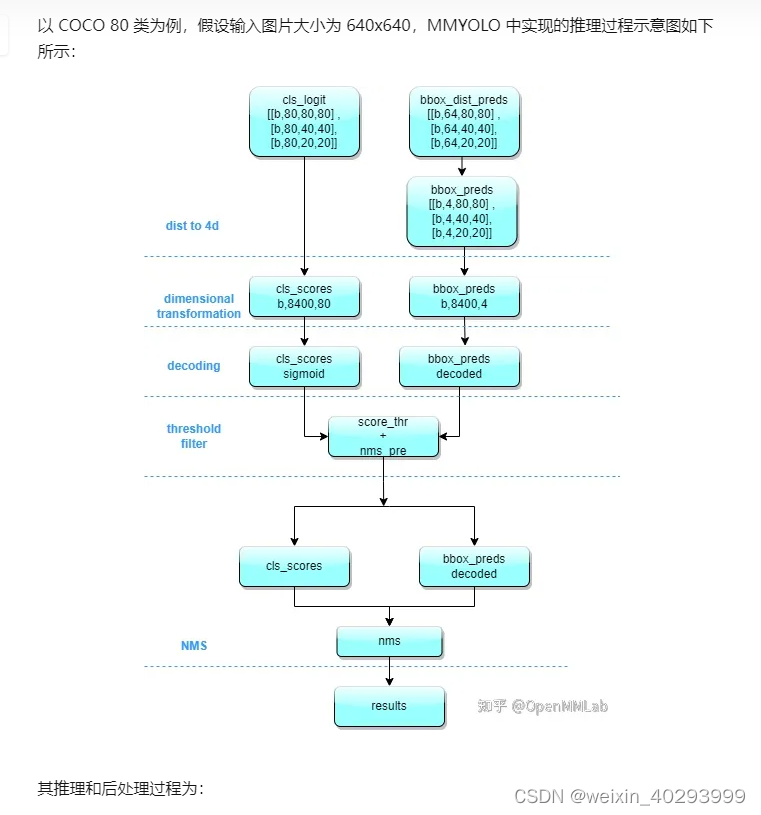
preds[0]是一个tensor, 第一维度是 bz,第二维度是 80类和矩形框位置,第三维度未知(todo)应该是融合后的特征,正常来说若输入图片是640640 则是8400=(8080 + 40*40 + 20 *20),这个知乎的解读也不一定对,起码和我打印的结果不一致。
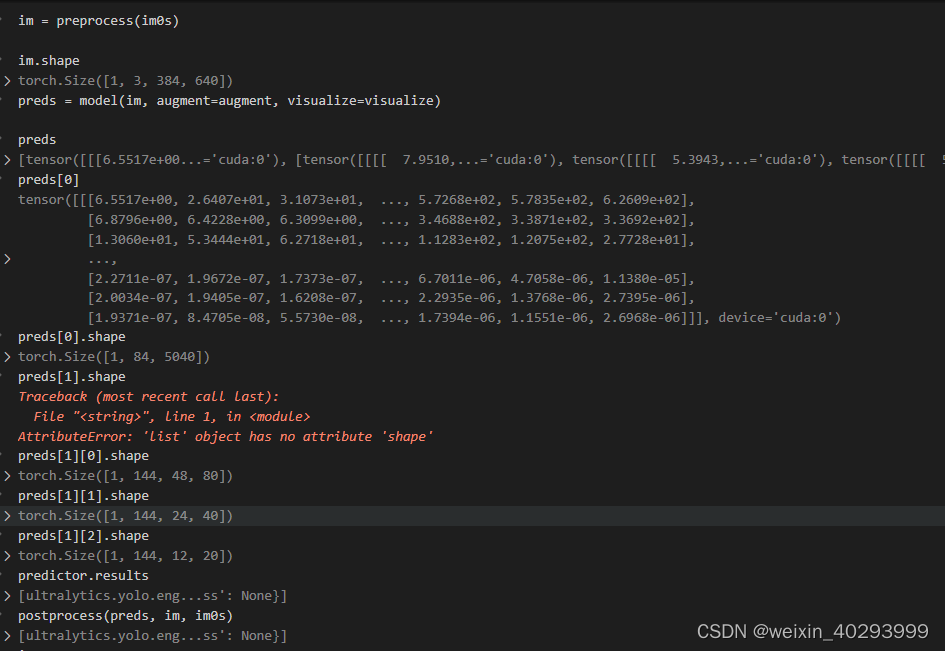
bz = 1 是可以跑出来的。
bz = 2 的时候,前两步没问题,到第三步就出问题了,跑不出来。
因为vscode 无法debug到python 环境路径的拓展包里:需要debug到/home/jianming_ge/miniconda/envs/xxx/lib/python3.9/site-packages/ultralytics/yolo/engine/model.py这里。
所以这个方法凉了。
另一种方法,work了。
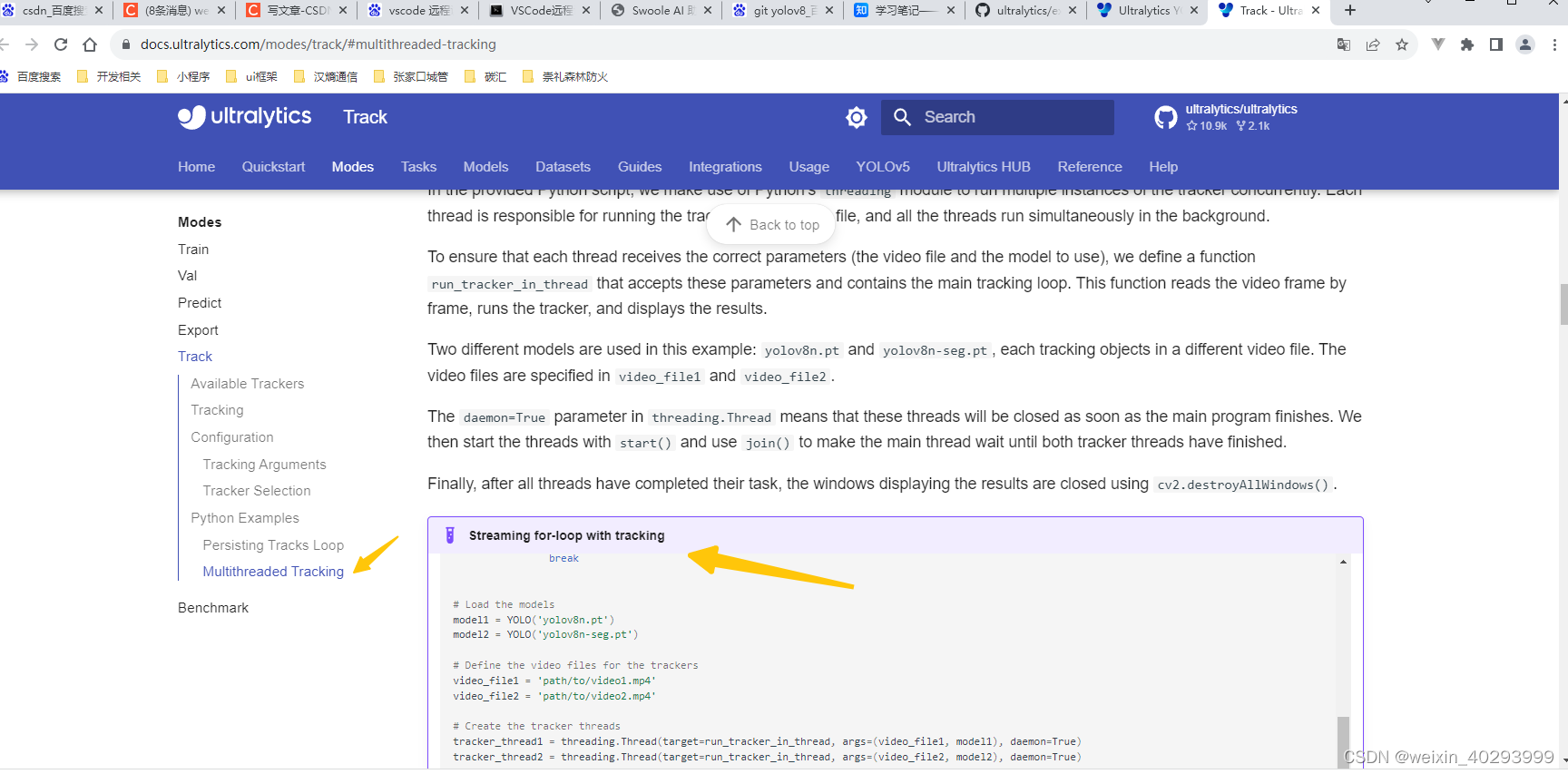
ref:https://docs.ultralytics.com/modes/track/#multithreaded-tracking
这是yolov8 官方的case,藏的很深。我是三连跳找到的。
https://github.com/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb—>
https://docs.ultralytics.com/tasks/ -->
https://docs.ultralytics.com/modes/track/#multithreaded-tracking
import threading
import cv2
from ultralytics import YOLO
def run_tracker_in_thread(filename, model):
video = cv2.VideoCapture(filename)
frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
for _ in range(frames):
ret, frame = video.read()
if ret:
results = model.track(source=frame, persist=True)
res_plotted = results[0].plot()
cv2.imshow('p', res_plotted)
if cv2.waitKey(1) == ord('q'):
break
# Load the models
model1 = YOLO('yolov8n.pt')
model2 = YOLO('yolov8n-seg.pt')
# Define the video files for the trackers
video_file1 = 'path/to/video1.mp4'
video_file2 = 'path/to/video2.mp4'
# Create the tracker threads
tracker_thread1 = threading.Thread(target=run_tracker_in_thread, args=(video_file1, model1), daemon=True)
tracker_thread2 = threading.Thread(target=run_tracker_in_thread, args=(video_file2, model2), daemon=True)
# Start the tracker threads
tracker_thread1.start()
tracker_thread2.start()
# Wait for the tracker threads to finish
tracker_thread1.join()
tracker_thread2.join()
# Clean up and close windows
cv2.destroyAllWindows()
案例代码中model1 和 model2 用的模型不一样,一个检测,一个分割。其实两个也可以用检测。-----------这里有问题, todo
这是解决了追踪的问题,计数其实是对追踪的业务化。我另外的blog文章已经说明了。
这里还需要注意一点:
model1 = YOLO('yolov8n.pt')
model2 = YOLO('yolov8n-seg.pt')
这个方式若当前路径权重文件不存在,会把权重下载到当前目录,也可以指定路径,比如:
这个记录是在yolov5 vs yolov8的训练那篇文章的案例的代码。
from ultralytics import YOLO
model = YOLO('./yolov8m.pt')
model.train(data='data/firesmoke.yaml', epochs=500, imgsz=640, device=[0,1],save_period=20,workers=8,batch=24)
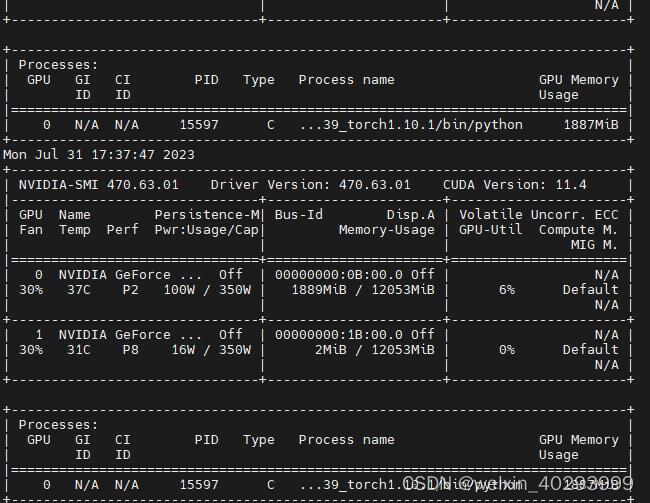
即使我用两个视频源做输入,跑了两个模型,可以看到所占的显存也不多。


一个分割,一个检测的模型,看起来还不错,用的是
发现问题:
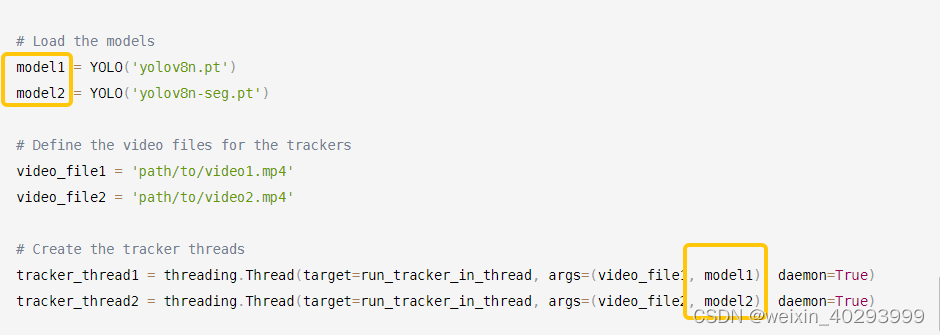
这种方式其实是启动了多个model算法, 公用model1会出错,所以不是一个理想的方案。报错我也贴一下:
理想的方案应该是,比如四个摄像头,bz=4来实现目标检测/分割只用一个模型,追踪各走各的,才是一个好方案! todo。
一个难点,它走到了这里
业务化修改
待续
总结
参考:
git:https://github.com/MuhammadMoinFaisal/YOLOv8-DeepSORT-Object-Tracking
git:https://docs.ultralytics.com/modes/track/#multithreaded-tracking
blog:https://blog.csdn.net/liuxuan19901010/article/details/130555216