第四弹
一、💛
主键约束(Primary key):
通过这个约束来指定某一个列作为主键(1.非空,2.不能重复) ,主键:一条数据,身份标识(类似于内存地址)
😄😄使用方法:想好某一列了,就在建立表的后面加上primary key
正如下图,他不可以插入值是空的值
那么我们进行数据插入的时候怎么能保证数据不重复呢,一个一个记住或者一个一个尝试都过于麻烦,所以产生了“自增主键” 😈 😈 😈
自增主键:往往是一个整数的ID,要求不可以重复,SQL优化客户端,在插入数据的时候,不主动指定主键的值,而是交给MySQL自行分配,确保分配成功
😄😄使用方法:在某一列的后面加上primary key auto_increment
insert into student values(null,'xx');
null是表示,他去自动安排一个不重复的。
当然了假如你想要自己去决定插入几号几号(主键),也是可以插入的,但是假如插入后,再用null让mysql给我们插入下一个会怎么样呢,看下图
他会接着你的 最大值插入,当然有人会说中间怎么办,这样不会有浪费吗,浪费就浪费呗,无所谓不用患得患失



❗️ ❗️ ❗️
最大值这个问题说一下:
假如是单个节点,没有什么问题。
但是如果mysql是分布式系统,(不同电脑硬件不同,会多台电脑配合使用就叫分布式系统)不同的电脑只记得自己电脑的mysql的最大值,所以这个时候有可能出现重复情况。
补充一下:电脑四大件:CPU,内存,硬盘,网络带宽(一个机器的容量有限,所以加主机数量,可以解决问题)
分布式解决这个问题有特殊方法:
(ID生成算法)可以解决这个问题,这个算法的目标就是保证每个ID唯一
分别由1.主机编号 2.时间戳(小概率同一时间毫秒)3.随即因子,这样由这三个决定的字符ID就可以保证分布式系统唯一性。
二、💙
外键约束
创建外部约束的时候分为父表和子表
注意:受外部约束的时候,也是子表改,父表不改
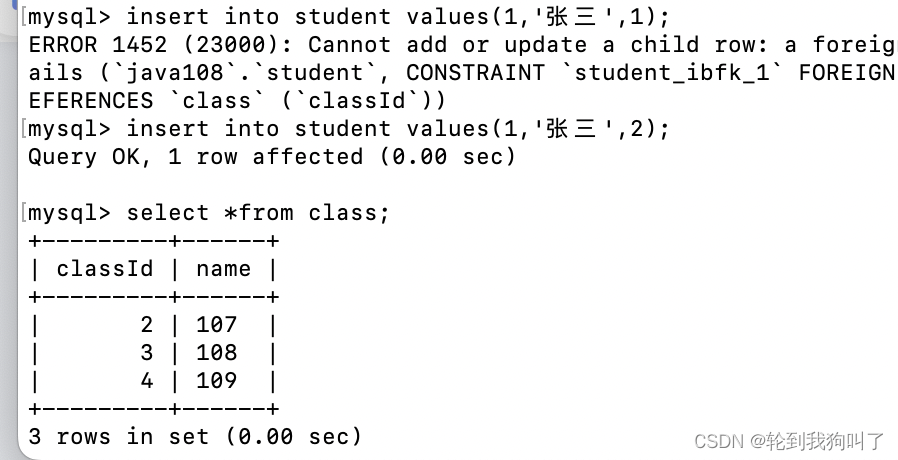
class为父表,student为子表,
create table student(studentId int primary key auto_increment,name varchar(20),classId int,foreign key (classId) (他的意思是当前表的那一列受到约束) references class(classId)(class:表示起到约束作用的父表,classId起到约束作用的父表哪一列));
插入或者修改自表中受约束来的数据,就必须保证,插入/修改后的结果,必须要在父表中存在。
如下图:我们在class里面序号是2,3,4,所以我们student表中不能存在父表中没有的比如1.(constraint:是约束的意思)
注意⚠️
1.针对带有外键约束的插入或者修改,会自己触发查找,看父表有没有。
2.但约束也是双向的,删除或者修改父表中的记录,要看是否被子表使用了(假如使用了,不可以进行修改或者删除)
如下图
3.父类的ID要+unique或者primary
(原因:索引!!
我们在设置外键的时候就会导致操作子表中,频繁查父表,这一个操作,非常耗时间,为了加快查询速度,如果父亲表中(ID这一列就索引就会非常香,primary,unique自带索引),因此约定:没有索引,不能建立这样的外键



三、💜
逻辑删除:
考虑一个场景:建立电商平台 首先分为两块(商品表,订单表)
订单表中的商品要确保商品表中存在(适用于外部约束)
1.实现功能商品下架功能,之前买过某个东西,订单中存在数据,想再来一个,商品中却没有了,假如要删除之类的太麻烦,而且只是下架又不是永远不上了,删除到时候还要添加
所以设置商品表(id ,name,price,ok)(实现商品下架就用update把商品表的ok改成0,获取商品列表,就select的时候加一个条件,and ok=1。(ok=1是商品架子上有的)
这也叫逻辑删除(如同我们之前的线性表,删除是size--,而不是释放空间,很常用)
💤💤💤
下面这个不咋重要,看着玩
check:
某一列要遵守一个具体的表达式,当前的记录符合条件,就是可以插入修改,不符合就会失败,但是mysql5不支持check。
表的设计(设计,依赖一定的经验)。
实体和关系,设计表的时候需要搞清楚
实体->对象从需求场景,提炼出一些关键性质名词(关系是实体和实体之间关联关系)
关系大体分为四种:
1.一对一:教务系统,一个学生一个号,一个号归一个学生有
分成三种写法:
(1).student (id,name,classId)
account(accountId,userName,studentId);
(2).student(id,name,accountId)
account(accountId,userName)
(3).student(id,name,age,username,accountId) 这个是合成一个表混一起弄
2.一对多:一个同学,只存在一个班级中,一个班级可包含多个同学
(1).student(studentId ,name)
class(classId,className,students) (students这里面包含多个学生ID)
⚠️⚠️⚠️这么写(mysql)并不推荐,mysql这种类型,不提供“数组”此处要是这么做要按一定的格式,把多个studentId拼成一个字符串,这个过程繁琐且低效。但有些数据库比如(redis)支持数组这样的类型。
(2).class(classId,className)
student(studentId,name,classId) (换成学生在班级,而不是班级有学生)
3.多对多:一个学生多门课,多门课多个学生(查找成绩)。
(1).course(id,name)
student(id,name)
此时我们需要生成一个关联表
student_course(studentId,courseId)(1号学生选择的语文数学,成绩,这里也就是简写,更具体就自己添加)
4.无关系:没用
上述的1,2,3关系要了解每种关系,表的设计情况(固定套路,很常见,如同(出炮上马一样)
四、 ❤️
新增(把insert和select合并到一起)
把select 查询出来的结果数据,插入另一表中
就是正常插入后面去掉values换成select*表;
如:我么能看见,插入是给student插入的,但是studnet2却也有了student的插入

五、💚
聚合查询:
(查询的时候带表达式是列与列之间的计算,但是假如说行与行就有些无能为力,所以这里出现了聚合查询)
聚合函数
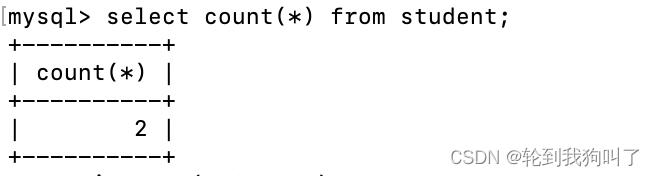
count():查询有多少行数据
使用方法:select count(*)from student
⚠️⚠️注意:*和我们正常的列得出的结果不同 ,*的话NULL也算行,但是列的话不算NULL
!!!其次count和(*)之间不可以有空格,大部分的编程语言空格无所谓,但是python,CSS,SQL有奇怪要求
sum():返回数据总和)
把这一行的数据按照double累加,(尝试先把数据转化为double)
当然也有转化不成的情况,但是他不会报错,会报警告
这个操作是来查看警告的:show warnings
avg():返回查询数据的平均值
max():返回查询数据的最大值
min():返回查询数据的最小值



第五弹
一、💓
数据库的设计
要以敏捷和迭代-需求一直在变
实际的敏捷开发,需要持续集成
持续集成,就是保证新开发的功能点能快速稳定的合并到已有的功能中
1.代码能快速合并进去
2.快速的测试(自动化测试=已有的功能+新的功能)
3.快速发布
这三部就是国内有名的模式——小步快跑
二、 💕
分组查询:有时候要把数据分成多组,进行运算
分组查询中,select 指定的是列,必须是group by 指定的列,如果select中想用到其他的列,其他列必须放到聚合函数中,否则直接写没有什么意义
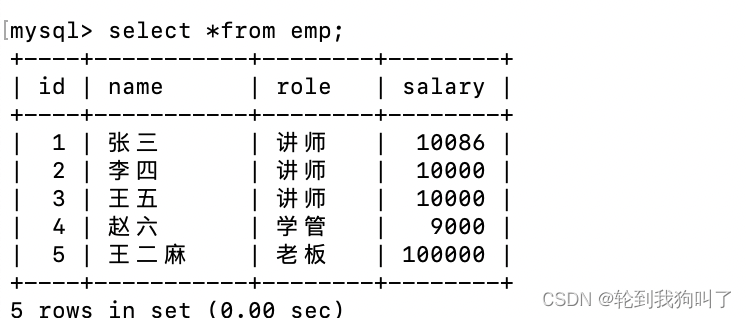
分组查询,也可以搭配条件使用
1.分组之前:where :
对比来看where是先去掉了讲师中的一个10086
2.分组之后:having(先是给他搞平均薪资,然后减去这个最大的,这个老板的平均薪资)
3.一个SQL可以包含分组前和分组后的语句
下面的语句:先是不等于张三,再是按照role分组,在select role 最后是having<20000
实际上我们确实会使用一些复杂的SQL,但是我们平时最好不要写复杂的SQL,这个可读性太差了




三、💘
连表查询
笛卡尔积:描述了多个表查询的基本执行逻辑(那么什么叫笛卡尔积呢?)
任何两张表都可以用笛卡尔积,但是两个表假如没有关系,计算出来也没有意义。
笛卡尔积像是两个表的乘积,
我们通过上面两张图来看下图,可以观察到有很多不正确的数据,这时候就需要我们找条件去筛选哪些数据是正确的
⚠️⚠️缺点:笛卡尔积比较低效(多表联合查询就很低效),尤其是数据较多的情况下,所以使用它也需要注意,容易把数据库干停机咯。很多慢的sql都是使用这些联表查询。
笛卡尔积的用途
笛卡尔积的用途:
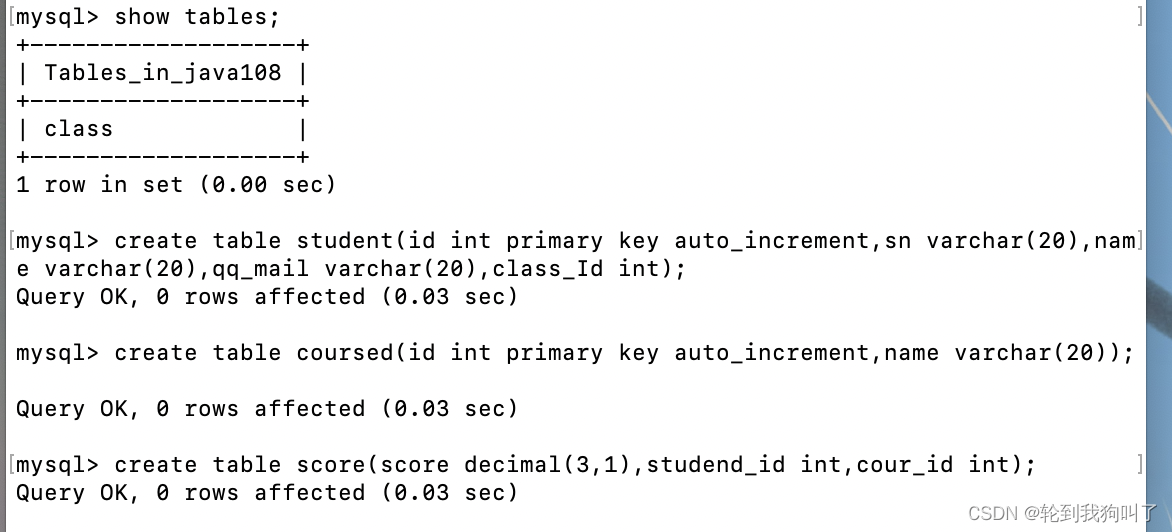
建立四个表
class(id,name,desc(留作备用的串用来匹配)
id :用于存储班级的唯一标识符,设置为主键,并使用 auto_increment 自增。
name :用于存储班级的名称,设为 varchar 数据类型,最大长度为 20。
desc :用于存储班级的描述,设为 varchar 数据类型,最大长度为 100。需要注意的是, desc 是 SQL 保留字,表示降序排序的关键字,因此需要将其用反引号 ` 包裹起来,以作为列名使用。)
student(ID,sn(备用),name qq_mail,class_id)
id :用于存储学生的唯一标识符,设置为主键,并使用 auto_increment 自增。
sn :用于存储学生的学号,设为 varchar 数据类型,最大长度为 20。
name :用于存储学生的姓名,设为 varchar 数据类型,最大长度为 20。
qq_mail :用于存储学生的 QQ 邮箱,设为 varchar 数据类型,最大长度为 20。
class_Id :用于存储学生所属的班级的标识符。需要注意的是, class_Id 列作为外键关联到某个班级表上。如果你要设置外键关系,需要先创建班级表,然后在创建学生表时使用 foreign key 语句来关联到班级表的相应列上。
下面这两个就字面意思不用解释。
coursed(id,name);
score (score ,student_id,class_id);
改一下哈



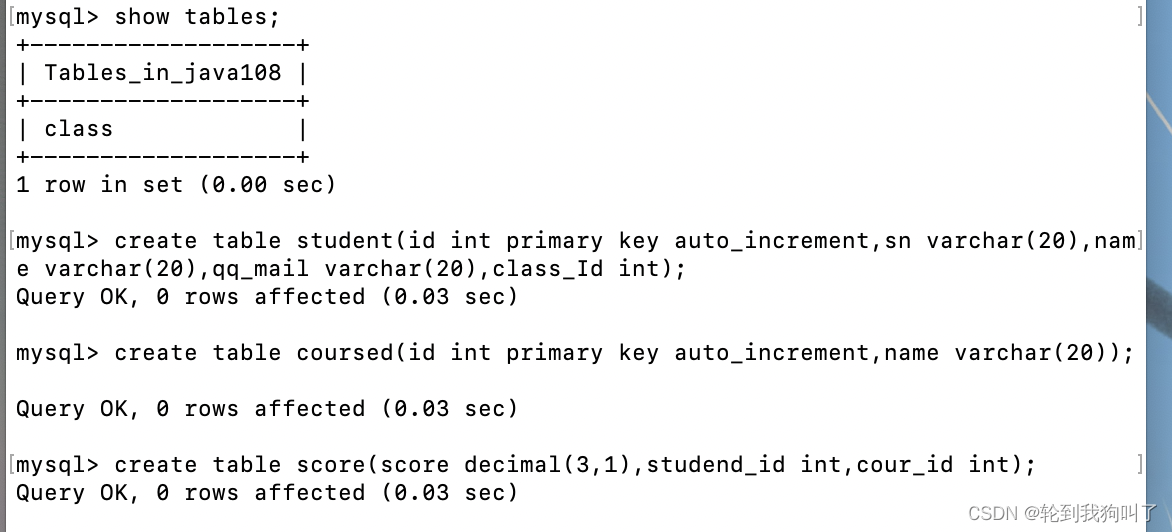

四张表


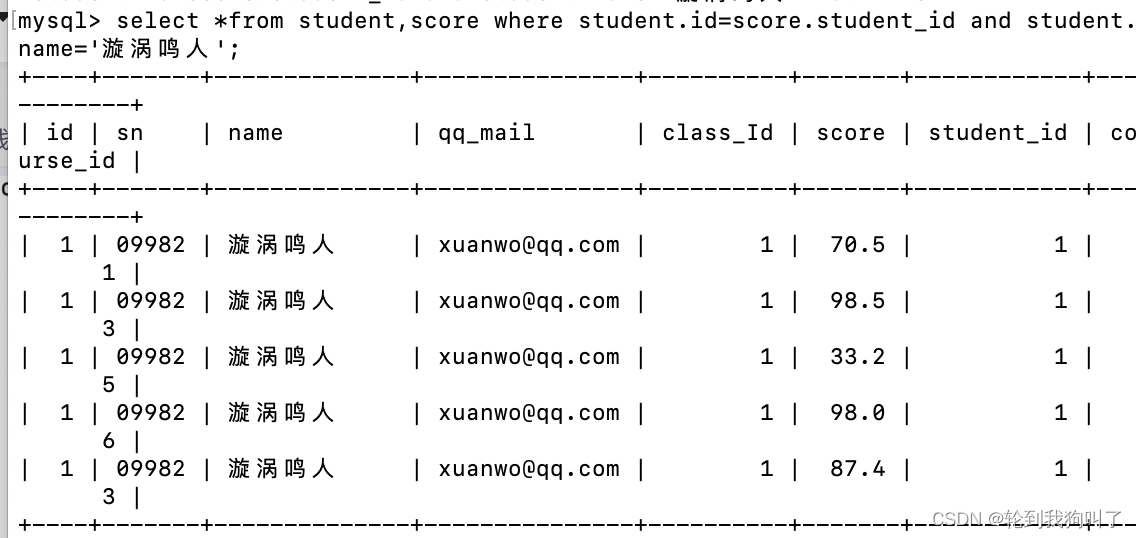
假如说要查询漩涡鸣人同学的成绩
首先许仙来自:student
成绩来自:score。需要联合查询,
(1).先用笛卡尔积
(2).过滤不正确的结果,指定连接条件进行筛选。
(3).只关注鸣人,进一步筛选
(4).只关注特定的行和列,进行精简处理


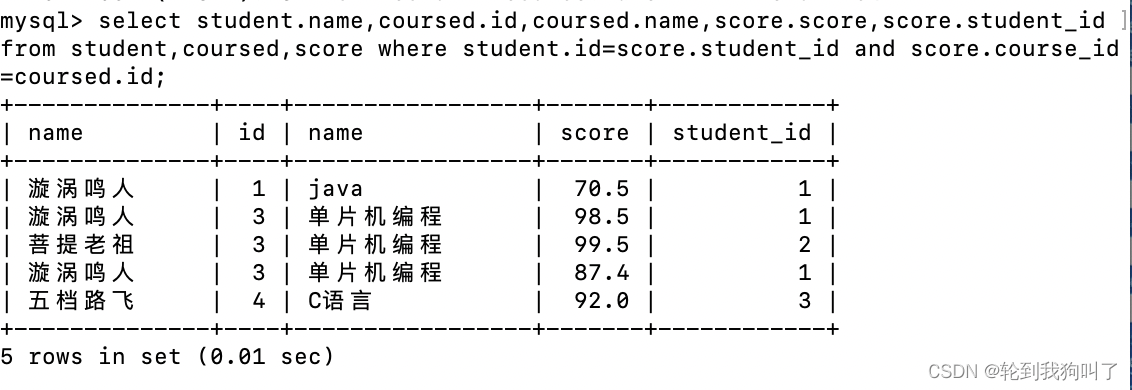
假如查询所有同学的成绩,及个人信息,列出同学的名字,课程名字,分数来组织
同学:student
课程名字:course
分数:score
(1).三个表先笛卡尔积(遇事不决,笛卡尔积)
(2).指定条件
想清楚一件事哈:执行笛卡尔积电脑上其实很快的,但是显示半天才结束,是因为慢在显示,这个是控制台打印的锅。
(3)具体罗列条件,如下图

当然我们针对一些东西,可以起别名
select student name as studentName cour.name as courseName,score.score from student,score,course where···(简写,就是回顾一下,了解这个,怎么起别名就好)
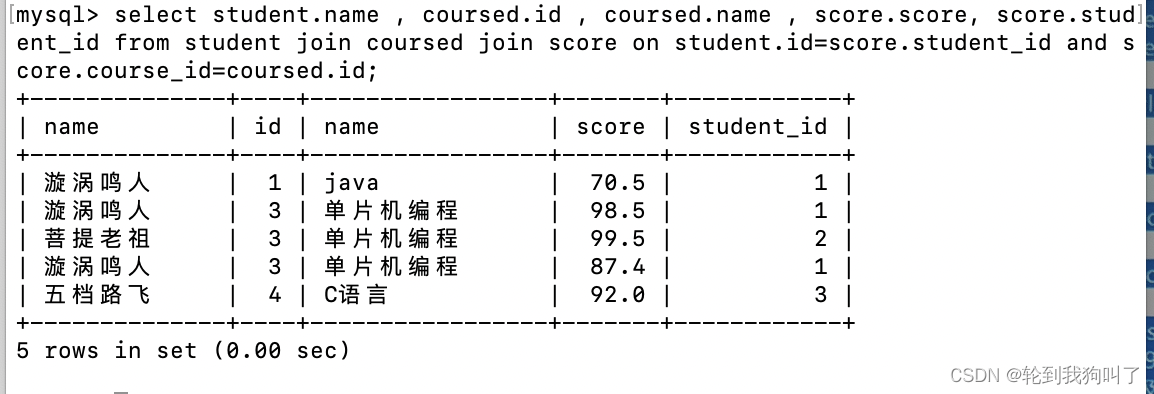
上面的是内连接的方法1
下面是内连接的方法2:大同小异 多了个inner(可以省略,了解就好),join 前面多个表,分割现在用join(相当于逗号)分割,只写join不写on是完整的笛卡尔积,on表示连接条件⚠️⚠️⚠️join是在连接表的时候,前面还是要用逗号,join只是在连接表的时候相当于逗号。
四、💖
外连接
使用的是 (查询任意操作)表 left/right join 表
student(id,name)
score(studentId ,score)
假如此时左侧表中每一条有记录,都可在右侧有对应,则内外连接没有区别,但是一旦两个表对不上,内外连接就会有所不同
正如我上面的许仙之类的,在score中没有他。
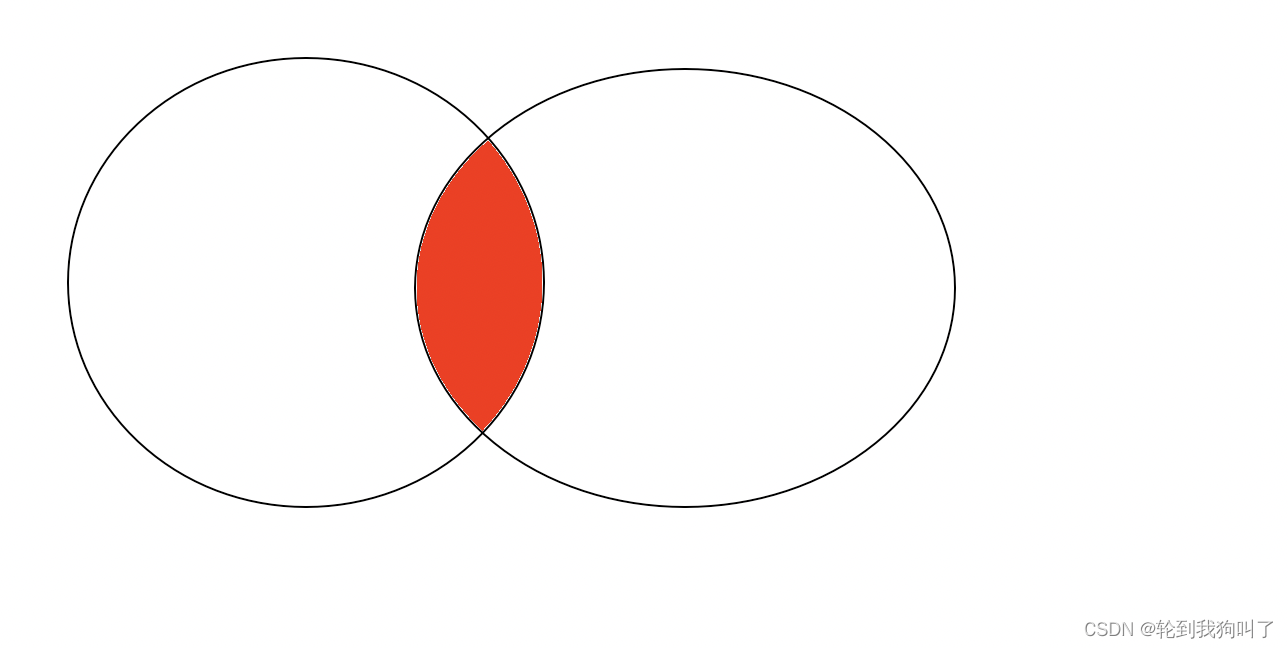
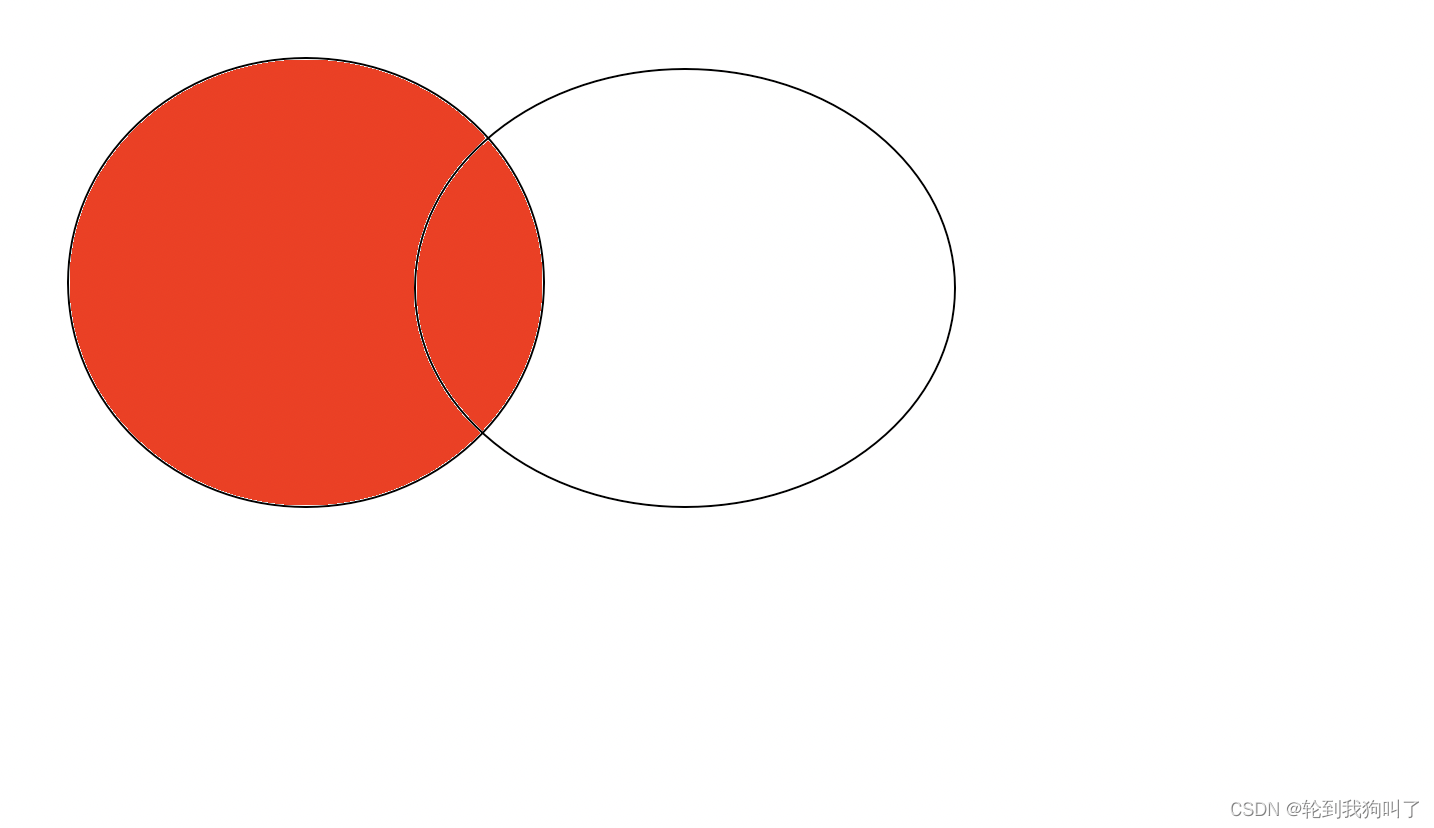
内连接的结果一定是两个表中都存在的数据(公共部分):如下图
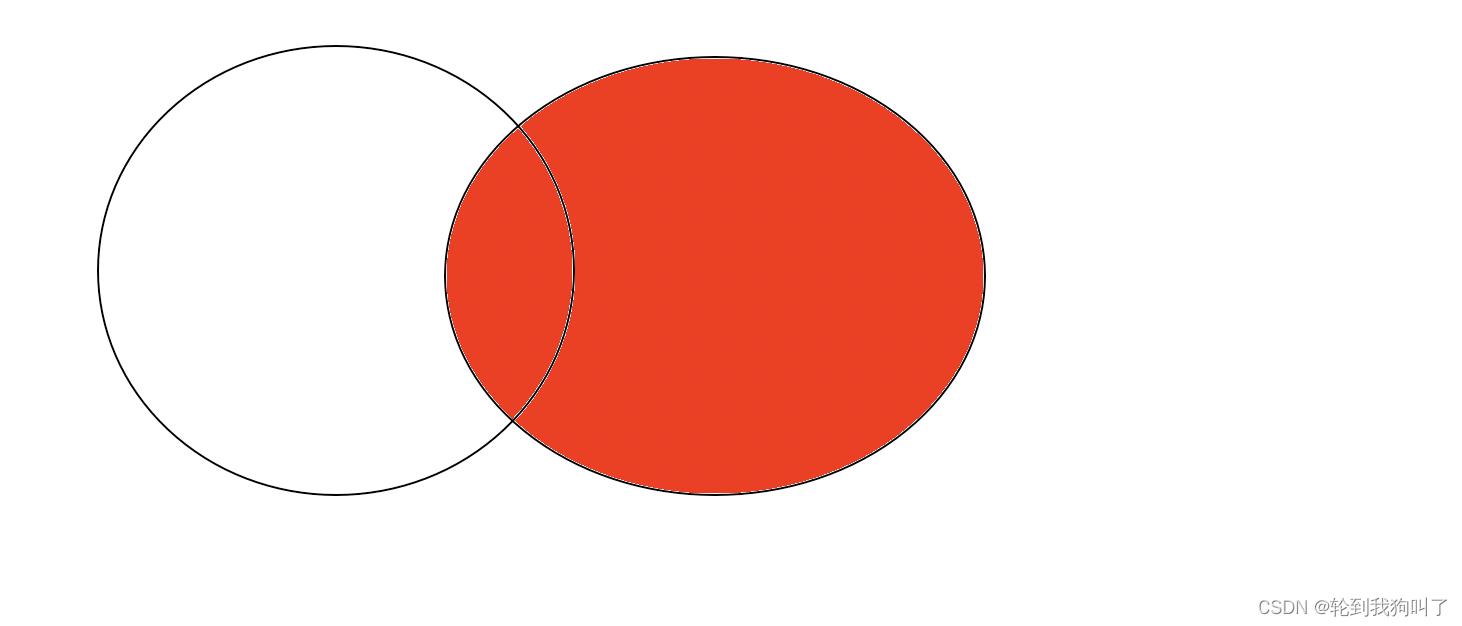
左外连接,以左侧表为主,右侧表的每个记录,都会存在最终结果里,如果左侧表存在,右侧表不存在的数据,就会把对应的列填成空值
右外连接,以右侧表为主,左侧表的每个记录,都会存在最终结果里,如果右侧表存在,左侧表不存在的数据,就会把对应的列填成空值
全外连接(outer join)-(mysql不支持,但是oracle支持)
我们在平时,尽量不写复杂的SQL,否则把SQL拆出来优化,本身是一件非常复杂的事情,只可以彻底重构。



![[Round#14 Illuminate with your bril]](https://img-blog.csdnimg.cn/a3ca2d9e3f8745d49cf78412f382e881.png)