目录
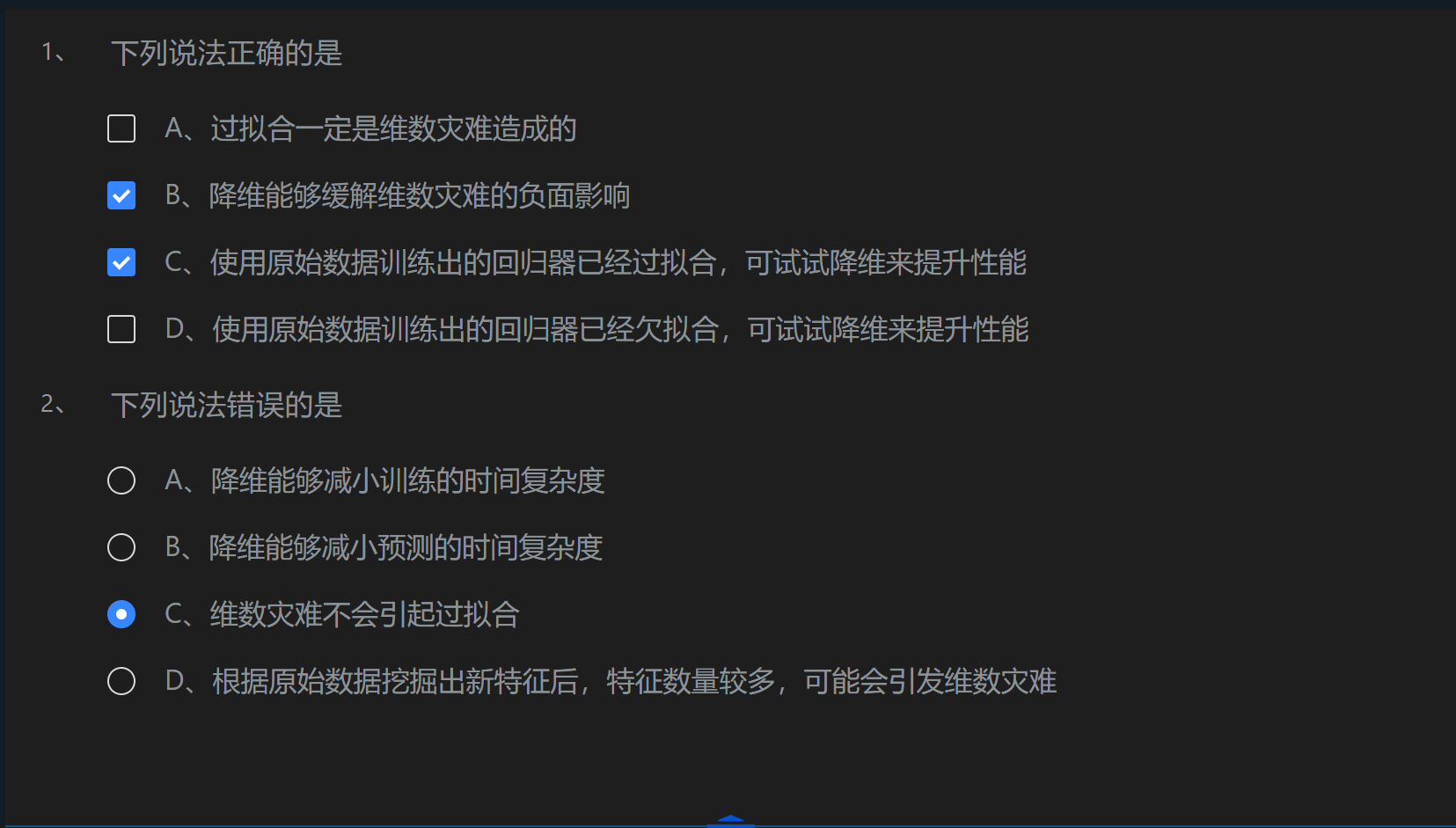
第1关:维数灾难与降维
第2关:PCA算法流程
任务描述
编程要求
测试说明
第3关:sklearn中的PCA
任务描述
编程要求
测试说明
第1关:维数灾难与降维
第2关:PCA算法流程
-
任务描述
本关任务:补充 python 代码,完成 PCA 函数,实现降维功能。
-
编程要求
在 begin-end 之间填写pca(data, k)函数,实现 PCA 算法,要求返回降维后的数据。其中:
data :原始样本数据,类型为 ndarray;
k :需要降维至 k 维,类型为 int。
-
测试说明
只需完成 pca 函数即可,程序内部会调用您所完成的 pca 函数来进行验证。以下为其中一个测试用例(其中 data 部分表示原始样本数据,k 表示需要降维至 k 维):
测试输入:
{'data':[[1, 2.2, 3.1, 4.3, 0.1, -9.8, 10], [1.8, -2.2, 13.1, 41.3, 10.1, -89.8, 100]],'k':3}
预期输出:
[[-6.34212110e+01 6.32827124e-15 1.90819582e-17]
[ 6.34212110e+01 -6.32827124e-15 2.02962647e-16]]
开始你的任务吧,祝你成功!
第3关:sklearn中的PCA
-
任务描述
本关任务:你需要调用 sklearn 中的 PCA 接口来对数据继续进行降维,并使用 sklearn 中提供的分类器接口(可任意挑选分类器)对癌细胞数据进行分类。
-
编程要求
在 begin-end 之间填写cancer_predict(train_sample, train_label, test_sample)函数实现降维并对癌细胞进行分类的功能,其中:
train_sample :训练样本,类型为 ndarray;
train_label :训练标签,类型为 ndarray;
test_sample :测试样本,类型为 ndarray。
-
测试说明
只需返回预测结果即可,程序内部会检测您的代码,预测 AUC 高于 0.9 视为过关。
开始你的任务吧,祝你成功!
from sklearn.decomposition import PCA
from sklearn.ensemble import RandomForestClassifier
def cancer_predict(train_sample, train_label, test_sample):
'''
使用PCA降维,并进行分类,最后将分类结果返回
:param train_sample:训练样本, 类型为ndarray
:param train_label:训练标签, 类型为ndarray
:param test_sample:测试样本, 类型为ndarray
:return: 分类结果
'''
#********* Begin *********#
train_x = train_sample
train_y = train_label
clf = RandomForestClassifier()
clf.fit(train_x, train_y)
predictions = clf.predict(test_sample)
#********* End *********#
return predictions
![神经网络基础[ANN网络的搭建]](https://i-blog.csdnimg.cn/direct/6e73093fdb384490b9c46d9f226c9ba4.png)