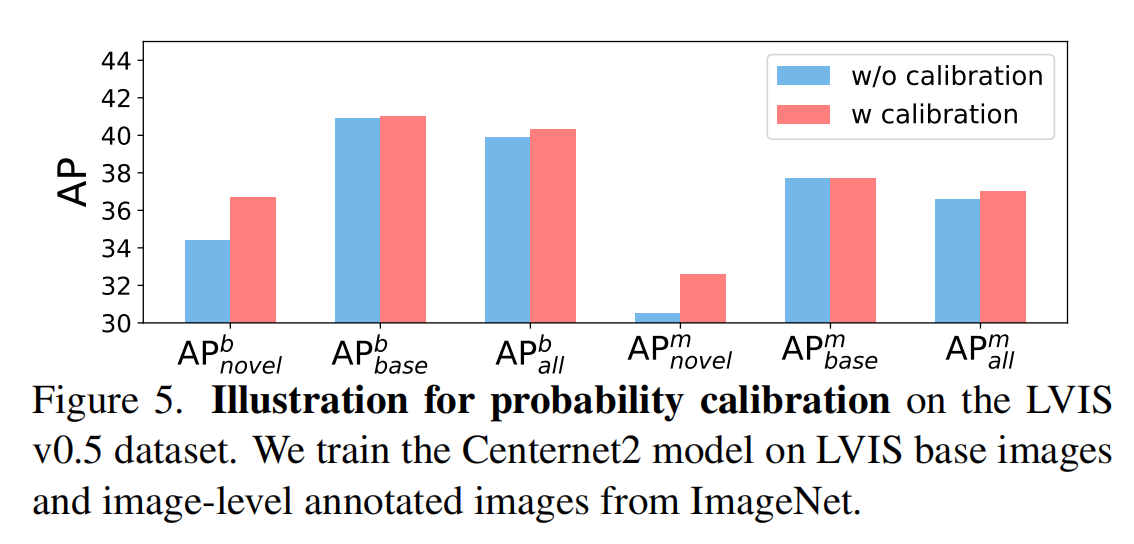
查看进程指令proc/ps/top
注意哦, 我们经常使用的指令, 像ls, touch…这些指令在启动之后本质上也是进程
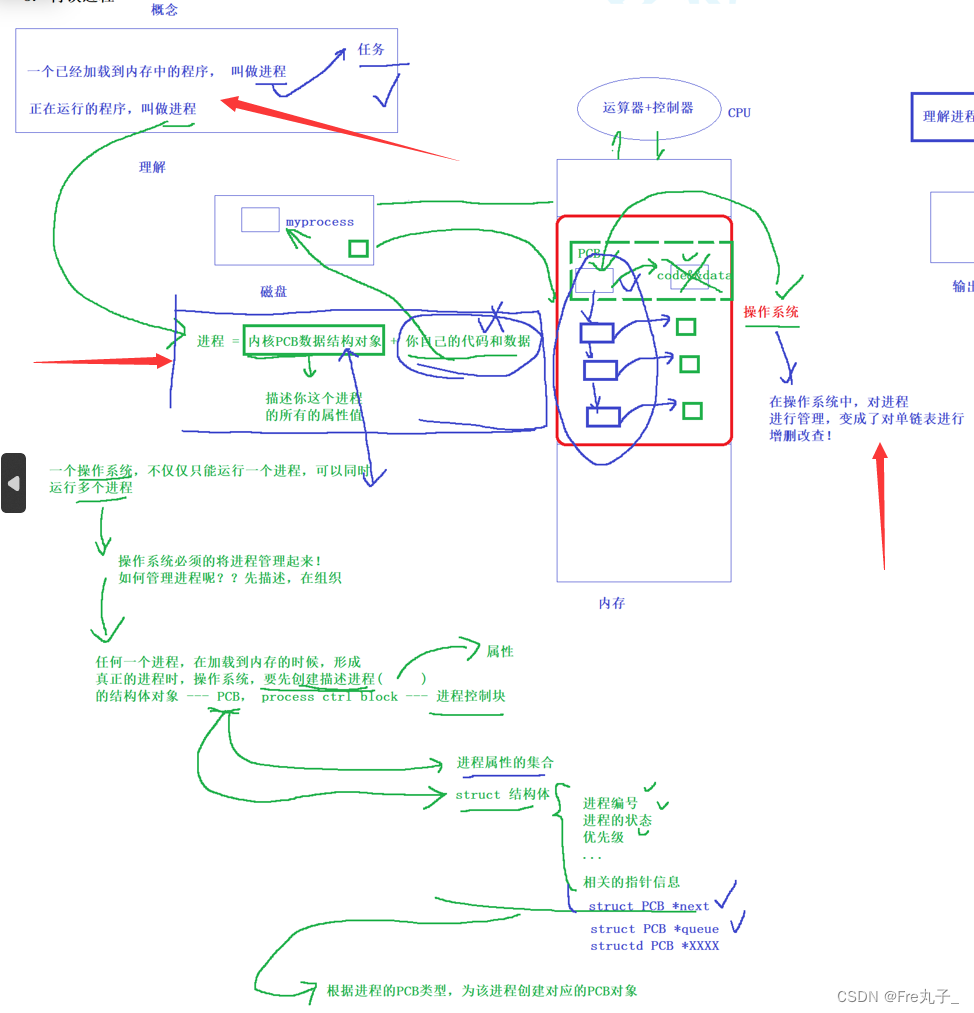
proc 是内存文件系统, 存放着当前系统的实时进程信息. 每一个进程在系统中, 都会存在一个唯一的标识符(pid -> process id), 就如同学生在学校里有一个专门的学号一样.
大多数进程信息同样可以使用top和ps这些用户级工具来获取
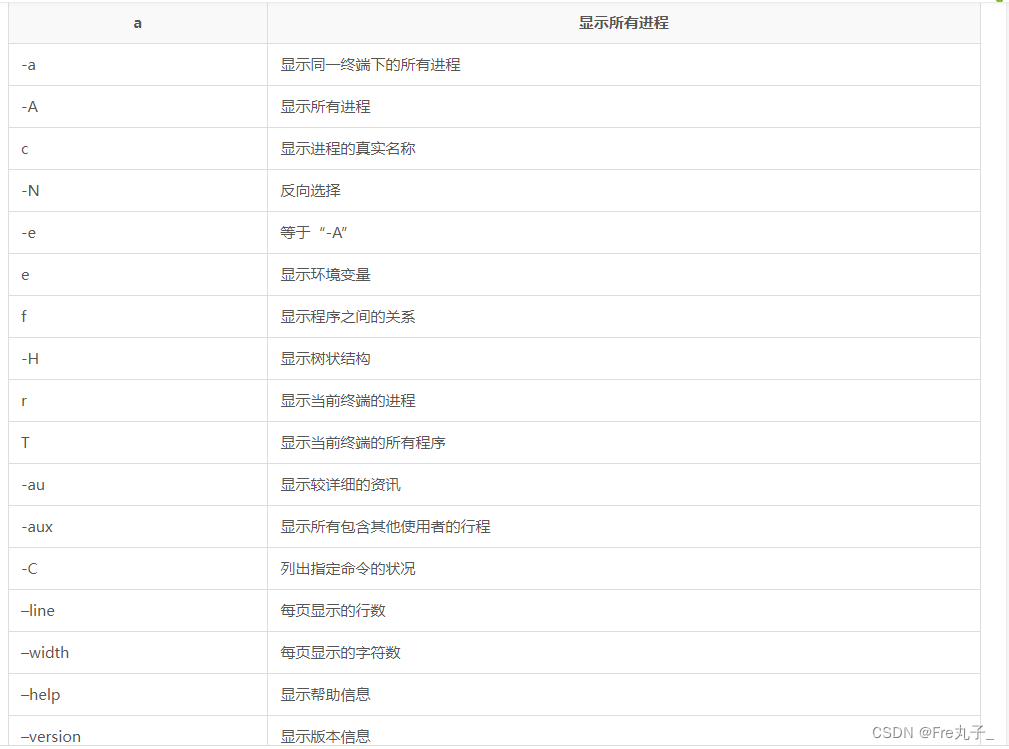
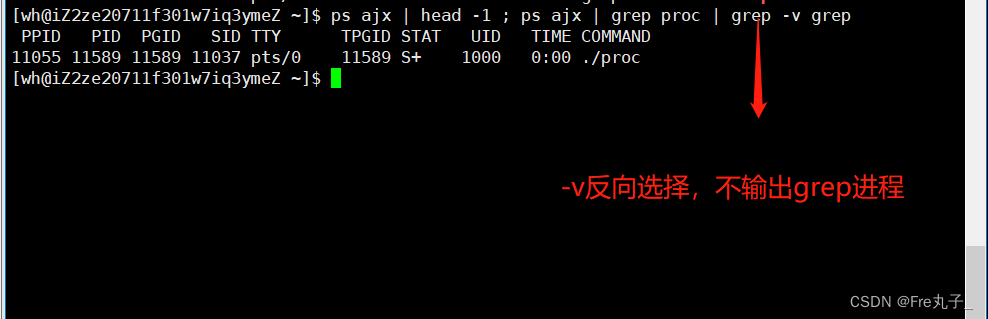
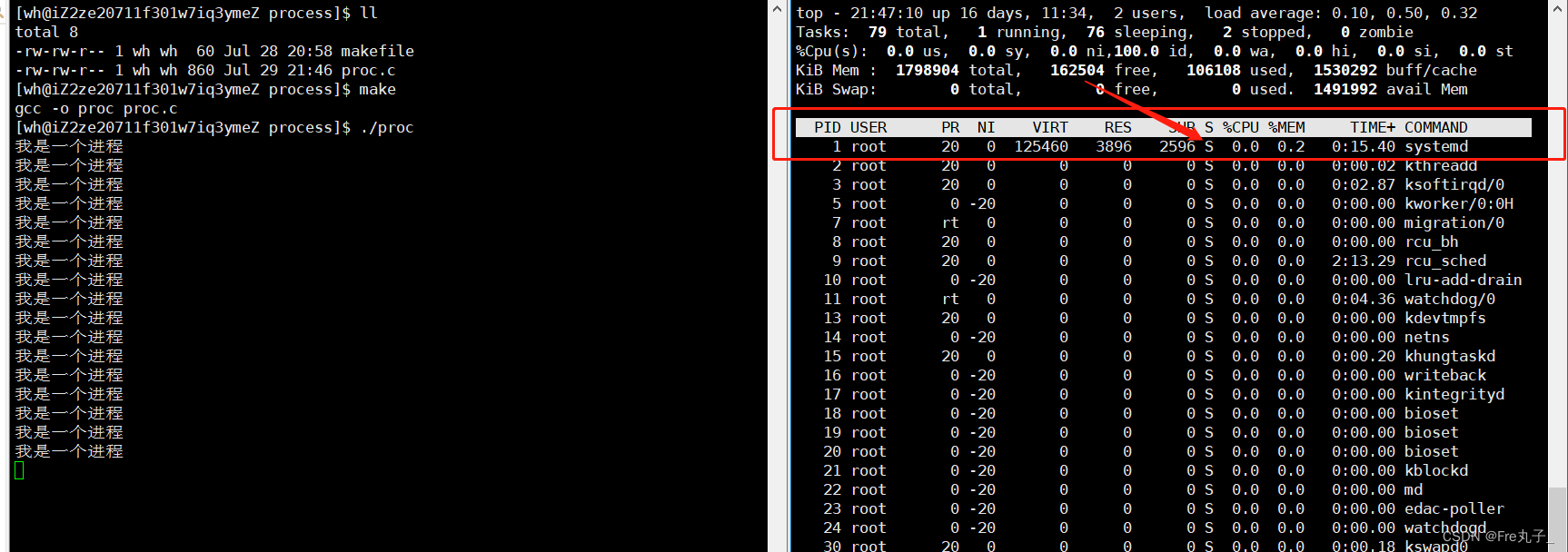
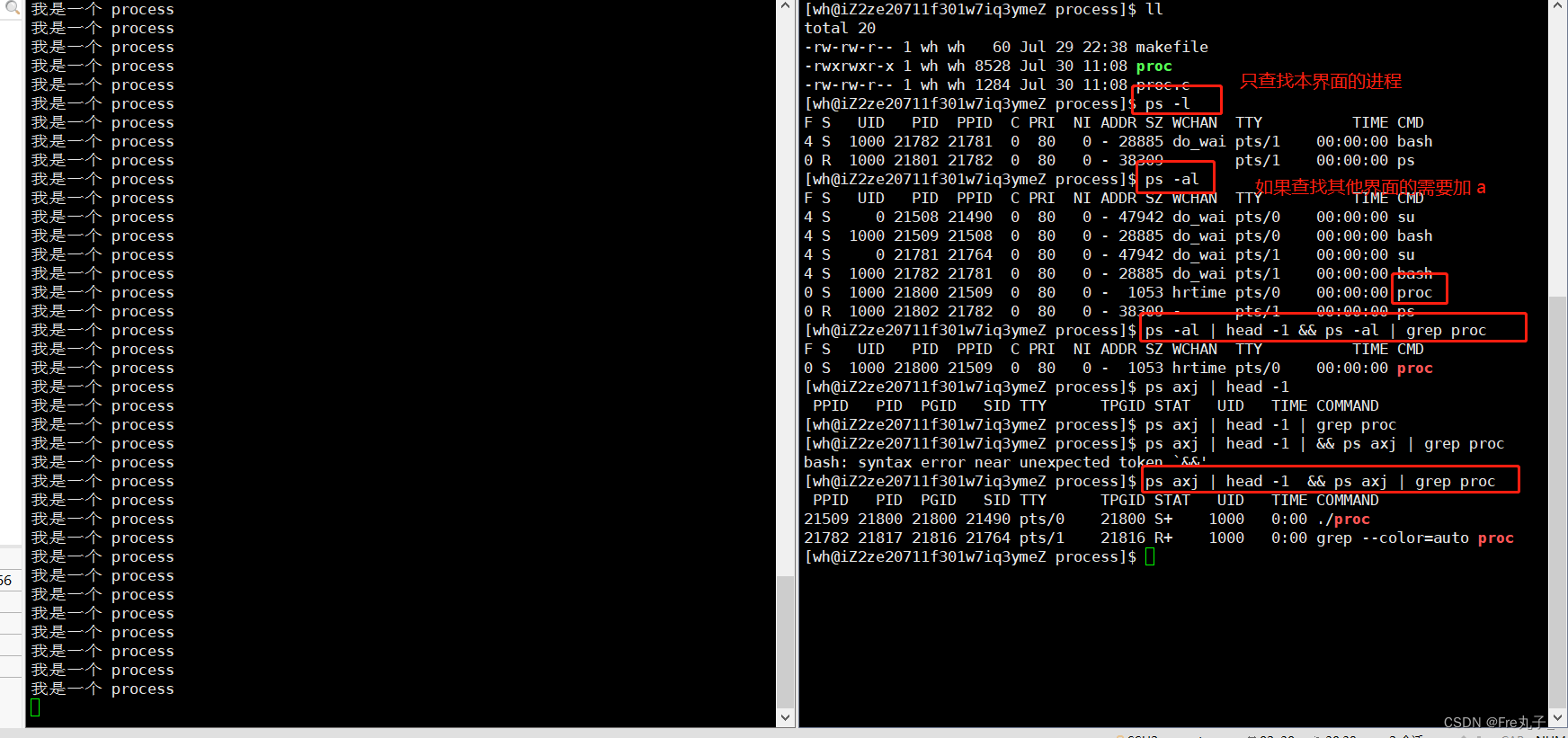
ps命令 用于报告当前系统的进程状态。可以搭配kill指令随时中断、删除不必要的程序。
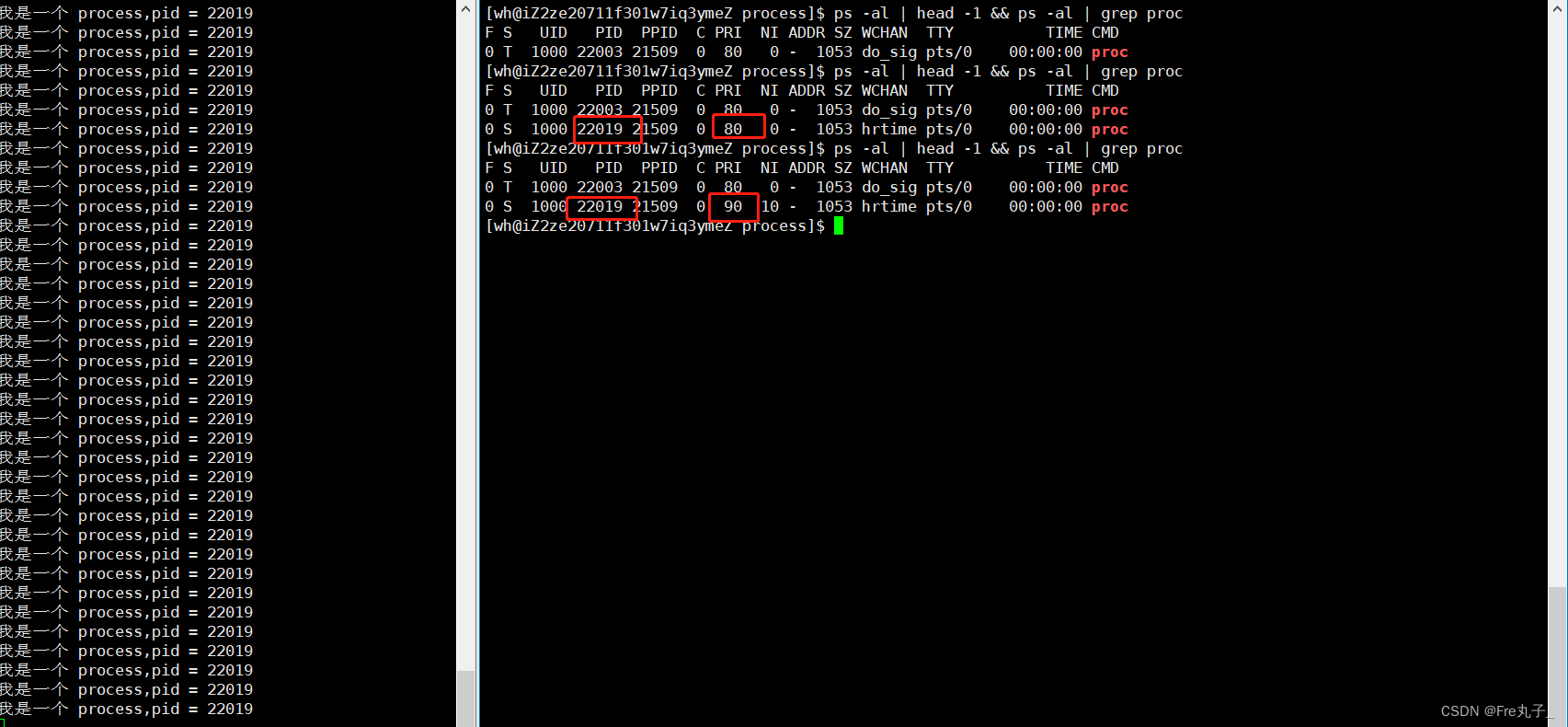
ps的选项
**head -1 **只输出第一行
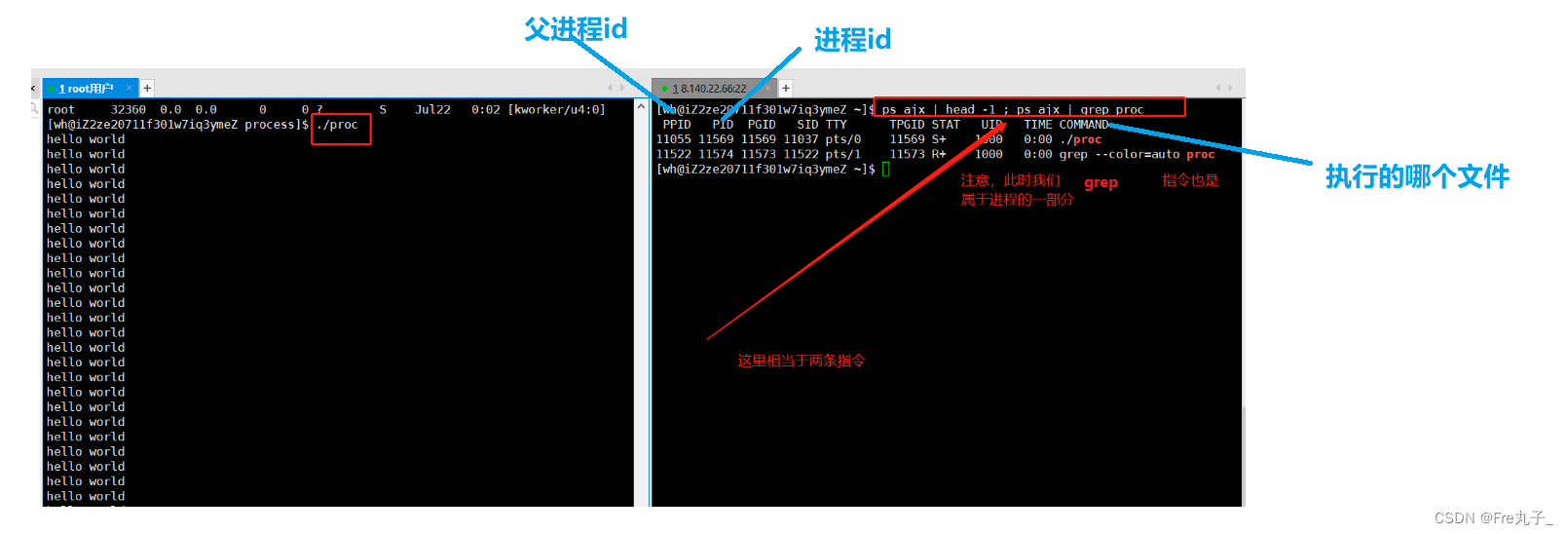
grep -v命令
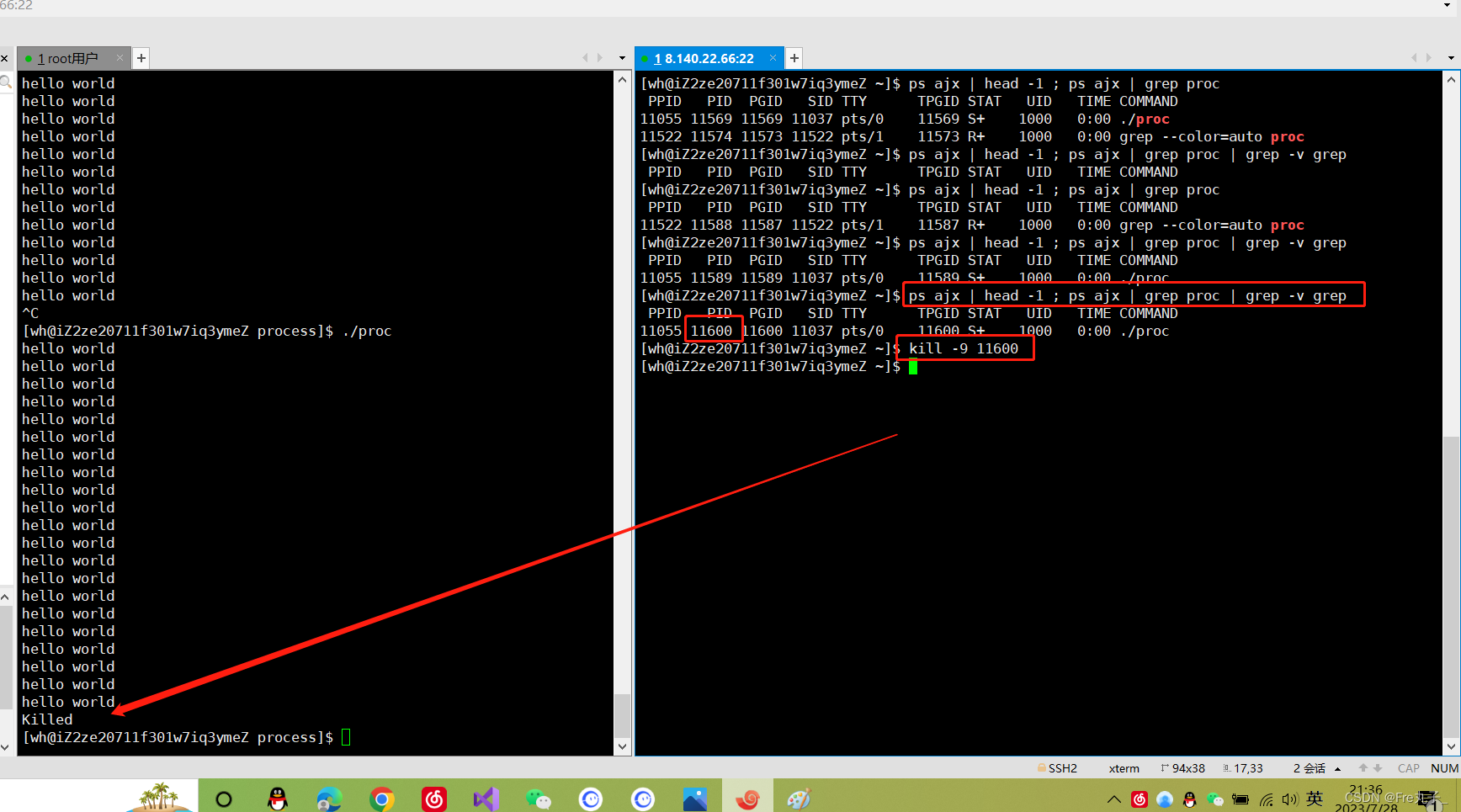
kill进程终止
kill -9是杀死进程的终极武器。一般情况下慎用,以防产生什么系统故障或者影响软件的再运行环境。
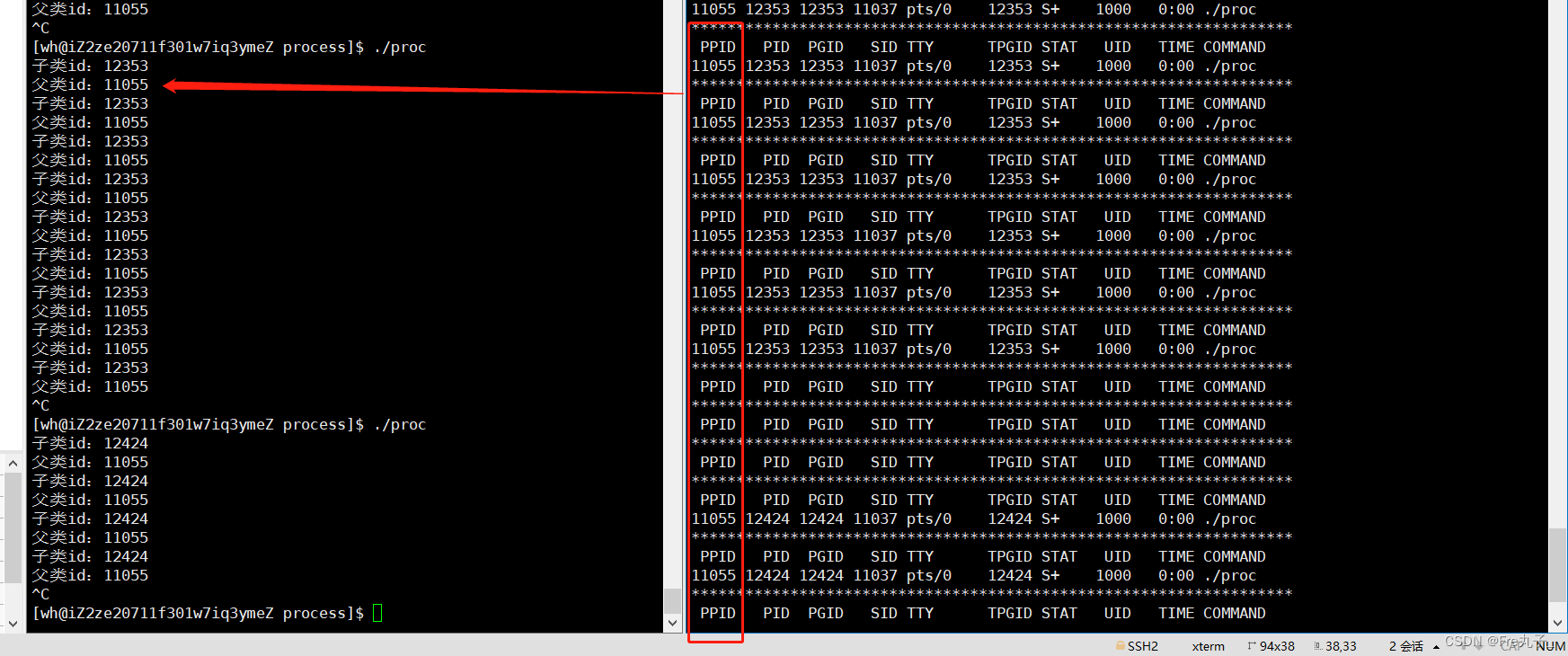
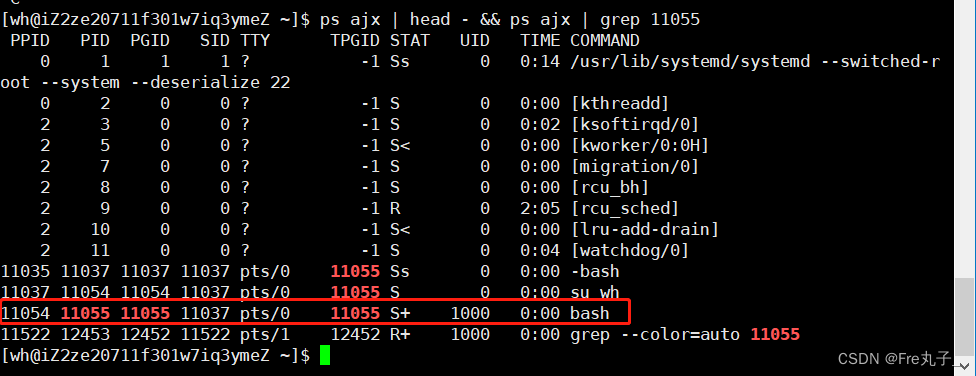
获取子ID(getpid)
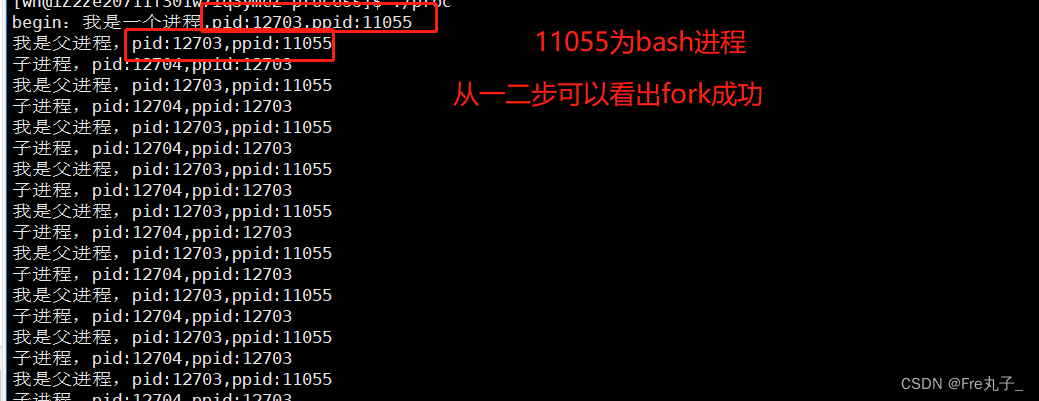
从运行结果可以看出,我们的子类进程的ip只要一结束重写运行ip就会变,但是父类ip不会变,父类不变说明命令行所有指令都是bash的子进程
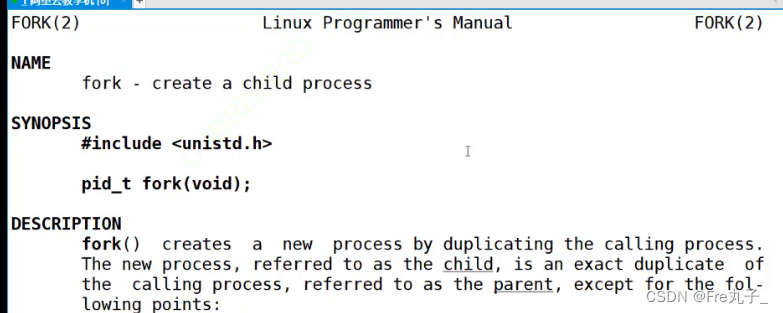
创建子进程(系统调用创建进程 fork)
fork()如果成功了返回值为子进程的id并且0返回给子进程,如果失败了返回-1给父类,没有子进程创建

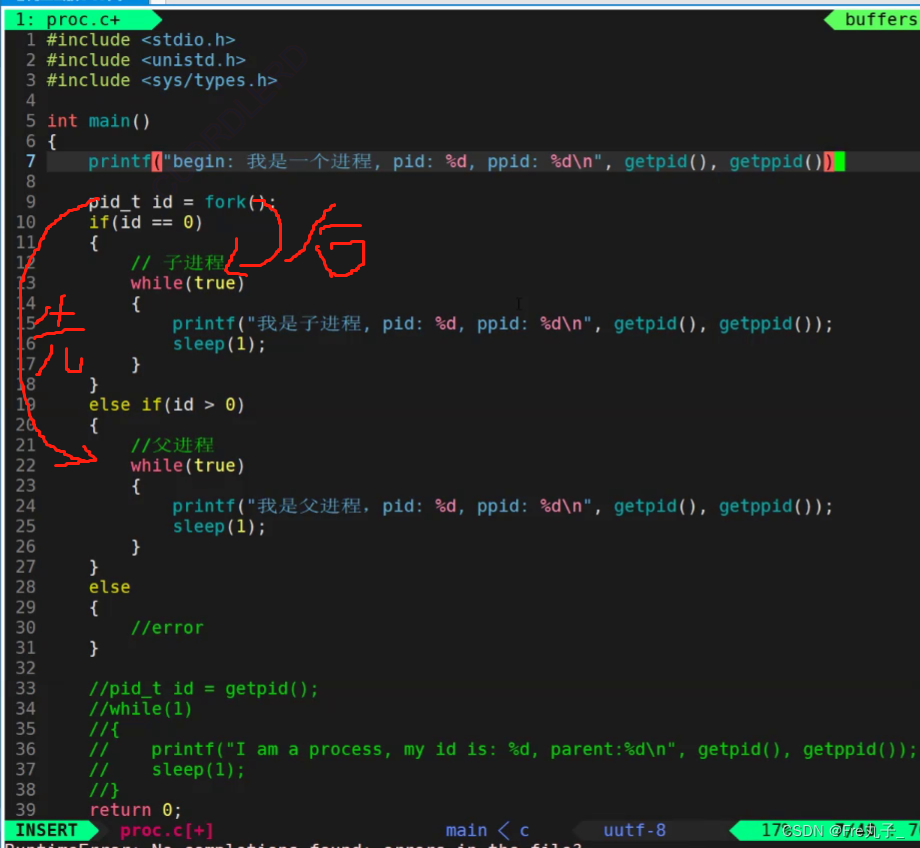
问题1:为什么fork要给子进程返回0,给父进程返回子类的id呢?
他们赋值不同是为了区分不同的执行流,执行不同的代码,一般而言fork之后的代码都是父子共享。
这是因为后期父类会对子类进行修改,所以我们需要提前保存子类的id,而子类可以通过getpid函数来得到父类的id,所以只需要赋值0标记创建成功即可
问题2:一个函数是如何做到返回两次的?
在我们fork后,同一个程序会执行两次,这是因为新建的子类和父类的代码时共用的且不可被修改。除非我们做一下判断返回值的选项来分别输出

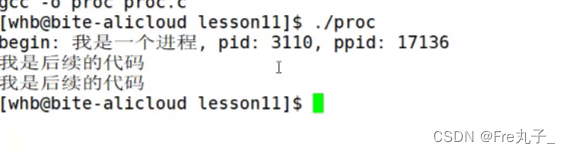
那么我们为什么要创建子进程呢?
这是因为我们不想让父和子做同样的事情,需要想办法分开输入,所以我们就从frok()的返回值下手
那么是如何做到返回两次的呢?这是因为fork是一个函数,它内部对马上要进行的子进程进行了一些包裹,最后我们return的时候会返回两次,这是因为return语句是父和子共享的,所以就会出现两个结果,输出两次

问题3:一个变量怎么会有不同的内容?
当fork了一个子进程后,如果子进程没有新的成员或者函数方法,并且也没有对父类进行修改,则这是它和父类是共用的同一空间和代码区。
当他重写了父类的方法或者自己新建了函数、变量,则这是系统会为他新建一块空间,这是我们叫写时拷贝
当fork执行成功后,如果父子进程被创建好,谁先运行是由调度器来决定的。
进程的状态
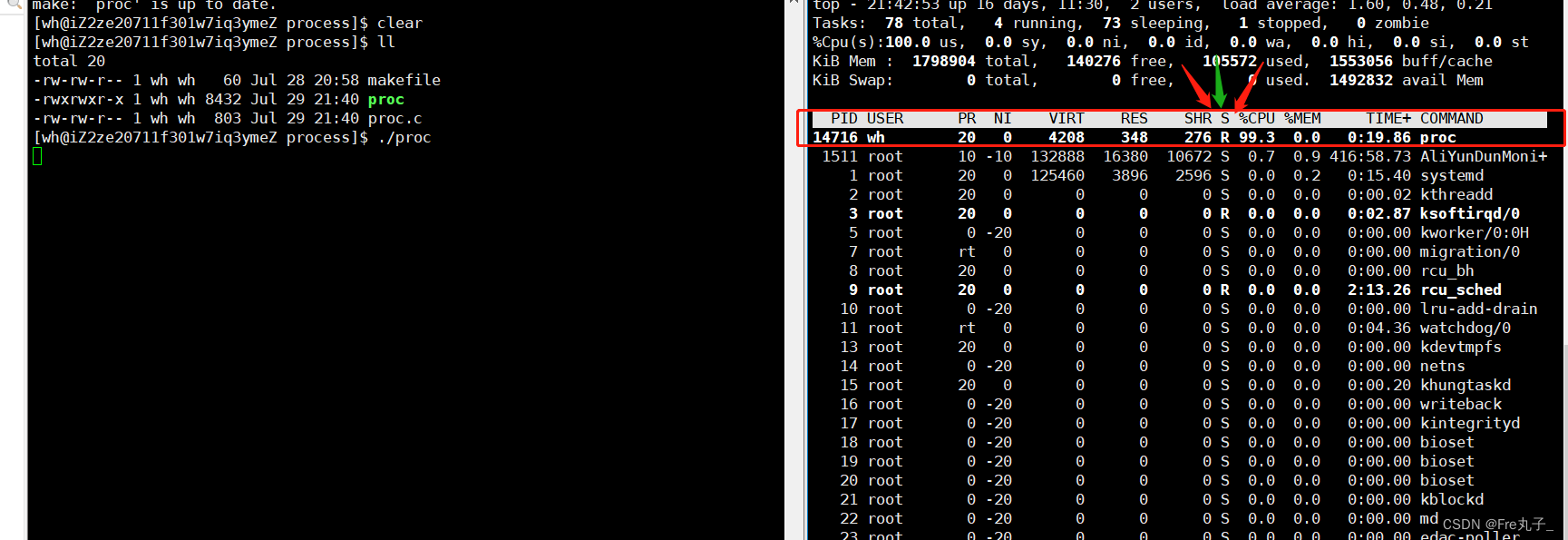
运行状态(R)
这是我们的程序一个重复执行while,所以一直为运行状态
阻塞状态(S)(D)
S 浅度睡眠
因为cpu的运行速度非常快,又因为操作系统中的进程特别多,所以操作系统会将其设置为阻塞状态
D 深度睡眠
如果其要输出的内容太多时,由于输入磁盘的较慢,所以会影响后边的进程,所以操作系统会将其设置为深度睡眠。
这是操作系统不可以手动进行kill终止程序,只能让其自己转移到运行状态。
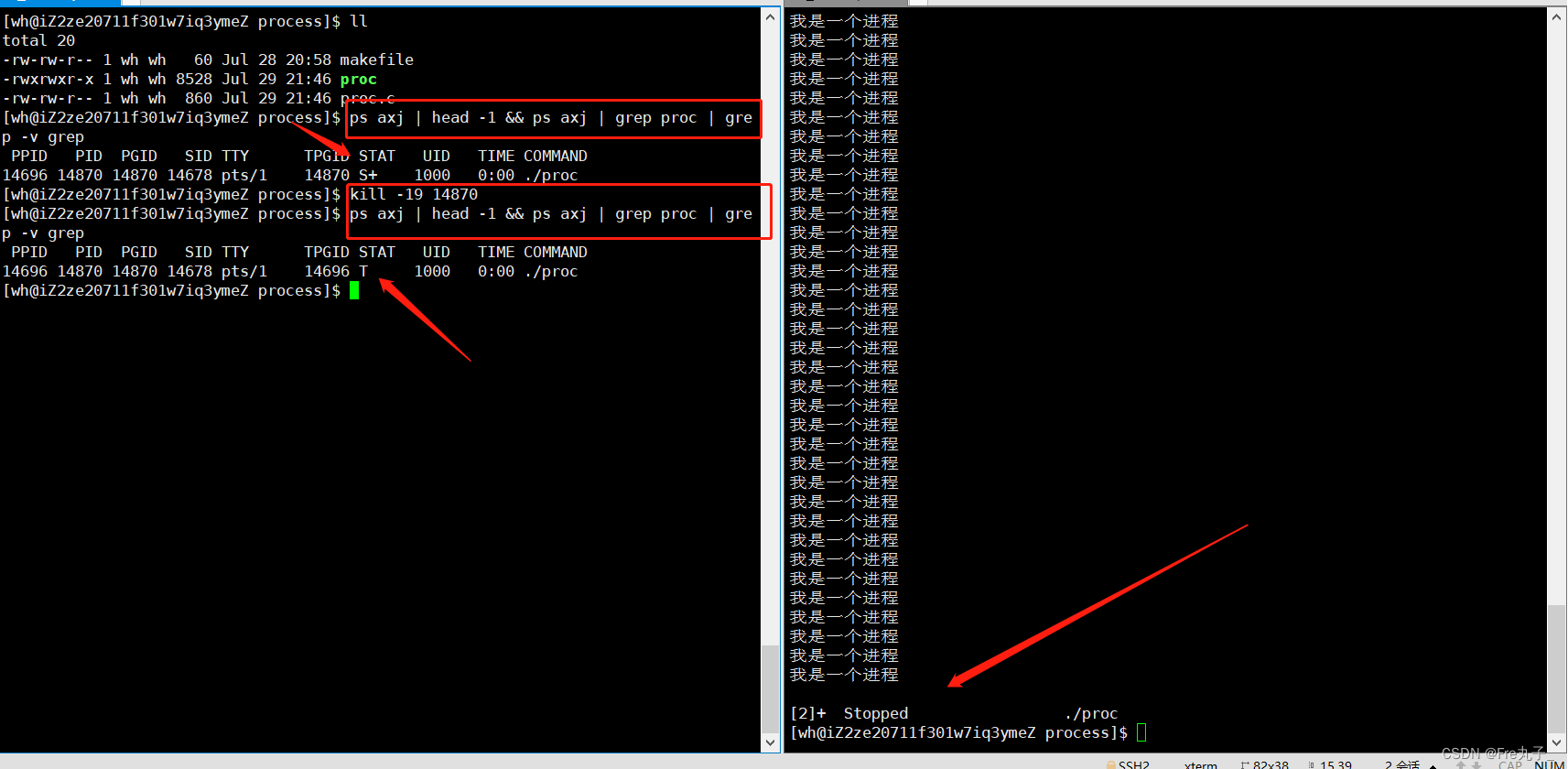
停止状态(T,t)
T
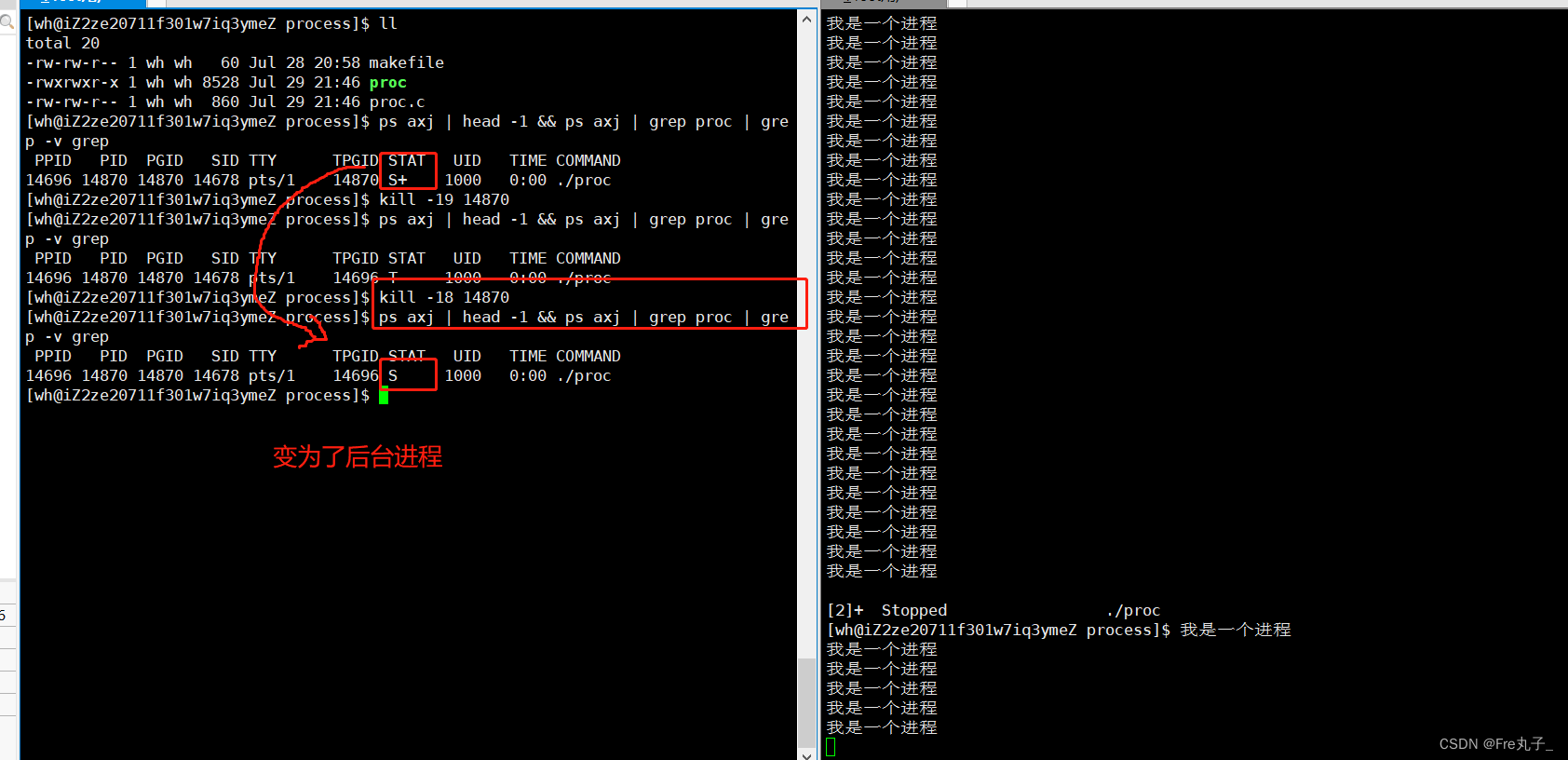
kill -19 为停止程序
kill -18 为继续让程序运行
这里需要注意的是,当我们把进程停止后又恢复正常的运行时,这时的进程是出于后台运行的,需要我们手动 kill -9 杀死进程
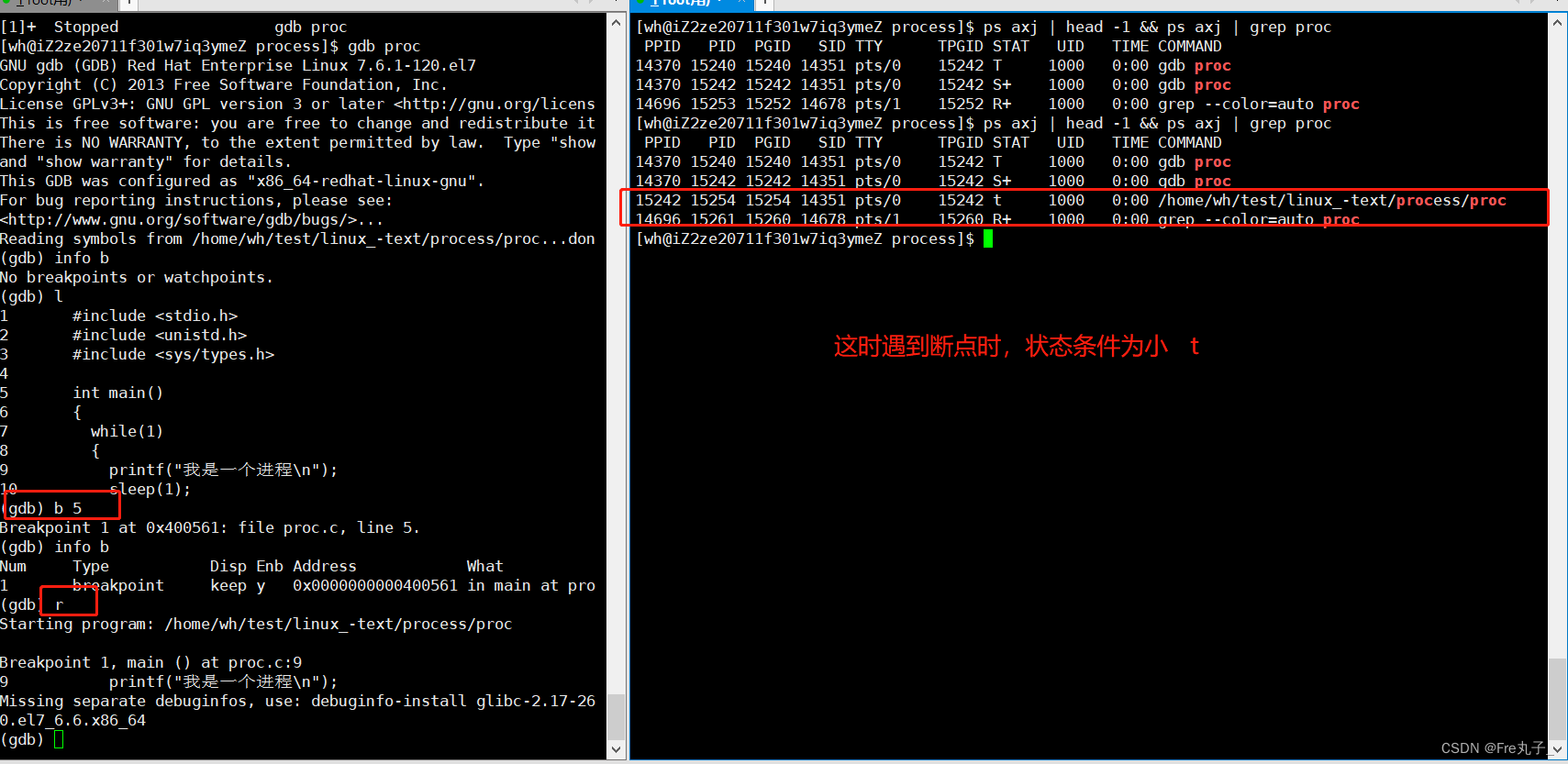
t
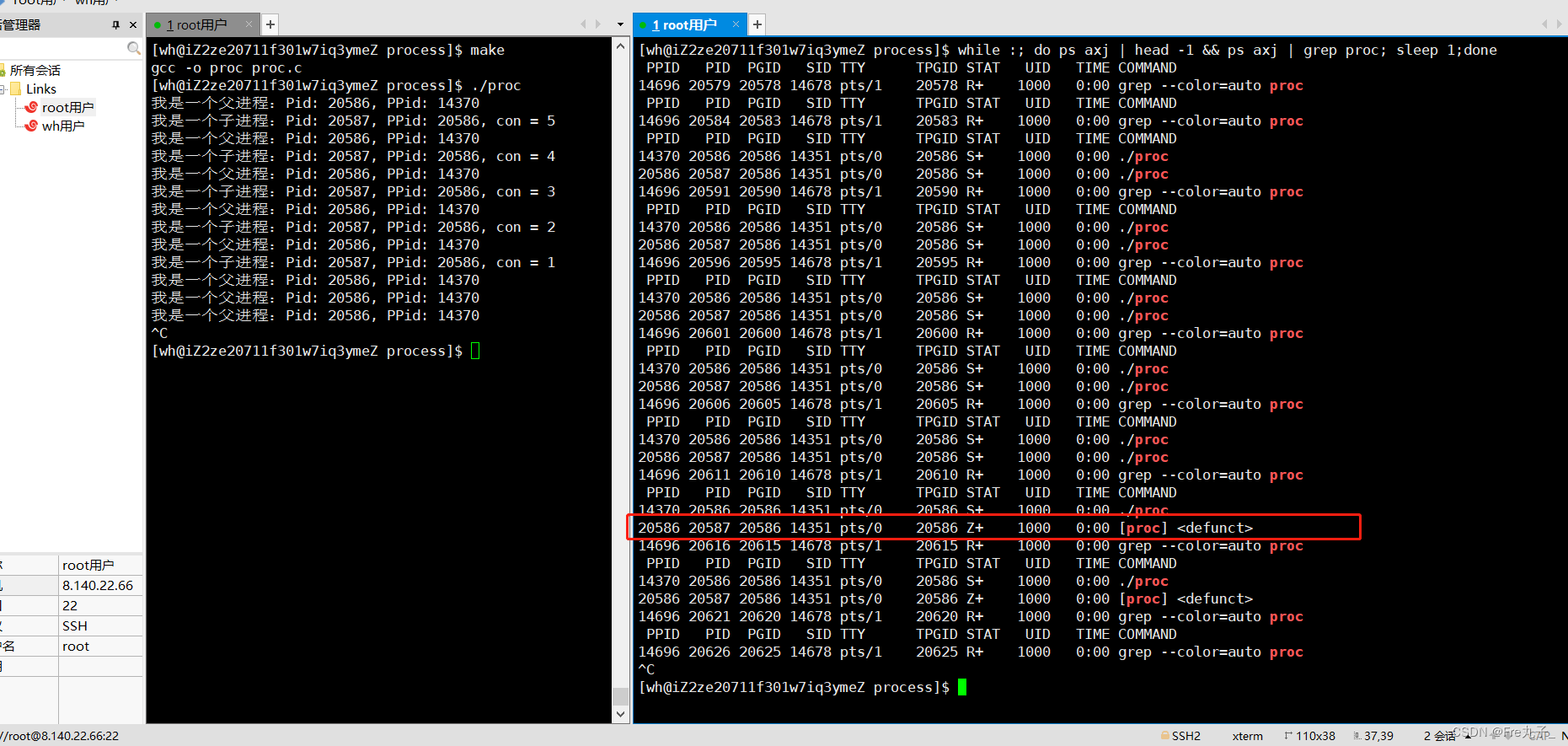
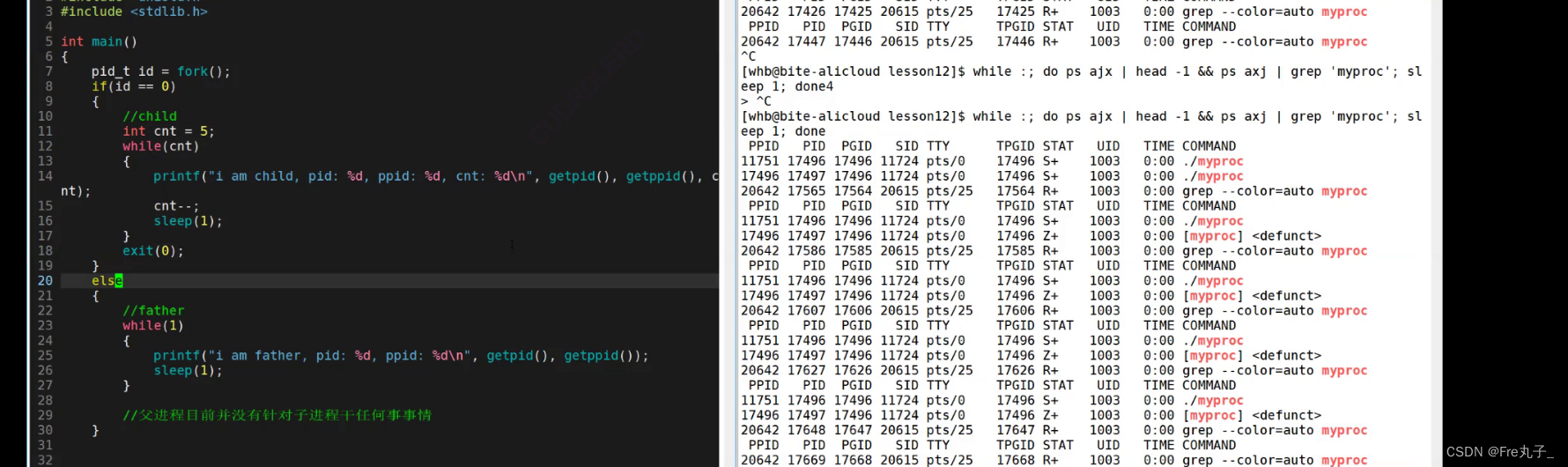
僵尸进程(Z)
子进程先结束的情况
当我们子进程结束后,在父进程没有收回子进程的时候,子进程会进入僵尸状态,如果一直没有收回就会导致内存泄漏
孤儿进程
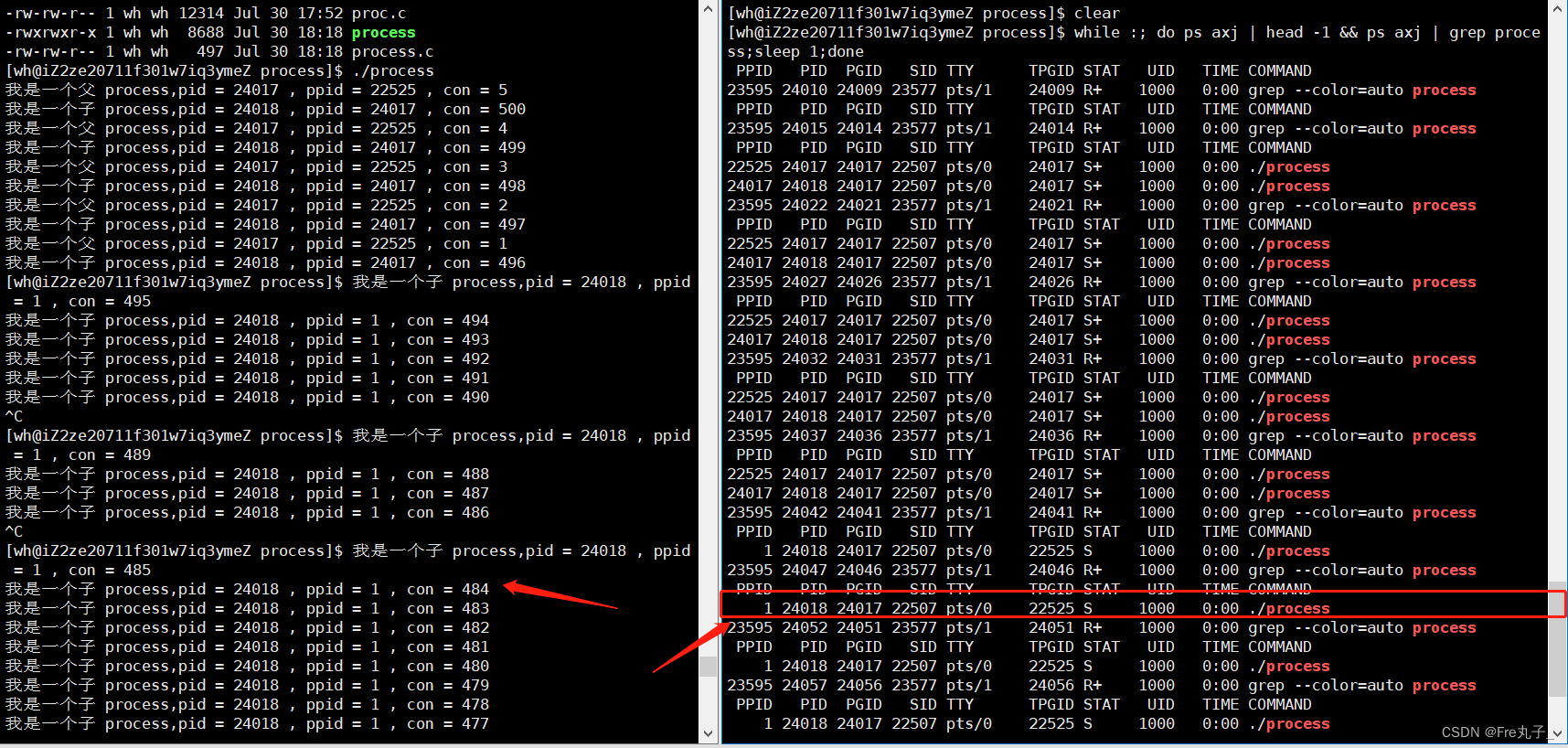
父进程先结束的情况
如果此时父进程先结束,那么他的进程会被他的父类给回收,此时我们的子进程就会变成孤儿,称为孤儿进程,并且会直接被操作系统收到膝下,作为他的父类。
什么是孤儿进程?
当父进程在子进程之前结束,那么这时的子进程就变味了孤儿进程,当子进程变为孤儿后,会被bash收下,并且成为他的父进程,此时的子进程就会转到后台运行,我们可以看到S后边没有+了
进程优先级
优先级是对于资源的访问,到底是谁先访问,谁后访问。
因为资源是有限的,进程是多个的,注定了,进程之间是竞争关系的!
因此操作系统为了公平竞争,规定了可以修改进程的优先级。如果一个进程长时间得不到CPU资源,该进程代码长时间得不到推进(进程饥饿)
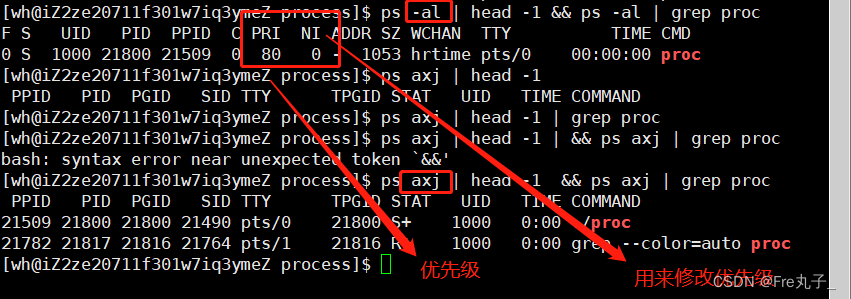

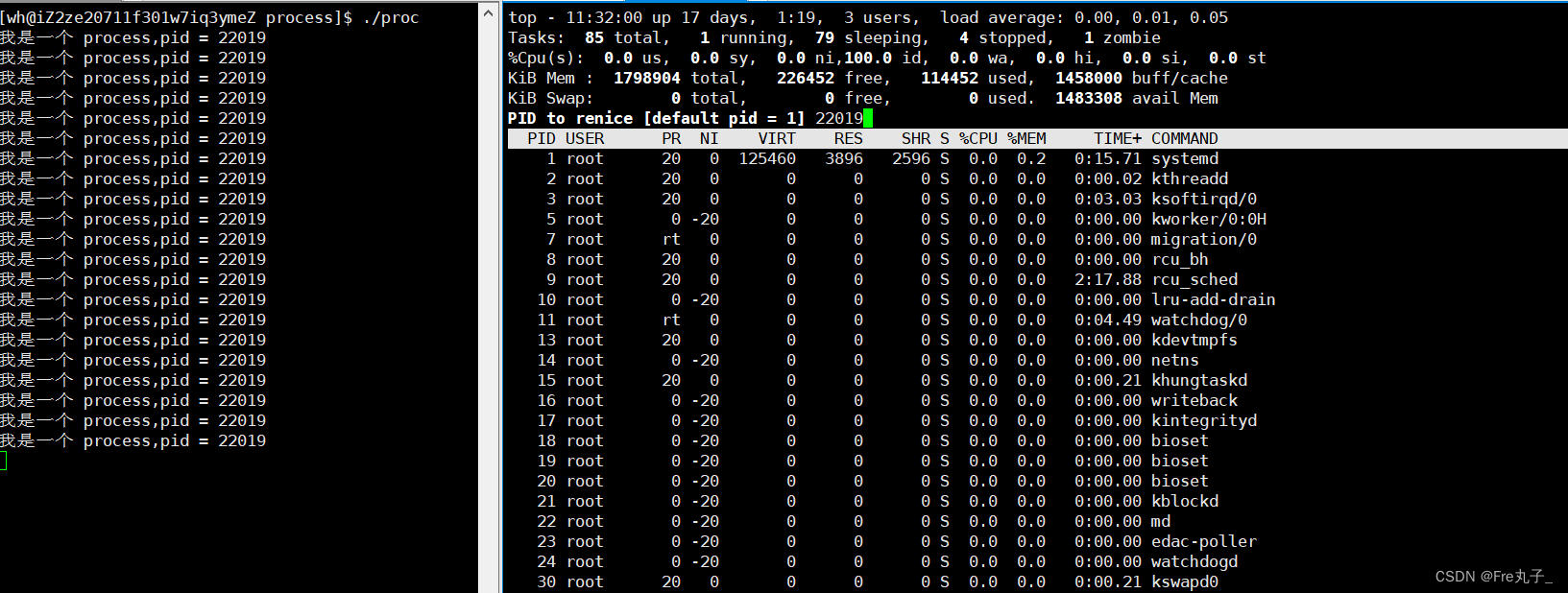
调整优先级
我们可以通过top命令里头的r命令来调整
top修改优先级必须在root用户下才可以,当我们输入r之后,我们需要输入修改进程的pid,接的就是输入对进程要更改多少,其nice的取值范围为[-20,10],priority的值范围为[60,99],其默认优先级为 80