前段时间有个公众号的朋友问我如何生成丰富的啸叫类型,当时回答比较简单,只是把啸叫产生的条件说了一下,后来在写AI降噪的N种数据扩增方法时候也简单提了一下使用冲激响应(Impluse Respose, IR)和增益产生啸叫,今天我们把这个坑填上。本来想叫【有问必答】的,但是想了想本人能力有限,还是低调一点好,23333,后续有公众号朋友提的一些问题也会以这种形式写出来。
声反馈の模型
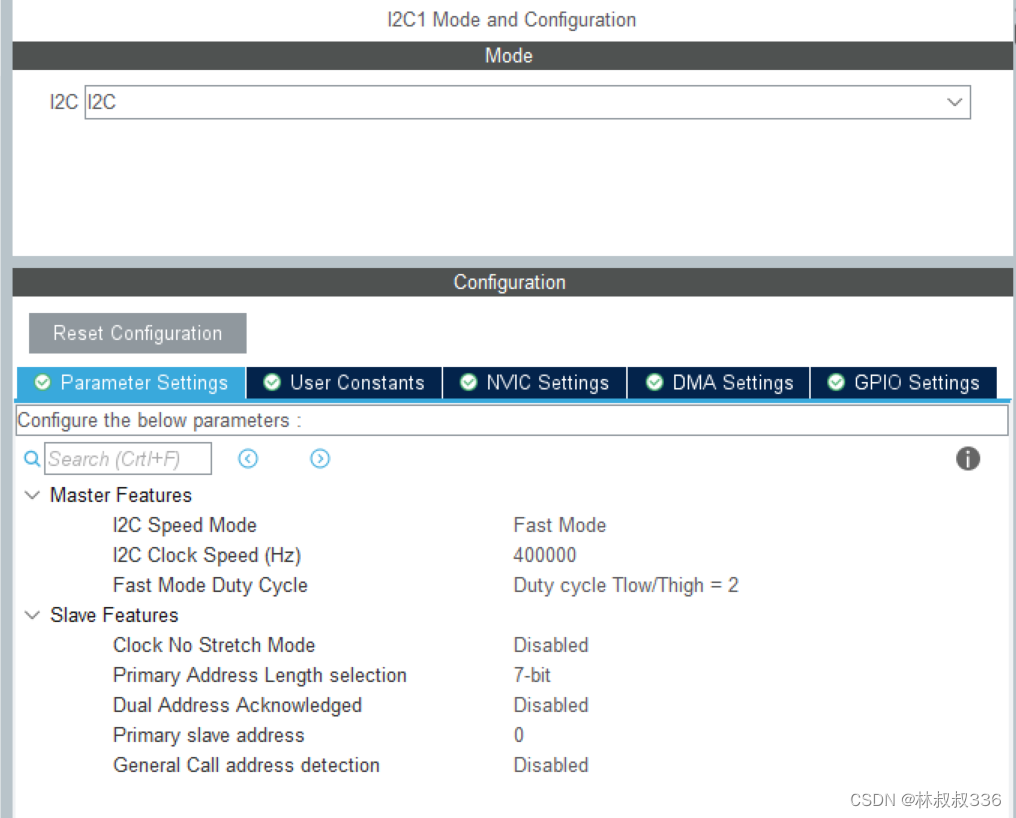
由于扬声器和麦克风之间的声学耦合产生闭环系统而发生声学反馈(Acoustic feedback, AF),随着时间的推移,这个系统会变得不稳定从而产生啸叫(Howling)。文字表述比较抽象,我们画出它的系统框图进行讲解
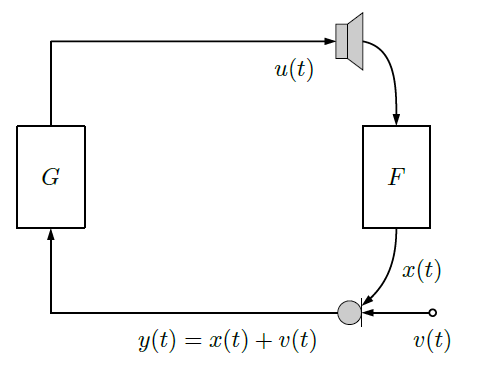
用t表示离散时间索引,q表示离散时间时移操作,其中v(t)表示麦克风采集的源信号;y(t)表示馈送到闭环系统的前向路径传递函数 G(q) 的麦克风信号;u(t)表示扬声器信号,即 G(q) 的输出;x(t)表示反馈信号,反馈路径传递函数 F(q) 的输出会导致扬声器和麦克风之间产生不必要的耦合。此时麦克风输入信号可以表示为:
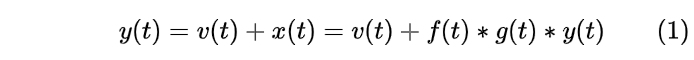
闭环系统的传递函数为
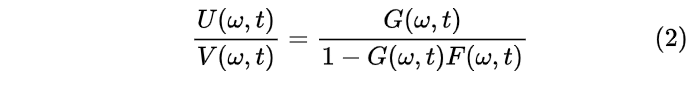
啸叫の条件
我们知道对于线性时不变(linear time invariant, LTI)系统,它是有界输入-有界输出稳定(Bounded Input Bounded Output stable, BIBO stable)。在频域中,具有BIBO 稳定性的系统其所有极点都必须在单位圆内,即
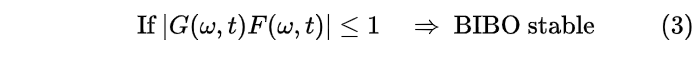
根据奈奎斯特稳定判据(Nyquist stability criterion), 当闭环系统在某个频率处满足如下的闭环增益和闭环相位条件时,系统会变得不稳定
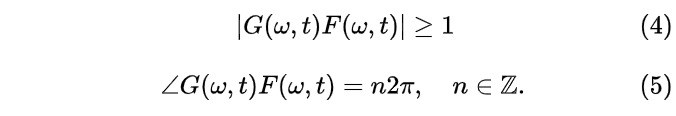
在上述条件下,如果系统中的某个频率被激发,导致系统不稳定产生振荡,就会以啸叫的形式表现,啸叫通常出现在大约 200 到 5000 Hz 并且具有类似于单个正弦分量的非常窄带的特征,因为通常只有一个单个频率是不稳定。
啸叫の实现
一开始以为这种成熟的技术网上随便找一下就能找到,结果搜howling出现最多的是
没关系,我自己来,本信号与系统渣渣花了亿点点时间终于实现了这个简单的功能。
-
首先系统最大稳定增益 (Maximum Stable Gain,MSG) 定义为可应用于闭环系统正向路径而不会使系统不稳定的最大宽带增益,其计算公式为
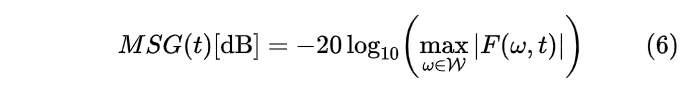
这意味着我们需要给系统加超过MSG的增益以产生啸叫。
-
每次读入一帧数据,并对数据进行加窗,重叠相加到输出数据
-
对加窗后的数据与IR进行卷积得到声反馈数据,然后叠加到下一帧输入数据
-
循环以上两步直到处理完所有数据
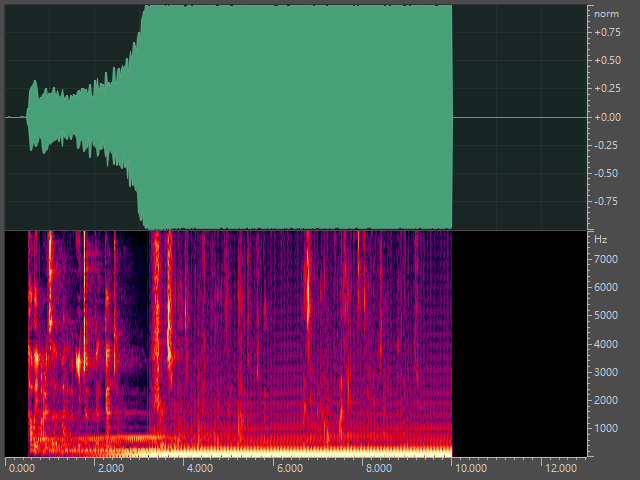
这里我们使用了两个不同的IR(IR的数据集有很多网上一搜一大把),由于啸叫的声音比较刺耳,这里就不放音频了,产生啸叫的频谱如下所示,可以看到第一个音频单频点发生啸叫,而第二个音频在多个倍频发生了啸叫。
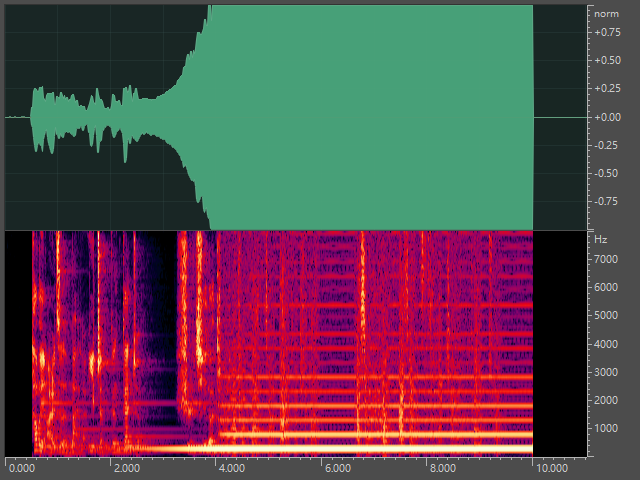
本文代码在公众号语音算法组菜单栏点击Code获取
参考文献:
[1]. Evaluation of various Algorithms to detect acoustic Feedback
[2]. Acoustic Event Detection: Feature, Evaluation and Dataset Design







![[SSM]Spring对事务的支持](https://img-blog.csdnimg.cn/d57847d30c594389823e32a63cd4b417.png)