ico是vcs提供的用于优化覆盖率的feature;一般用户通过dist solver bofore等约束了变量的随机概率,而ico会在用户约束的基础上,做一些自动“修正”,以此来优化随机激励,提高随机多样性,加速覆盖率收敛,缩短 turn-around time TAT。 主要功能包含如下几部分:
Prognosis: 用于查看当前平台是否适用ico,对于都是直接用例测试,没有随机策略的平台,ico并不适用;Auto Bias:利用设定策略,ico会改变原有constraint solver的行为,施加一定bias修正随机值;RCA: root cause trace, 用于诊断变量未随机到的bins,是否存在过约束等;Delta-debug: 提供replay复现功能,对比两次结果间的差异;AutoPurge: 当前回归得到的ico database可以用于下一次回归,多次迭代;
ico最主要的功能就是Auto Bias,宣称使用了AI,机器学习ML,增强学习EL等手段,在回归过程中,利用共享case之间的ico database,提高随机多样性;通过一个简单例子演示下:
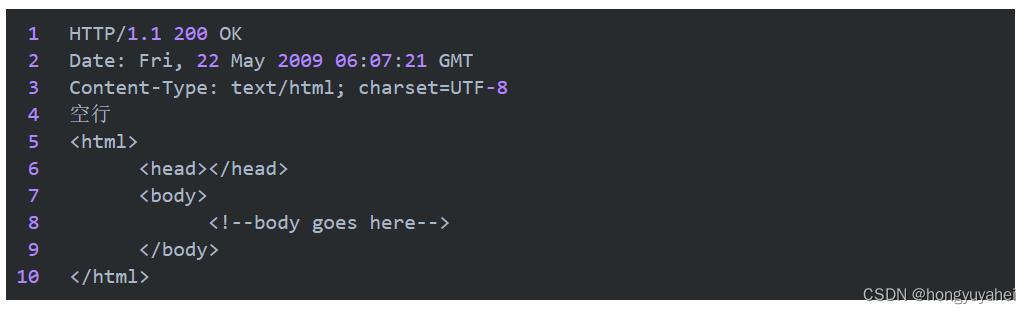
covergroup cg_data with function sample (input logic valid, logic [7:0] data);
cpt_value: coverpoint data iff (valid){
bins zero = {0};
bins others[] ={[1:31]};
illegal_bins invalid = {[32:255]};
}
endgroup
class tr extends uvm_transaction;
rand logic [7:0] data;
constraint c_tr { data inside {[0:31]};
data dist {0:=1,[1:31]:=100};
}
endclass
如上,对data的约束中,data=0这一条件的概率很低;
PRJ := $(shell echo $(CURDIR) | sed -r 's|\/ico_test\/.*|\/ico_test|')
export PRJ
all: comp run
all_ico: comp run_ico
SEED := ${SEED}
regress_ico: clean
mkdir -p ${PRJ}/comp_src; \
cd ${PRJ}/comp_src; \
cp ${PRJ}/Makefile ${PRJ}/comp_src; \
make comp;
for i in 1 2; do \
mkdir -p ${PRJ}/test_$${i}; \
cp ${PRJ}/Makefile ${PRJ}/test_$${i}; \
cd ${PRJ}/test_$${i}; \
ln -s ${PRJ}/comp_src/simv.daidir simv.daidir;\
ln -s ${PRJ}/comp_src/csrc csrc;\
ln -s ${PRJ}/comp_src/simv simv;\
make run_ico SEED=$${i}; \
done
make cov_merge;
make crg_report;
regress: clean
mkdir -p ${PRJ}/comp_src; \
cd ${PRJ}/comp_src; \
cp ${PRJ}/Makefile ${PRJ}/comp_src; \
make comp;
for i in 1 2; do \
mkdir -p ${PRJ}/test_$${i}; \
cp ${PRJ}/Makefile ${PRJ}/test_$${i}; \
cd ${PRJ}/test_$${i}; \
ln -s ${PRJ}/comp_src/simv.daidir simv.daidir;\
ln -s ${PRJ}/comp_src/csrc csrc;\
ln -s ${PRJ}/comp_src/simv simv;\
make run SEED=$${i}; \
done
make cov_merge;
comp:
vcs -full64 \
-kdb -lca \
-debug_access+all \
-ntb_opts uvm \
-sverilog \
-timescale=1ns/1ns \
${PRJ}/dut.sv \
${PRJ}/top_tb.sv \
+incdir+${PRJ} \
-l comp.log
run_ico:
./simv -l sim.log +ntb_random_seed=${SEED} \
+ntb_solver_bias_mode_auto_config=2 \
+ntb_solver_bias_shared_record=${PRJ}/shared_record \
+ntb_solver_bias_wdir=ico_work \
+ntb_solver_bias_test_type=uvm \
+ntb_solver_bias_diag=3
crg_report:
crg -dir ${PRJ}/shared_record -report rpt-auto -format both -merge merged_db -zip 1 -illegal_group -illegal_attr
run:
./simv -l sim.log +ntb_random_seed=${SEED}
verdi:
verdi -ssf top_tb.fsdb &
cov_open:
verdi -cov -covdir simv_merge.vdb &
cov_merge:
urg -dir ${PRJ}/test_1/simv.vdb -dir ${PRJ}/test_2/simv.vdb -dbname ${PRJ}/simv_merge.vdb
clean:
-rm -rf shared_record/ simv* test_* WORK/ *log urgReport/ vdCovLog/ rpt-auto/ merged_db/ comp_src/ novas.*
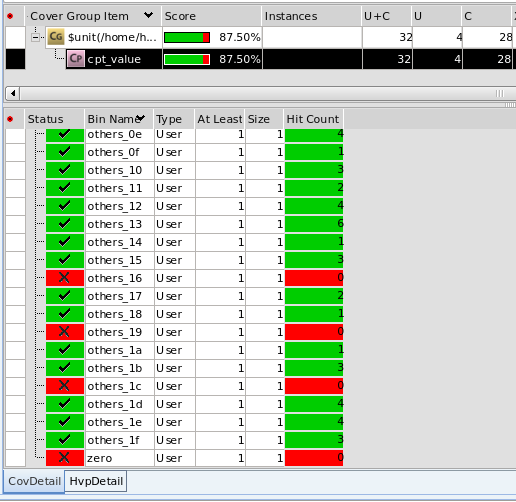
make regress跑了两个case,第一个case seed=1,第二个caseseed=2;
通过verdi查看覆盖率报告:
跑了两次的回归merge结果:
87.5%
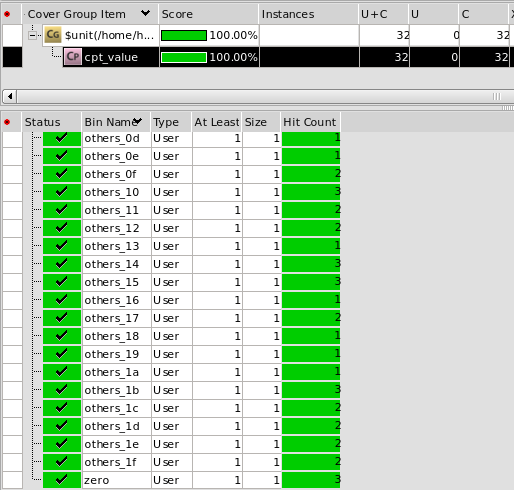
make regress_ico是使能icofeature,结果:
100%
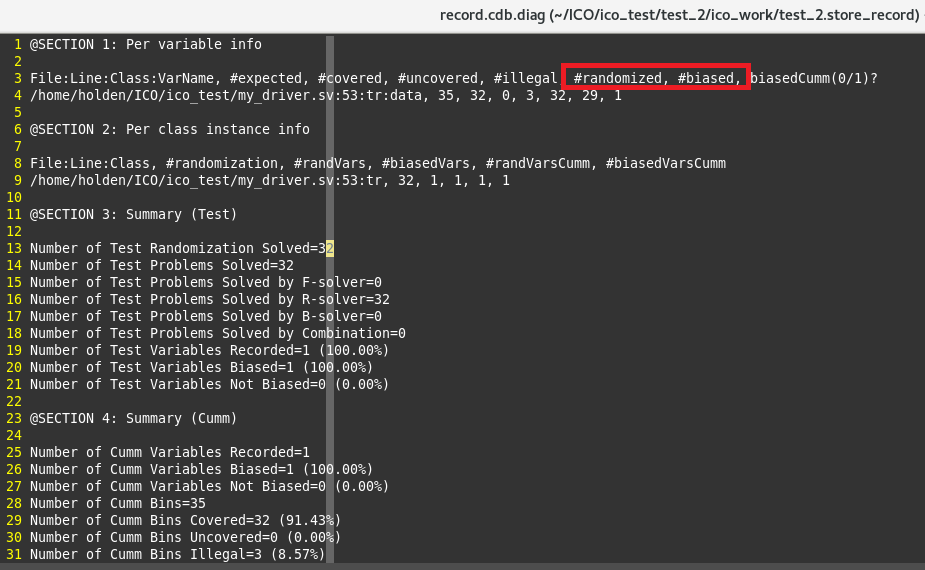
+ntb_solver_bias_diag使能debug信息,默认debug log放在+ntb_solver_bias_wdir指定的ico database下:
随机32次,ico影响constrain solver,bias了29次的随机结果;所以对于data=0这样的小概率事件,也随机到了;
因为ico会影响constrain solver的随机结果,所以复现时,不仅要保证seed一样,还需要额外指定ico database,这样才能正确复现随机结果。
生成当前回归所有用例的merge report:
html report会罗列所有随机变量:
DIVERSITY通过shannon entropy 香农熵衡量变量的“多样性”;

每个变量,ico会自动的划分bins,显示随机详细结果;
ico支持同一个case内多次randomize之间相互影响,也支持一次回归不同case之间相互影响,也可以将本次回归的database作用于下一次回归;
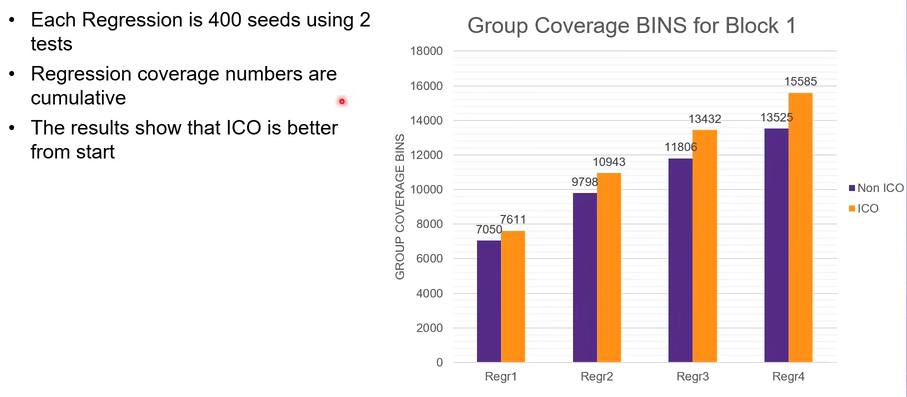
对于ico加速覆盖率收敛的实际效果,博主使用一个block tb亲测效果不太显著;从他人的presentation上看,大概有10%-20%的提升;但是ico对于随机多样性确实是有一定效果的,+ntb_solver_bias_mode_auto可以指定ico对随机的bias力度。

如果ico可以通过AI,EL等对功能覆盖率进行反推,缩减重复随机值,那将会大大提高覆盖率收敛,期待后续EDA进一步的"进化”吧。
相关资料和篇中示例整理:
链接:http://generatelink.xam.ink/change/makeurl/changeurl/7408





![[SSM]Spring对事务的支持](https://img-blog.csdnimg.cn/d57847d30c594389823e32a63cd4b417.png)