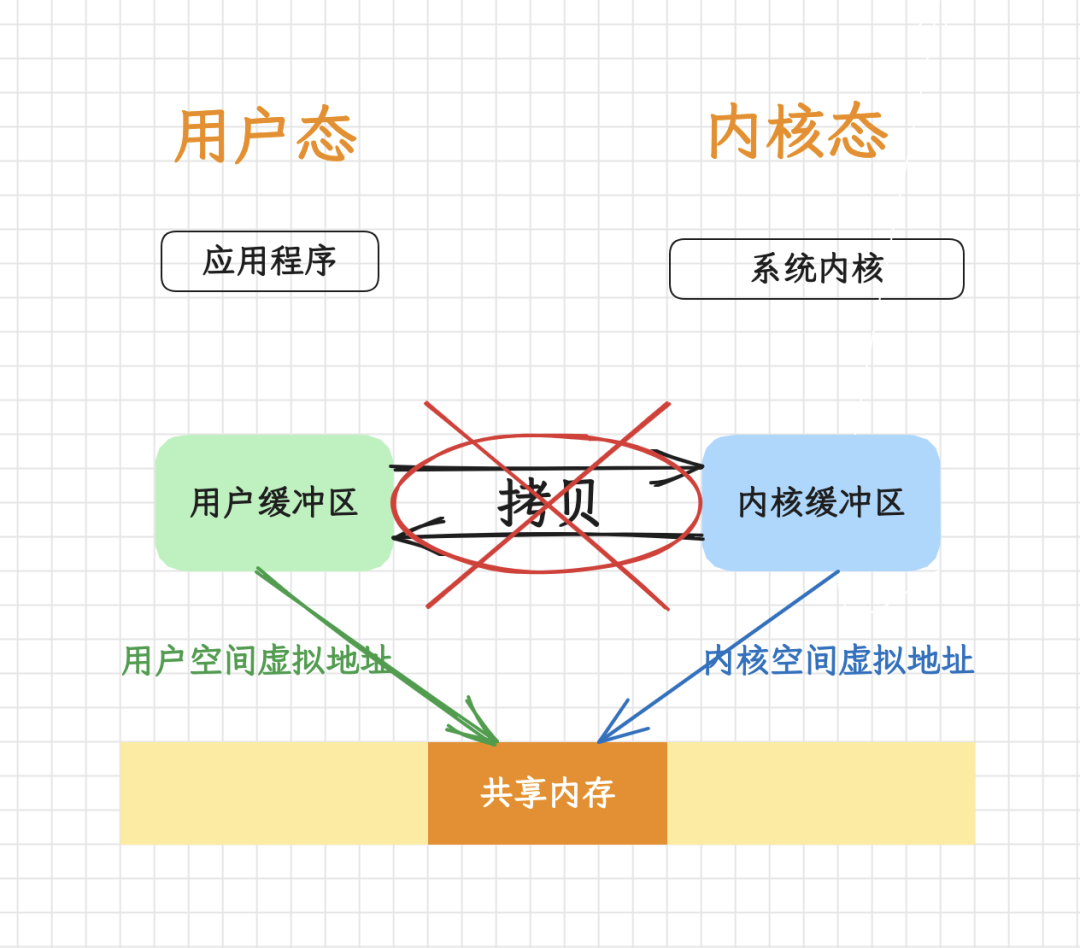
一、说明
这是我的“点云处理”教程的第 5 篇文章。“点云处理”教程对初学者友好,我们将在其中简单地介绍从数据准备到数据分割和分类的点云处理管道。
在上一教程中,我们看到了如何过滤点云以减少噪声或其密度。在本教程中,我们将应用一些聚类算法进行点云分割,即:K-means和DBSCAN。
- 第1条:点云处理简介
- 文章2:在Python中从深度图像估计点云
- 文章3:了解点云:使用Python实现地面检测
- 文章4:Python中的点云过滤
- 文章 5 : Python 中的点云分割
二、 简介
通常,数据分割旨在将数据重新分组为非重叠组。在点云分割中,这些组可能对应于区域:对象或其一部分、表面、平面等。点云分割方法可分为 3 大类:基于区域增长的方法、基于模型拟合的方法和基于聚类的方法。在本教程中,我们对基于聚类的方法感兴趣。聚类算法在许多机器学习API中实现,包括我们将在本教程中使用的Scikit-learn。
在引入一些聚类分析算法之前,请务必记住一些模型属性:
- 可扩展性。算法的可扩展性是它能够很好地处理大规模数据。关于聚类算法,它们的可扩展性取决于样本的数量(点云的点数)和聚类的数量。例如,K 均值和 DBSCAN 不能在大量集群中保持可伸缩性。
- 指标。为了创建样本组,聚类分析算法需要计算定义的指标,以查找同一组的点之间的相似性以及其他组的点之间的相似性。例如,K 均值计算点之间的距离,而 DBSCAN 计算最近点之间的距离。
- 运行。运行时间很重要,尤其是在实时应用程序中。它不仅取决于样本数量和组的数量,还取决于算法和计算指标。
- 超参数。该算法的超参数是一个需要考虑的非常重要的属性,尤其是组的数量。在许多应用程序中,集群的数量事先并不知道,因此固定组的数量可能会导致以后过程中的冲突。
- 行为。我认为重要的另一个重要因素是模型是确定性的还是随机的。确定性行为意味着算法每次执行都提供相同的输出,不涉及随机性。在这种情况下,聚类分析算法每次都会针对具有相同配置的相同点云返回具有相同点的相同聚类。相反,随机行为为具有相同配置的相同输入生成不同的输出;它具有一定的随机性。选择确定性模型还是随机模型取决于其应用。
这些是一些重要的属性,有关更多详细信息,您可以访问此链接。说够了,让我们开始练习吧!我们首先导入所需的库和我们的点云:
import numpy as np
import open3d as o3d
from sklearn.cluster import KMeans, DBSCAN, OPTICS
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
# Read point cloud:
pcd = o3d.io.read_point_cloud("../data/depth_2_pcd_downsampled.ply")
# Get points and transform it to a numpy array:
points = np.asarray(pcd.points).copy() 为了可视化计算的群集,在调用该方法后添加了以下行:fit()
# Get labels:
labels = model.labels_
# Get the number of colors:
n_clusters = len(set(labels))
# Mapping the labels classes to a color map:
colors = plt.get_cmap("tab20")(labels / (n_clusters if n_clusters > 0 else 1))
# Attribute to noise the black color:
colors[labels < 0] = 0
# Update points colors:
pcd.colors = o3d.utility.Vector3dVector(colors[:, :3])
# Display:
o3d.visualization.draw_geometries([pcd])三、K均值
K-means是一种基于质心的算法。它将输入样本分成 K 个具有相等方差的独立组,同时最小化点之间的距离。
K 均值需要聚类数作为输入参数。可以将其他超参数设置为质心初始化的参数。修复此参数可使算法具有确定性。您可以在此处找到有关参数的更多信息。n_clustersrandom_state
为了分割点云,我们首先对点进行归一化,然后拟合。这里我们设置为 4。n_clusters
# Normalisation:
scaled_points = StandardScaler().fit_transform(points)
# Clustering:
model = KMeans(n_clusters=4)
model.fit(scaled_points)K 均值将输入点云分割为 4 个聚类:将墙分割成 3 组,其余点重新分组为单个聚类。

这可能对某些应用程序有好处,但对其他应用程序则不然。在我们的例子中,我们想要墙作为一个整体,椅子,等等。换句话说,我们希望将它们分组到一个由非密集区域隔开的密集区域中。
四、数据库扫描
DBSCAN算法旨在将样本分离为具有低密度区域的高密度簇。不必事先定义聚类数。DBSCAN对噪声具有鲁棒性:在聚类过程中,异常值被检测并忽略,因此聚类过程不受它们的影响。
DBSCAN 需要两个超参数:分别表示形成聚类的最小点数和用于定位相邻要素的距离测量值。您可以在此处找到有关DBSCAN的更多信息。min_sampleseps
为了分割点云,我们首先对点进行归一化,然后拟合。在这里,我们设置为 10 点和 0.15。min_sampleseps
# Normalisation:
scaled_points = StandardScaler().fit_transform(points)
# Clustering:
model = DBSCAN(eps=0.15, min_samples=10)
model.fit(scaled_points)对于固定参数,DBSCAN将输入点云分成8个簇:墙被分割成4组,椅子被分成2组,桌子被分割成一组。这是由于传感器的性质:噪声产生了一些间隙。

五、投影点云
正如我们从前面的例子中看到的,墙和椅子上的一些部分是分开重新组合的。这没关系,但是,如果我们只对地面上占用的空间感兴趣怎么办?例如,找到自由行走的空间。
在这种情况下,我们不关心高度,就像我们关心地面上的被占领区域一样。因此,我们可以将所有点投影到地平面上。这样,所有点将具有相同的高度(y 坐标),这不会影响聚类。在地平面上投影点云需要估计地平面方程,然后找到投影矩阵。我知道,这有很多工作要做!但是,如果我们只忽略 y 坐标呢?后者甚至会减少运行时间,因为在聚类过程中只考虑两个属性!
让我们尝试一下,从可视化投影点云开始。这里所有点都投影在平面 OXZ (y=0) 上:
# Project points on OXZ plane:
points[:, 1] = 0
pcd_projected = o3d.geometry.PointCloud() # create point cloud object
pcd_projected.points = o3d.utility.Vector3dVector(points) # set pcd_np as the point cloud points
o3d.visualization.draw_geometries([pcd_projected])
在平面 OXZ 上投影点云。
现在,我们可以分割投影点云。请注意,为此,我们只考虑 x 和 z 坐标:
# projection: caonsider the x and z coordinates (y=0)
points_xz = points[:, [0, 2]]
# Normalisation:
scaled_points = StandardScaler().fit_transform(points_xz)
# Clustering:
model = DBSCAN(eps=0.15, min_samples=10)
model.fit(scaled_points)投影点云上的分割如下图所示:

或者在原始点云上:

通过投影,我们可以看到点云根据占用的空间进行分割,这对于许多应用程序来说更好。但是,对于其他应用程序,这可能不像精细分割那样工作,或者当有物体最初不在地面上时,例如投射路过的鸟!
六、结论
在本教程中,我们学习了如何使用 K 均值和 DBSCAN 分割点云。聚类算法的挑战是设置良好的超参数,这对于实际应用程序并不明显。作为练习,您可以针对不同的超参数值测试这些算法,也可以测试Scikit-learn提供的其他聚类算法。
谢谢,我希望你喜欢阅读这篇文章。您可以在我的 GitHub 存储库中找到示例。如果您有任何问题或建议,请随时在下面给我留言。