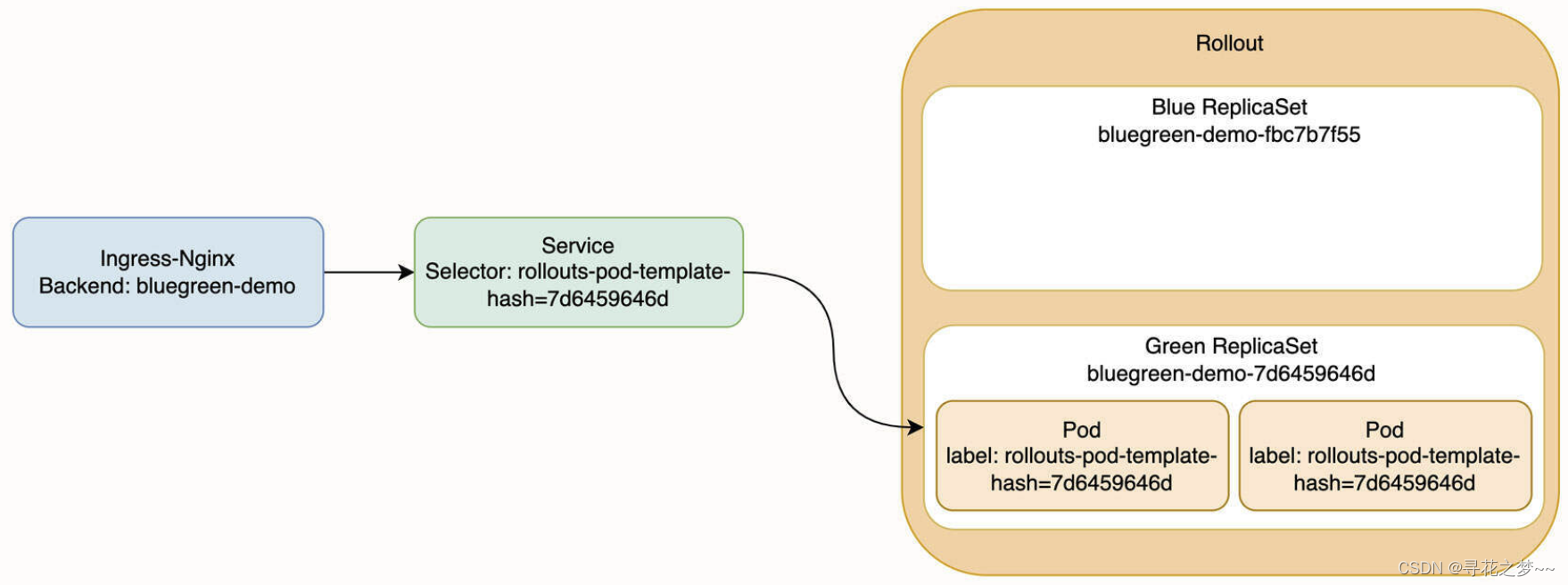
1. # 键盘输入一句话,用jieba分词后,将切分的词组按照在原话中逆序输出到屏幕上,词组中间没有空格。
示例如下:
输入:
我爱老师
输出:
老师爱我
import jieba
txt = input ('请输入一段中文文本:')
ls = jieba.lcut(txt)
for i in ls[::-1]:
print(i,end="")
2. 某商店出售品牌服装,每件定价150,1件不打折,2件(含)到3件(含)都打九折,4件(含)到9件(含)打八折,10件(含)以上打七折,键盘输入购买数量,屏幕输出总额(保留整数)。
输入:8
输出:总额为:960
n = eval(input("请输入数量:"))
if n == 1:
cost = 150
elif n >= 2 and n <= 3:
cost = int(n * 150 * 0.9)
elif n >= 4 and n <= 9:
cost = int(n * 150 * 0.7)
print("总额为:",cost)
3. 以255为随机数种子,随机生成5个在1(含)到50(含)之间的随机数,每个随机数后跟随一个空格进行分隔,屏幕输出这5个随机数。
import random
random.seed(255)
for i in range(5)
print(random.randint(1,50), end = ” “)
4. 键盘输入一个9800到9811之间的正整数n,作为Unicode编码,把n-1、n和n+1三个Unicode编码对应字符按照如下格式要求输出到屏幕:宽度为11个字符,加号字符+填充,居中 。
n = eval(input("请输入一个数字:"))
print("{:+^11}".format(chr(n - 1) + chr(n) + chr(n + 1)))
5. 从键盘输入一个中文字符串变量s,内部包含中文逗号和句号。计算字符串s中的中文词语数。示例如下: 请输入一个中文字符串,包含标点符号。
示例:
请输入一个中文字符,包含标点符号:问君能有几多愁?恰似一江春水向东流。
中文词语数:9
import jieba
s = input("请输入一个中文字符串,包含标点符号:")
m = jieba.lcut(s)
print("中文词语数:{}".format(len(m)))
6. 键盘输入一个十整数,按要求将这个整数转换为二进制、八进制和十六进制(大写)屏幕输出。
num = eval(input("输入数字:"))
print("对应的二进制数:{0:b}\n八进制数:{0:o}\n十六进制数:{0:X}".format((num)))
7. 编写一个函数,使之能够实现字符串的反转。将字符串“goodstudy”输入到函数中,运行并输出结果。
def str_change(str) :
return str[::-1]
str = input("输入字符串:")
print(str_change(str))
8. 使用循环输出从1到50之间的奇数
count = 0
while count < 50:
count += 1
if count % 2 == 0:
continue
print(count,end = ",")
9. 输入下面的绕口令,将其中出现的字符“兵”,全部替换为“将”,输出替换后的字符串。 八百标兵奔北坡,炮兵并排北边跑,炮兵怕把标兵碰,标兵怕碰炮兵炮。八了百了标了兵了奔了北了坡,把了标了兵了碰,标了兵了怕了碰了炮了兵了炮。
s = input("请输入绕口令:")
print(s.replace("兵","将"))
10. 使用time库把系统的当前时间信息以格式“2018年12月04日18时18分21秒”输出
import time
t = time.localtime()
print(time.strftime("%Y年%m月%d日%H时%M分%S秒",t))
总结
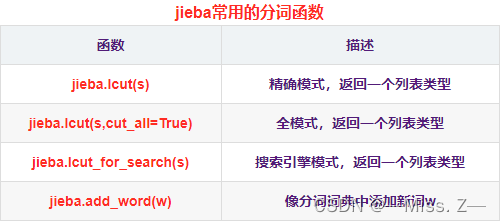
jieba库
jieba是python中的中文分词第三方库,可以将中文的文本通过分词获得单个词语,返回类型为列表类型。
jieba分词共有三种模式:精确模式、全模式、搜索引擎模式。
- 精确模式语法:jieba.lcut(字符串,cut_all=False),默认时为cut_all=False,表示为精确模型。精确模式是把文章词语精确的分开,并且不存在冗余词语,切分后词语总词数与文章总词数相同。
- 全模式语法:jeba.lcut(字符串,cut_all=True),其中cut_all=True表示采用全模型进行分词。全模式会把文章中有可能的词语都扫描出来,有冗余,即在文本中从不同的角度分词,变成不同的词语。
- 搜索引擎模式:在精确模式的基础上,对长词语再次切分。