目录
- 1 引言
- 2 Outer product attention (OPA)
- 3 Self-attentive Associative Memory (SAM)
- 4 SAM-based Two-Memory Model (STM)
- 5 实验结果
- 6 总结
- 7 参考资料
1 引言
这篇论文介绍了基于对象和对象关系的记忆模型,这对于设计类脑记忆模型有很大的启发作用。
2 Outer product attention (OPA)
标准transformer模型中定义的是内积注意力,即dot product attention:
A
°
(
q
,
K
,
V
)
=
∑
i
=
1
n
k
v
S
(
q
⋅
k
i
)
v
i
A^°(q, K, V ) = \sum ^{n_{kv}}_{i=1}S(q \cdot k_i) v_i
A°(q,K,V)=i=1∑nkvS(q⋅ki)vi
其中,
A
°
∈
R
d
v
,
q
,
k
i
∈
R
d
q
k
,
v
i
∈
R
d
v
A^° ∈ R^{d_v} , q, k_i ∈ R^{d_{qk}} , v_i ∈ R^{d_v}
A°∈Rdv,q,ki∈Rdqk,vi∈Rdv,
⋅
\cdot
⋅表示内积,计算结果是个标量,
S
S
S是一个对向量元素的softmax计算函数。
作者定义了外积注意力命名为Outer product attention:
A
⊗
(
q
,
K
,
V
)
=
∑
i
=
1
n
k
v
F
(
q
⊙
k
i
)
⊗
v
i
A^⊗ (q, K, V ) = \sum ^{n_{kv}}_{i=1} \text{F}(q ⊙ k_i) ⊗ v_i
A⊗(q,K,V)=i=1∑nkvF(q⊙ki)⊗vi
其中,
A
⊗
∈
R
d
q
k
×
d
v
,
q
,
k
i
∈
R
d
q
k
,
v
∈
R
d
v
A^⊗ ∈ R^{d_{qk}×d_v} , q, k_i ∈ R^{d_{qk}} , v ∈ R^{d_v}
A⊗∈Rdqk×dv,q,ki∈Rdqk,v∈Rdv,
⊙
⊙
⊙表示对应位置元素的相乘,计算结果是个同维数向量,
⊗
⊗
⊗表示外积,
F
F
F是一个对向量元素的tanh计算函数。
最好对照着标准注意力去理解。
差异:
A
°
A^°
A°是token序列中受注意力关注的token,
A
⊗
A^⊗
A⊗是token序列中token之间的关系表征。
3 Self-attentive Associative Memory (SAM)
作者设计了一个关联记忆网络模块,命名为SAM,用来表征item及item之间的关系。
SAM
θ
(
M
)
[
s
]
=
A
⊗
(
M
q
[
s
]
,
M
k
,
M
v
)
=
∑
j
=
1
n
k
v
F
(
M
q
[
s
]
⊙
M
k
[
j
]
)
⊗
M
v
[
j
]
\begin{align} \text{SAM}_θ (M) [s] &= A^⊗ (M_q [s] , M_k, M_v) \\ &=\sum ^{n_{kv}}_{j=1} \text{F} (M_q [s] ⊙ M_k [j]) ⊗ M_v [j] \end{align}
SAMθ(M)[s]=A⊗(Mq[s],Mk,Mv)=j=1∑nkvF(Mq[s]⊙Mk[j])⊗Mv[j]
其中,
与注意力相关的q,k,v三个向量
M
q
,
M
k
,
M
v
M_q,M_k,M_v
Mq,Mk,Mv:
M
q
=
L
N
(
W
q
M
)
M
k
=
L
N
(
W
k
M
)
M
v
=
L
N
(
W
v
M
)
\begin{align} M_q &= \mathcal{LN} (W_qM) \\ M_k &= \mathcal{LN} (W_kM) \\ M_v &= \mathcal{LN} (W_vM) \end{align}
MqMkMv=LN(WqM)=LN(WkM)=LN(WvM)
M是输入token序列组成的向量矩阵,
M
∈
R
n
×
d
M ∈ R^{n×d}
M∈Rn×d,n为token序列长度,d为token的维度;
s
s
s为M中第s行;
W
q
,
W
k
,
W
v
W_q,W_k,W_v
Wq,Wk,Wv是q,k,v对应线性变换层的参数矩阵;
L
N
\mathcal{LN}
LN是 layer normalization操作,而不是激活函数;
θ
θ
θ代表SAM模块的内部参数是
{
W
q
∈
R
n
k
v
×
n
,
W
k
∈
R
n
k
v
×
n
,
W
v
∈
R
n
k
v
×
n
}
\{W_q ∈ R^{n_{kv}×n},W_k ∈ R^{n_{kv}×n},W_v ∈ R^{n_{kv}×n}\}
{Wq∈Rnkv×n,Wk∈Rnkv×n,Wv∈Rnkv×n},
n
q
n_q
nq是query的个数,
n
k
v
n_{kv}
nkv是key-value对的个数;
4 SAM-based Two-Memory Model (STM)
作者设计了2个记忆模块分别为
M
t
i
∈
R
d
×
d
,
M
t
r
∈
R
n
q
×
d
×
d
M^i_t ∈ R^{d×d}, M^r_t ∈ R^{n_q×d×d}
Mti∈Rd×d,Mtr∈Rnq×d×d,都是基于SAM实现的,前者是用来记忆item,后者用来记忆item之间的关联关系。
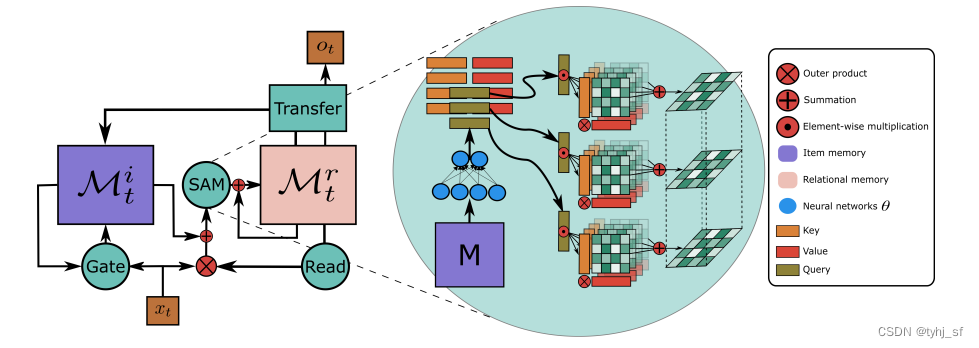
4.1 M i M^i Mi写操作
X
t
=
f
1
(
x
t
)
⊗
f
2
(
x
t
)
M
t
i
=
F
t
(
M
t
−
1
i
,
x
t
)
⊙
M
t
−
1
i
+
I
t
(
M
t
−
1
i
,
x
t
)
⊙
X
t
\begin{align} X_t &= f_1 (x_t) ⊗ f_2 (x_t) \\ M^i_t &= F_t(M^i_{t−1} , x_t) ⊙ M^i_{t−1} + I_t(M^i_{t−1} , x_t) ⊙X_t \end{align}
XtMti=f1(xt)⊗f2(xt)=Ft(Mt−1i,xt)⊙Mt−1i+It(Mt−1i,xt)⊙Xt
其中,
x
t
x_t
xt是输入数据;
f
1
,
f
2
f_1, f_2
f1,f2是前馈神经网络,输出维度为d;
F
t
F_t
Ft为遗忘门,计算公式为
F
t
(
M
t
−
1
i
,
x
t
)
=
W
F
x
t
+
U
F
t
a
n
h
(
M
t
−
1
i
)
+
b
F
F_t(M^i_{t−1} , x_t)= W_F x_t + U_F\mathcal tanh(M^i_{t−1}) + b_F
Ft(Mt−1i,xt)=WFxt+UFtanh(Mt−1i)+bF,其中
W
F
,
U
F
∈
R
d
×
d
W_F , U_F ∈ R^{d×d}
WF,UF∈Rd×d为网络参数;
I
t
I_t
It为输入的门控,计算公式为
I
t
(
M
t
−
1
i
,
x
t
)
=
W
I
x
t
+
U
I
t
a
n
h
(
M
t
−
1
i
)
+
b
I
I_t(M^i_{t−1} , x_t)= W_I x_t + U_I\mathcal tanh(M^i_{t−1}) + b_I
It(Mt−1i,xt)=WIxt+UItanh(Mt−1i)+bI,其中
W
I
,
U
I
∈
R
d
×
d
W_I , U_I ∈ R^{d×d}
WI,UI∈Rd×d为网络参数;
4.2 M r M^r Mr读操作
v
t
r
=
s
o
f
t
m
a
x
(
f
3
(
x
t
)
⊤
)
M
t
−
1
r
f
2
(
x
t
)
\begin{align} v^r_t = \mathcal{softmax}(f_3 (x_t)^⊤) M^r_{t−1} f_2 (x_t) \end{align}
vtr=softmax(f3(xt)⊤)Mt−1rf2(xt)
其中,
v
t
r
v^r_t
vtr为从关系记忆模块
M
r
M^r
Mr中读出的值,将在下式(9)中使用;
f
3
f_3
f3是前馈神经网络,输出维度为
n
q
n_q
nq;
M
t
−
1
r
M^r_{t−1}
Mt−1r为
M
r
M^r
Mr的前一个状态,其状态值由下式(9)计算得到;
4.3 M i M^i Mi读操作和 M r M^r Mr写操作过程
M
t
r
=
M
t
−
1
r
+
α
1
SAM
θ
(
M
t
i
+
α
2
v
t
r
⊗
f
2
(
x
t
)
)
\begin{align} M^r_t = M^r_{t−1} + α_1 \text{SAM}_ \theta (M^i_t + α_2 v^r_t ⊗ f_2 (x_t)) \end{align}
Mtr=Mt−1r+α1SAMθ(Mti+α2vtr⊗f2(xt))
其中,
α
1
,
α
2
α_1,α_2
α1,α2是调和超参数,用于平衡量纲的,又类似于学习率;
4.4 用 M r M^r Mr实现item转移
M
i
M^i
Mi利用
M
r
M^r
Mr实现更新,可以认为是hebbian更新,更新公式如下:
M
t
i
=
M
t
i
+
α
3
G
1
◦
V
f
◦
M
t
r
\begin{align} M^i_t = M^i_t + α_3 \mathcal{G_1} ◦ \mathcal{V_f} ◦ M^r_t \end{align}
Mti=Mti+α3G1◦Vf◦Mtr
其中,
V
f
\mathcal{V_f}
Vf是输入X(其shape为(batch_size, sequeue_length, dimension))的前两维展开的向量;
G
1
\mathcal{G_1}
G1是前馈神经网络,负责维度变换
R
(
n
q
d
)
×
d
→
R
d
×
d
R^{(n_qd)×d} → R^{d×d}
R(nqd)×d→Rd×d,其计算公式为
G
1
(
X
)
=
W
g
V
f
(
X
)
\mathcal{G_1}(X) = W^g\mathcal{V_f}(X)
G1(X)=WgVf(X);
α
3
α_3
α3是调和超参数;
4.5 模型输出 o t o_t ot
o
t
=
G
3
◦
V
l
◦
G
2
◦
V
l
◦
M
t
r
\begin{align} o_t = \mathcal{G_3} ◦ \mathcal{V_l} ◦ \mathcal{G_2} ◦ \mathcal{V_l} ◦ M^r_t \end{align}
ot=G3◦Vl◦G2◦Vl◦Mtr
其中,
V
l
\mathcal{V_l}
Vl是输入X(其shape为(batch_size, sequeue_length, dimension))的后两维展开的向量;
G
2
,
G
3
\mathcal{G_2},\mathcal{G_3}
G2,G3是前馈神经网络,分别负责维度变换
R
n
q
×
d
d
→
R
d
×
d
R^{n_q×dd} → R^{d×d}
Rnq×dd→Rd×d,
R
n
q
n
r
→
R
n
o
R^{n_qn_r} → R^{n_o}
Rnqnr→Rno,其计算公式为
G
2
(
X
)
=
W
g
V
l
(
X
)
\mathcal{G_2}(X) = W^g\mathcal{V_l}(X)
G2(X)=WgVl(X),
n
q
n_q
nq是query的个数,
n
r
n_r
nr是超参数;
5 实验结果
源代码:https://github.com/thaihungle/SAM
作者做了消融实验,并在几何与图任务、强化学习任务、问答任务上做了测试。具体可以看论文附录和源码。
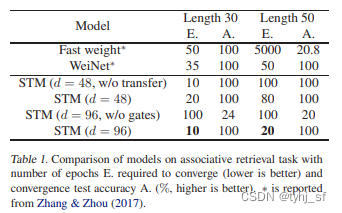
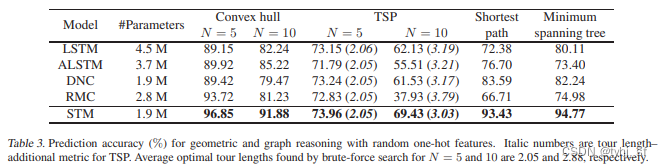
6 总结
该论文一个有趣的idea就是用两个前馈神经网络 M i , M r M^i,M^r Mi,Mr分别表示对象与对象间关系,但是参数更新方法不是梯度下降而是赫布更新,后续可能是一个改进点。
7 参考资料
[1]. Self-Attentive Assocative Memory , 2020.