为了解决在图像合成时候小物体容易消失,大物体经常作为块的拼接来生成的。本文提出DP-GAN在所有尺度下共同学习空间自适应归一化模块的条件。这样尺度信息就会被双向使用,他统一了不同尺度的监督。(重点看图和代码)
SPADE模块解释
GAN在生成包含许多不同物体的复杂场景时非常具有挑战,由于归一化的存在,分割图会退化。SPADE(《Semantic Image Synthesis with Spatially-Adaptive Normalization》)通过正向传递语义信息来解决上述问题。大多数的网络将标签作为输入,然后做一个全局的判别。因为一个全局的辨别器不会强迫生成器去学习和输入的语义标签图进行准确的对齐。
本文旨在从语义图不同的尺度生成类似真实的物体。这需要解决生成器和辨别器不同的图片尺寸问题。我们通过一个金字塔来使用每个尺度。
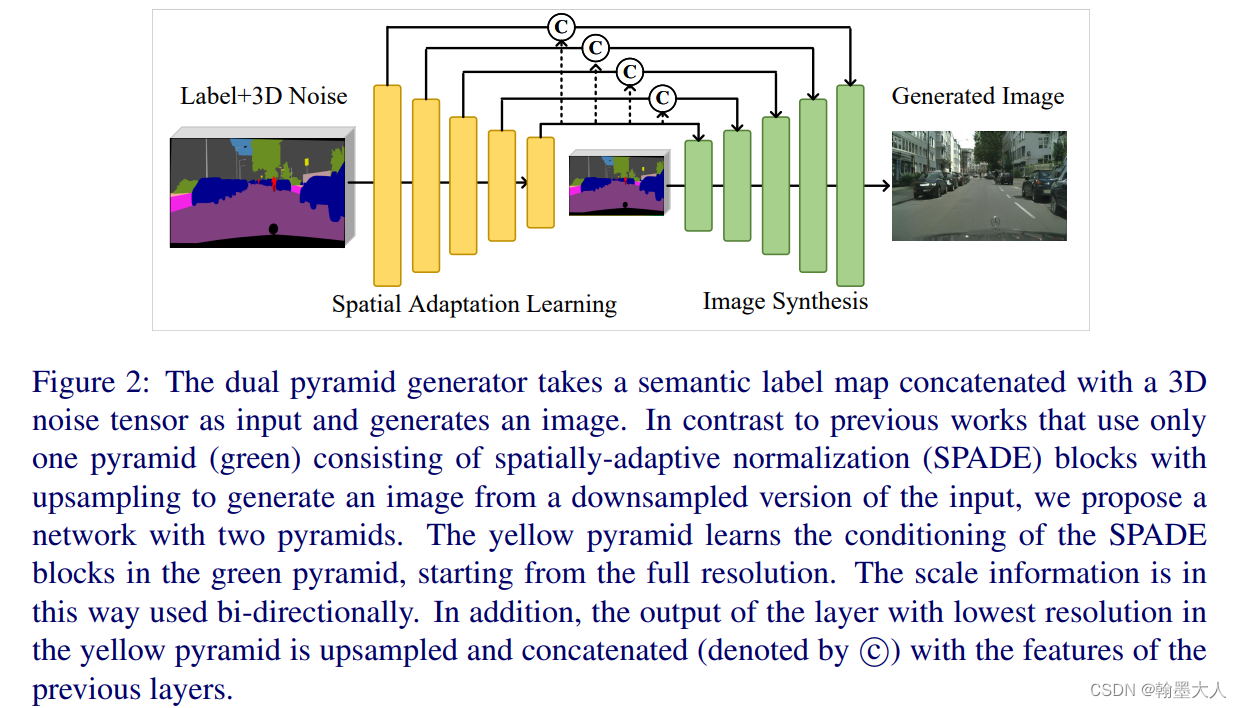
为了解决细小物体退化问题,我们在不同尺度引入了多尺度监督的不同类型。第一个是多尺度特征匹配损失,他鼓励生成器在所有尺度生成和语义图对齐的图片,第二个是在每一个块使用多尺度对抗监督。他鼓励在辨别器时重要的尺度信息可以保留。
总结:1:提出一个双金字塔生成器用于语义图像合成。2:在像素,块,特征三个层面促使生成器生成和语义图对齐的真实的物体。
方法:
双金字塔生成器,一个金字塔用于图像合成,另一个用于空间适应学习。生成器输入是标签图和3D噪声的逐通道拼接。不同的噪声可以产生不同风格的图片。

SPADE实现过程:

在本文公式:

在原始SPADE中,γ和β是特征图经过卷积学习到的。在本文类似但是做了修改,修改的原因是特征图经过下采样,细小的物体已经消失,就会在不同尺度带来大量的冗余信息。作者将最后一层的输出上采样到之前层的大小,然后和原始的每一层输出相加再进过卷积。通过在不同尺度进行SPADE的学习,这样生成的结果就会更加的真实。

尺度增强辨别器:
使用一个包含resnet的编码解码结构,模型预测N+1个类别,N是语义类别数,1是假的类别。在训练时候,对于真实图片每一个像素都是由输入标签图定义,对于生成图片每一个像素都是由假类别定义。这样一个N+1类别交叉熵可以定义为:

逐像素的损失不够,我们还添加了另外两个损失。第一个是基于块的多尺度对抗损失,应用于低分辨率的特征图:

第二个是多尺度特征匹配损失,在真实图和预测图之间使用L2损失,用于训练生成器。


训练:
对于生成器使用损失:
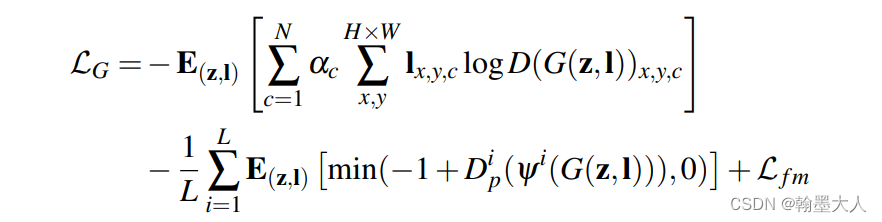
正则化:
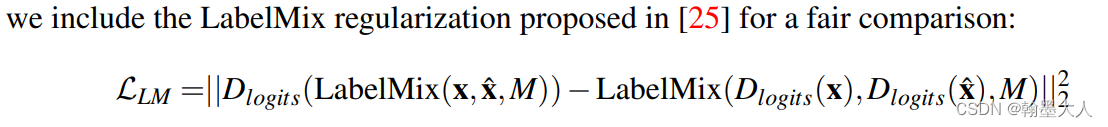
总损失:
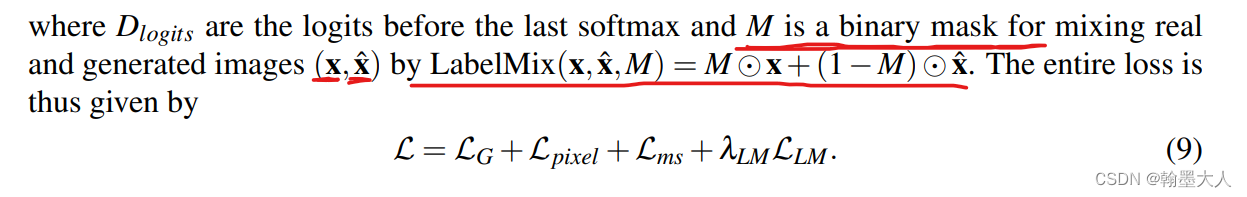
**实验:**使用mIoU和FID进行评估。
Dual pyramid GAN for semantic image synthesis
news2026/2/12 18:52:49
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/811702.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

JavaScript学习 -- 对称加密算法DES
在现代的互联网时代,数据安全性备受关注。为了保护敏感数据的机密性,对称加密算法是一种常用的方法。在JavaScript中,DES(Data Encryption Standard)是一种常用的对称加密算法。本篇博客将为您展示如何在JavaScript中使…
npm i 报错项目启动不了解决方法
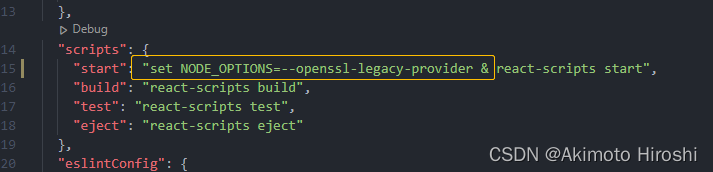
1.场景
在另一台电脑低版本node环境跑的react项目,换到另一台电脑node18环境执行npm i时候报错 2.解决方法
脚本前加上set NODE_OPTIONS--openssl-legacy-provider
使用稀疏性(微球)进行色谱图基线估计和去噪(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…

树莓派上安装cmake
前言
记录一下在树莓派上安装cmake,因为之间安装出了点问题,但是后面解决了,于是记录一下。 直接安装报大红,看的我心里一颤 废话不多说,接下来上操作步骤
网上有的教程让wget下载压缩包,但是咱们就是不知道为啥我这样操作就是也报错,但是我感觉原理上是🆗的,并且…

Java程序逻辑控制(三种基本结构(顺序、分支、循环)、输入输出、循环输入)
目录 一、顺序结构
二、分支结构
1、 if 语句
2、switch 语句
与C语言不同,不能作为switch参数的类型:float double long boolean
三、循环结构
1.while循环
2.for循环 四、输入输出
1.输出 - 将结果显示打印到屏幕上
2.输入
3.输入输出综合…

用友畅捷通T+服务器数据库中了locked勒索病毒怎么办,如何处理解决
计算机技术的发展,也为网络安全埋下隐患,其中勒索病毒攻击已经成为企业和组织面临的严重威胁之一。作为一款被广泛使用的企业资源管理软件,用友畅捷通T系统也成为黑客攻击的目标之一。近期,我们收到很多企业的求助,公司…
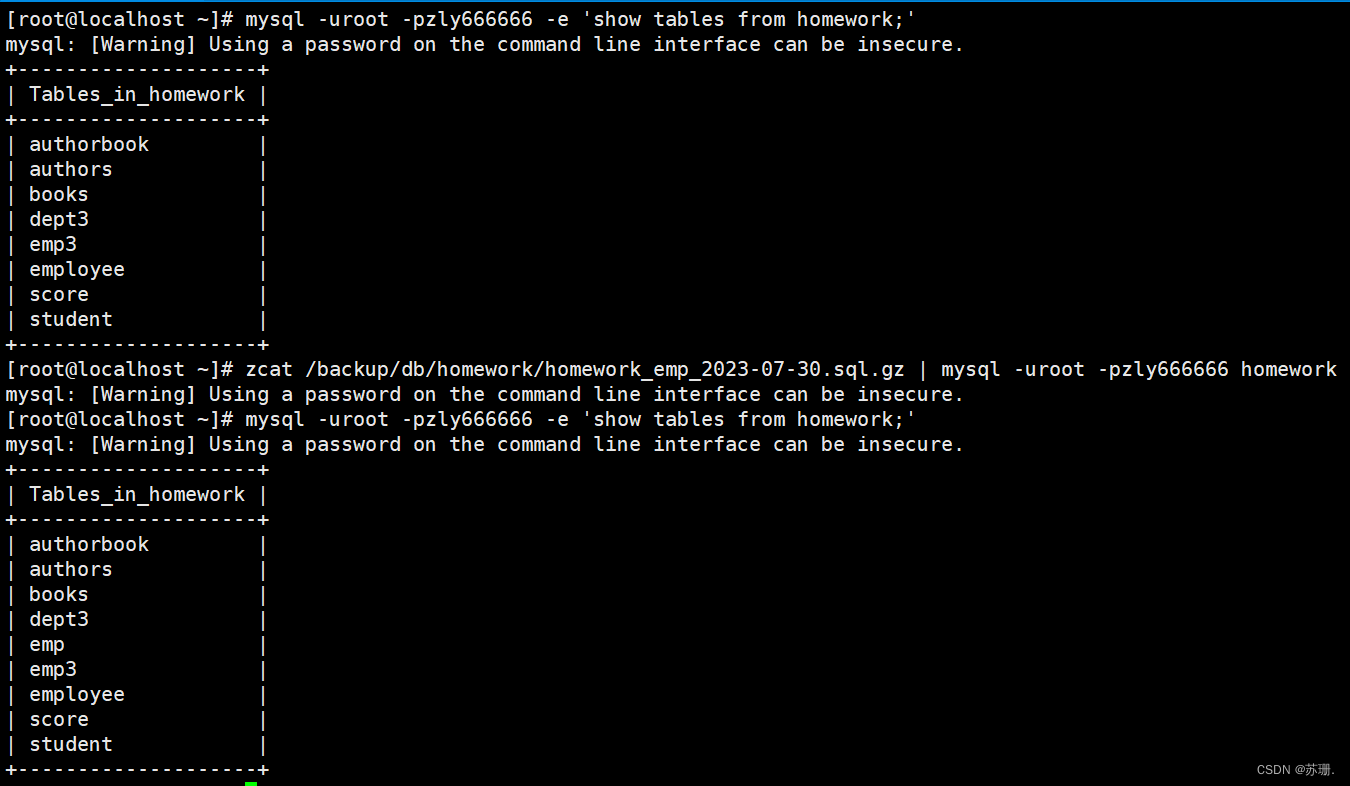
Shell脚本实现分库分表操作
目录
一,分库备份
二,分库操作
三,分库分表备份
四,备份还原 一,分库备份
#!/bin/bash
mysql_cmd-uroot -pzly666666
bak_path/backup/db
[ -d ${bak_path} ] || mkdir -p ${bak_path}mysql ${mysql_cmd} -e show…
【CNN-BiLSTM-attention】基于高斯混合模型聚类的风电场短期功率预测方法(Pythonmatlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…
FFmpeg 音视频开发工具
目录
FFmpeg 下载与安装
ffmpeg 使用快速入门
ffplay 使用快速入门 FFmpeg 全套下载与安装
1、FFmpeg 是处理音频、视频、字幕和相关元数据等多媒体内容的库和工具的集合。一个完整的跨平台解决方案,用于录制、转换和流式传输音频和视频。 官网:http…
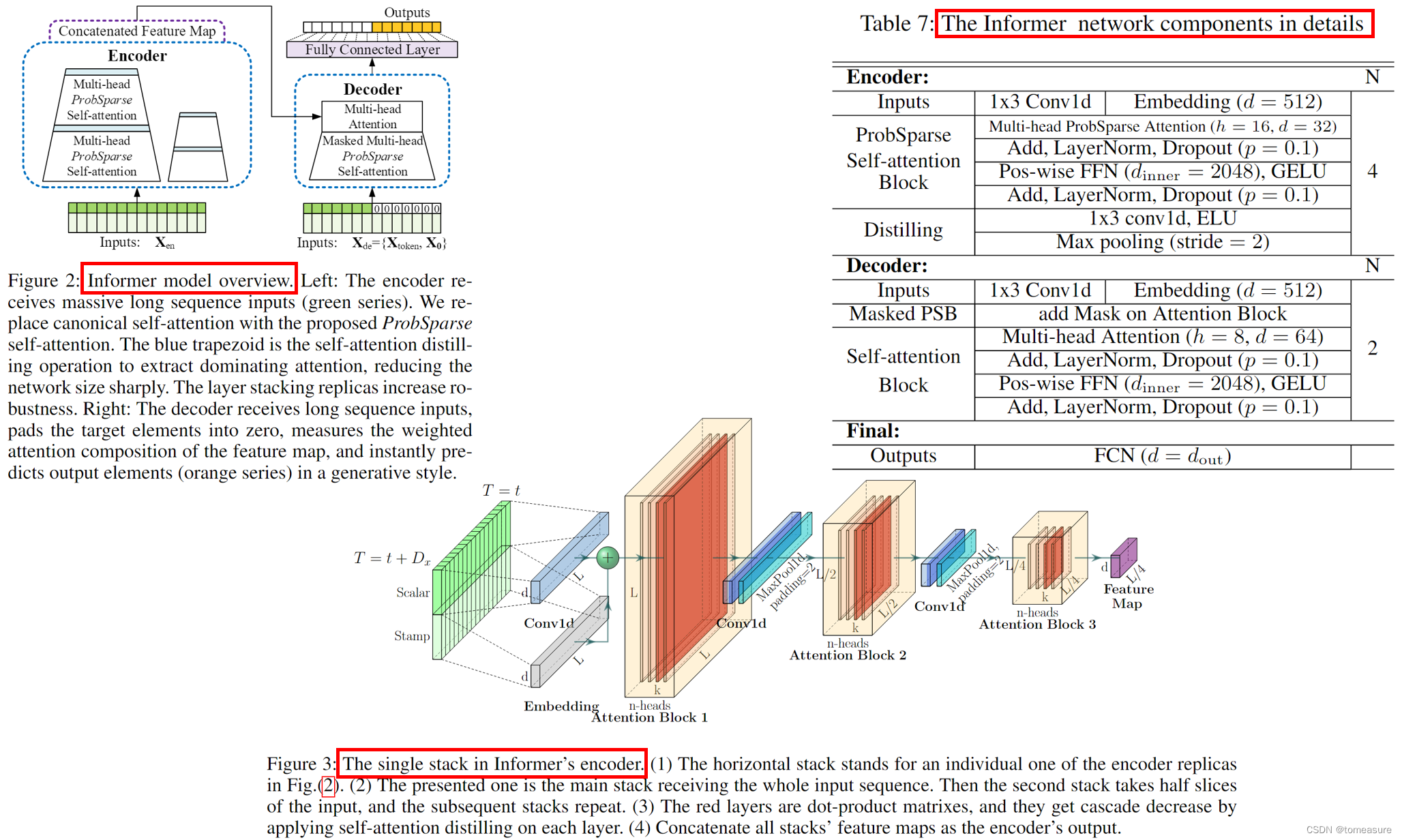
Informer 论文学习笔记
论文:《Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting》 代码:https://github.com/zhouhaoyi/Informer2020 地址:https://arxiv.org/abs/2012.07436v3 特点:
实现时间与空间复杂度为 O ( …

LaTex4【下载模板、引入文献】
下载latex模板:(模板官网一般都有,去找)
我这随便找了一个: 下载得到一个压缩包,然后用overleaf打开👇: (然后改里面的内容就好啦) 另外,有很多在线的数学公式编辑器&am…

1 Python的前世今生
为什么要学Python 这个问题,仁者见仁,智者见智。编程界有一句名言:“人生苦短,我用Python”,这句话似乎道出了一些原因。Python是一门简单直观的语言,更是一门注重可读性和效率的语言。解决同一个问题&…
jmeter常用的性能测试监听器
jmeter中提供了很多性能数据的监听器,我们通过监听器可以来分析性能瓶颈
本文以500线程的阶梯加压测试结果来描述图表。 常用监听器
1:Transactions per Second
监听动态TPS,用来分析吞吐量。其中横坐标是运行时间,纵坐标是TPS…

【后端面经】微服务构架 (1-6) | 隔离:如何确保心悦会员体验无忧?唱响隔离的鸣奏曲!
文章目录 一、前置知识1、什么是隔离?2、为什么要隔离?3、怎么进行隔离?A) 机房隔离B) 实例隔离C) 分组隔离D) 连接池隔离 与 线程池隔离E) 信号量隔离F) 第三方依赖隔离二、面试环节1、面试准备2、基本思路3、亮点方案A) 慢任务隔离B) 制作库与线上库分离三、章节总结 …
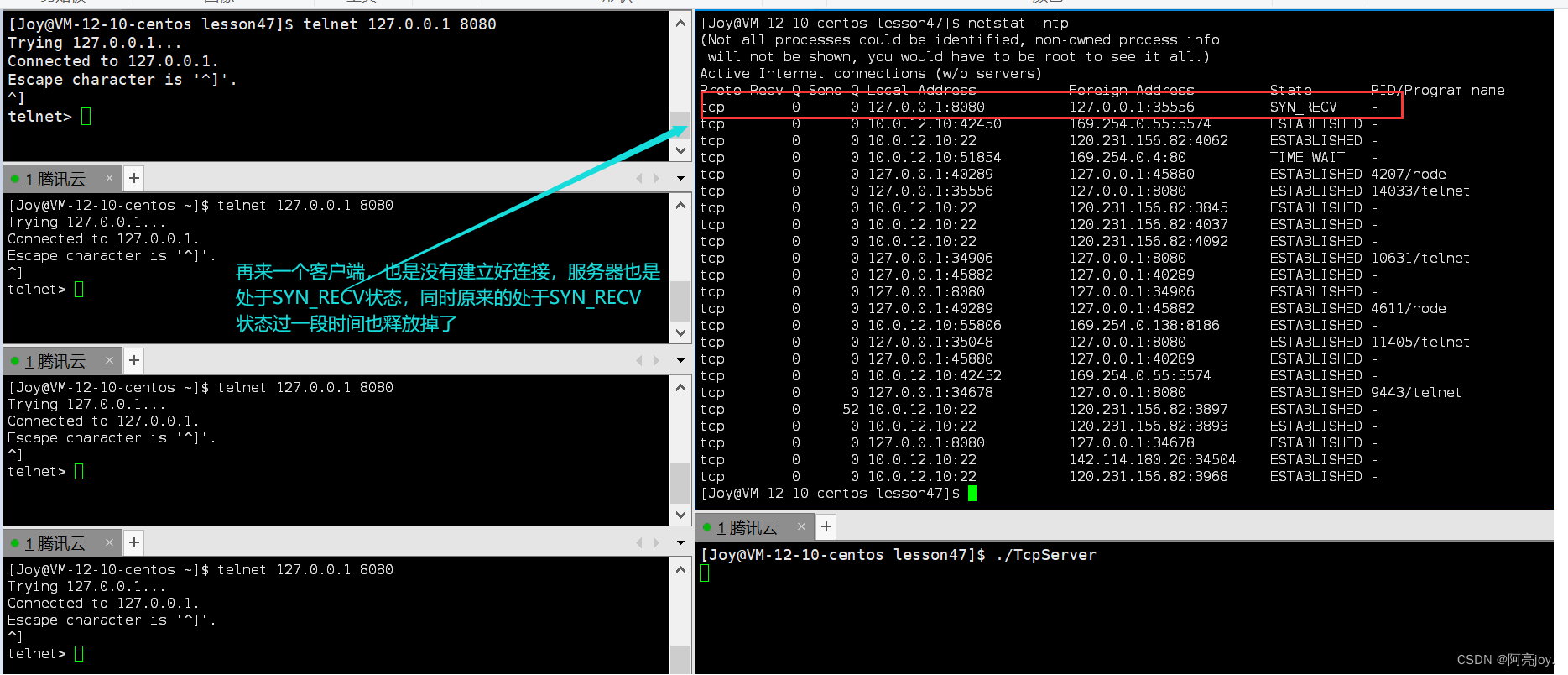
【Linux】TCP协议
🌠 作者:阿亮joy. 🎆专栏:《学会Linux》 🎇 座右铭:每个优秀的人都有一段沉默的时光,那段时光是付出了很多努力却得不到结果的日子,我们把它叫做扎根 目录 👉TCP协议&…
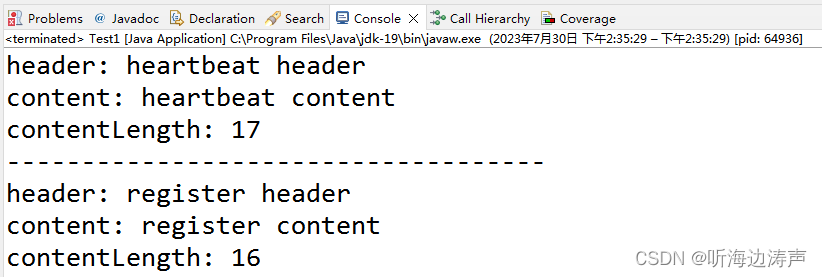
java设计模式-建造者(Builder)设计模式
介绍
Java的建造者(Builder)设计模式可以将产品的内部表现和产品的构建过程分离开来,这样使用同一个构建过程来构建不同内部表现的产品。
建造者设计模式涉及如下角色:
产品(Product)角色:被…