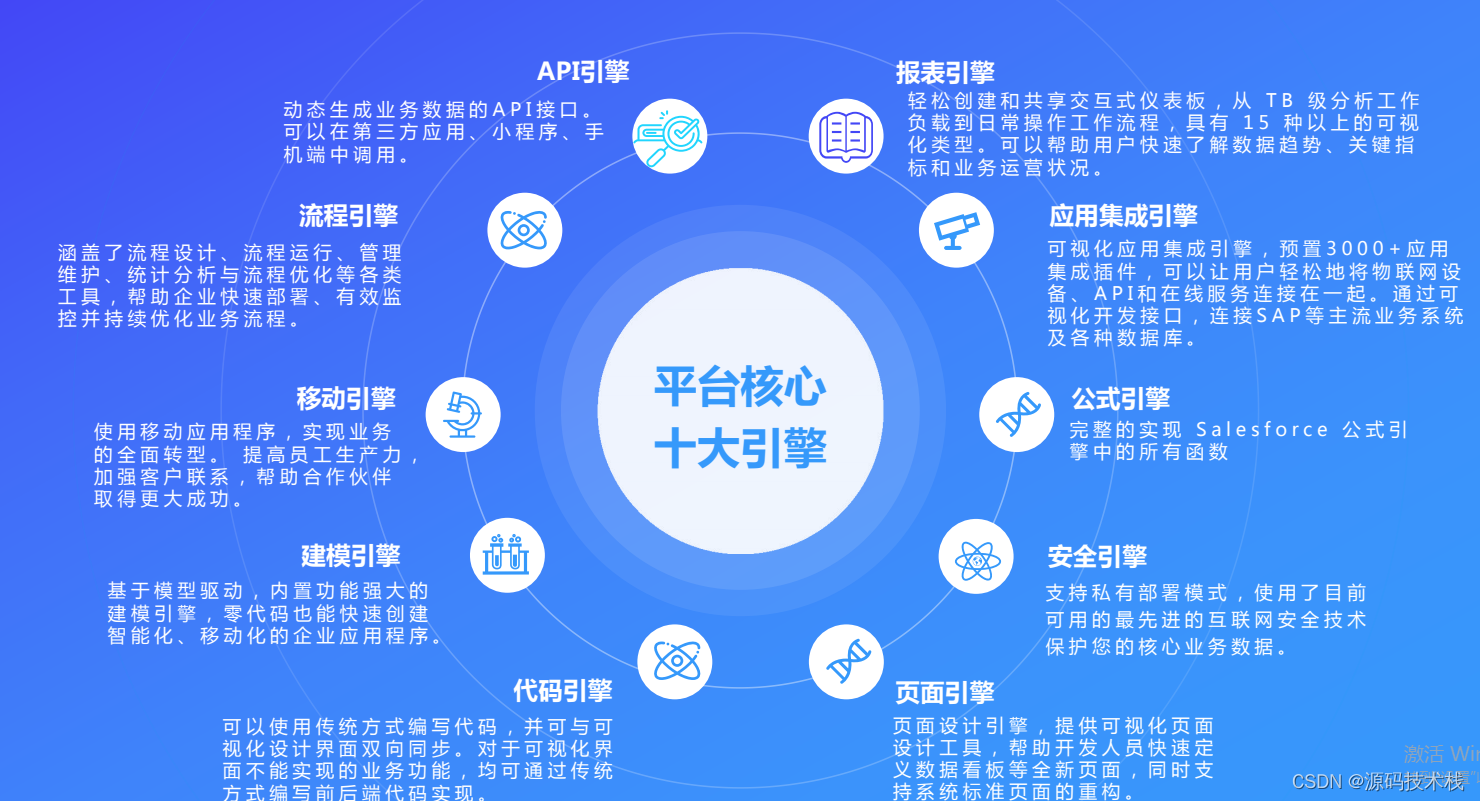
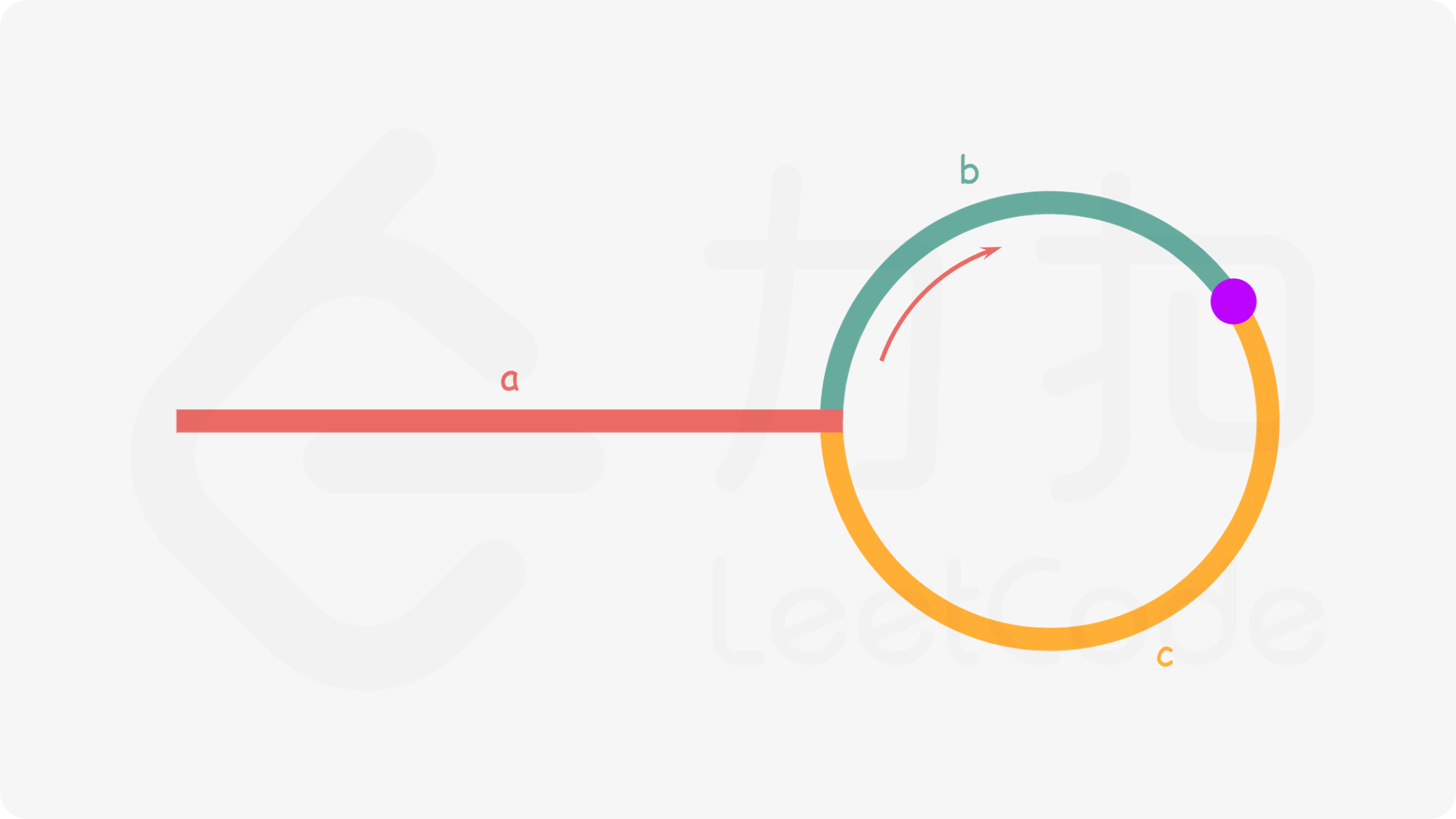SIMD系列-GATHER/SCATTER操作
众所周知,SIMD寄存器可以使用LOAD/STORE操作与标量域(或者更准确的说是内存)进行通信。这些操作的缺点是:只允许移动内存中连续的数据元素。然而,我们代码中,经常需要访问非连续的内存。本教程中将解释GATHER/SCATTER操作以及他们如何类推到LOAD/STORE操作。
某些情况下,您可能希望使用来自非连续内存位置的数据填充寄存器。几个使用例子:
1)访问数组中的每隔一个元素(跨步访问)
2)以新计算的偏移量访问数组的元素(索引访问)
3)以不同顺序访问元素(随机访问)
本文讨论前两种情况。最后一类需要在permutations背景下进行更彻底的讨论,因此我们将在下一个教程中讨论。
那么什么是SCATTER操作呢?它是GATHER操作的逆操作,将寄存器的内容“分散”到内存中。因此类似于STORE操作,但能够进行非连续内存访问。
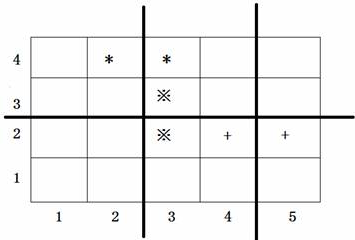
1、Stried access跨步访问
当访问的内存字段距离相等时,内存访问模式称为跨步。这个距离称为步幅(不要与SIMD步幅混淆)。跨步访问的简单图示:
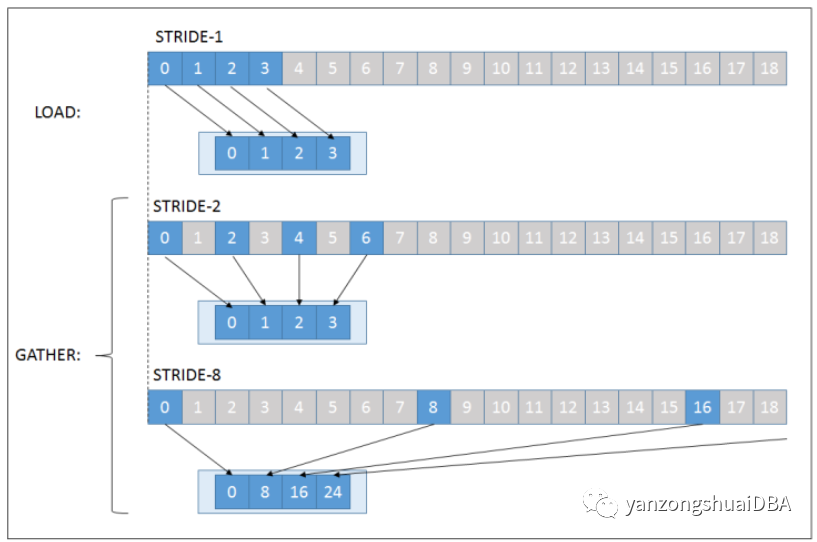
正如你所见,STRIDE-1访问是GATHER操作符的特殊情况:LOAD操作。那为什么我们有单独的LOAD和GATHER操作(以及STORE和SCATTER),而不仅仅简化事情并仅使用GATHER?有2种解释,首先是一个历史问题:早期处理器仅实现LOAD指令在内存和标量寄存器之间移动数据。由于在标量域中,您可以使用单个标量索引访问任何元素,因此不需要更灵活的操作。其次,是性能方面:除了传递基内存地址外,GATHER指令还需要如何计算指定偏移的相关信息。无论指令在处理器内如何实现,这都是额外的自由度,可能意味着更长的执行时间,但肯定意味着额外的电路。
性能提示尽可能使用LOAD/STORE操作,并尽可能避免GATHR/SCATTER。在大多数情况下,意味着必须修改您的数据结构/算法。但当您确定无法重新设计结构时,才使用GATHE/SCATTER。
执行跨步访问时,需要知道什么是基地址(作为指向数据开头的指针传递)和跨步值(作为标量整数传递)。步幅始终作为元素数量而不是内存偏移量传递,以便可以简化编程。
以下代码展示了如何执行跨步内存访问:
float a[LARGE_DATA_SIZE];
uint32_t STRIDE = 8;
...
for(int i = 0; i < PROBLEM_SIZE; i+=8) {
SIMDVec<float, 8> vec;
// Note that we have to scale the loop index.
int offset = i*STRIDE;
// 'load' the data to vec.
vec.gather(&a[offset], STRIDE);
// do something useful
vec += 3.14;
// store the result at original locations
vec.scatter(&a[offset], STRIDE);
}当使用跨步访问时,我们必须传递第一个元素地址。这是通过在每次迭代中计算偏移变量来完成的。然后,GATHER操作使用该本地基地址和标量步幅来计算相应元素的偏移量。
一旦必要的计算结束,更新的结果将存储回原始位置。
2、Indexed access索引访问
Indexed access比跨步访问更通用。主要区别在于,您必须传递无符号整数索引的SIMDVec,而不是传递标量步幅参数。Indexed access可以使用下图理解:
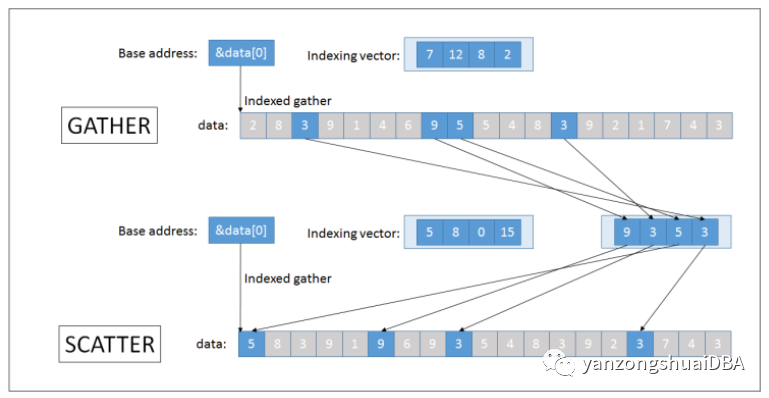
这种模式的优点是,每个元素都可以使用专用索引来检索。缺点是这种方式的索引可能会完全破坏基于硬件的内存预取,进而对性能产生负面影响。另外注意,所有元素可能都离得很远,这意味着必须将更多缓存行移动到最低缓存级别。使用索引访问的示例:
float a[LARGE_DATA_SIZE];
int indices[PROBLEM_SIZE];
uint32_t STRIDE = 4;
...
for(int i = 0; i < PROBLEM_SIZE; i+=8) {
SIMDVec<float, 8> vec;
// Here we are using precomputed indices,
// but they can be computed on-the-fly if necessary.
SIMDVec<uint32_t, 8> indices_vec(&indices[i];
// 'load' the data to vec.
vec.gather(&a[0], indices_vec);
// do something useful
vec += 3.14;
// store the result at original locations
vec.scatter(&a[0], indices_vec);
}基本区别在于,我们将使用32b索引的无符号整数向量,而不是传递标量步长。
注意:目前该库正在使用与所有gathered向量的标量元素具有相同精度的无符号整数向量。当处理混合精度以及小类型(例如uint8_t)没有足够的位来表示完整范围的索引时,这回导致麻烦。该库将更新为始终使用uint32_t索引向量。
3、确保有条件访问
编写代码时可能会发现的问题之一是:尝试处理条件语句。考虑以下标量代码:
float a[PROBLEM_SIZE], b[PROBLEM_SIZE];
float c[LARGE_DATASET_SIZE];
...
for(int i = 0; i < PROBLEM_SIZE; i++) {
// Here we are checking if for some reason one of the
// values in (a[i],b[i]) pair is not determined properly.
if (std::isfin(a[i] - b[i])) {
// Calculate the index only if both 'a' and 'b' are well defined
int index = int(a[i] - b[i]);
// 'gather' single element at a time
float temp = c[index];
// Do something with the value
temp += 3.14;
// Update the values of 'c'
c[index] = temp;
}
}您应该已经知道:请参阅 UME::SIMD Tutorial 8: Conditional execution using masks。使用掩码的向量代码将执行if分支内的所有操作。将上面代码重写:
float a[PROBLEM_SIZE], b[PROBLEM_SIZE];
float c[LARGE_DATASET_SIZE];
...
// For simplification we are assuming that: ((PROBLEM_SIZE % 8) == 0)
for(int i = 0; i < PROBLEM_SIZE; i+= 8) {
// Here we are checking if for some reason (e.g. a design decision) one
// of the values in (a[i],b[i]) pair is not determined properly.
SIMDVec<float, 8> a_vec(&a[i]), b_vec(&b[i]);
SIMDVecMask<8> condition = (a_vec - b_vec).isfin();
// if (std::isfin(a[i] - b[i])) {
SIMDVec<uint32_t, 8> indices = a_vec - b_vec;
SIMDVec<float, 8> temp;
temp.gather(&c[0], indices); // This is WRONG!!!
temp.adda(condition, 3.14); // only change selected elements
temp.scatter(&c[0], indices); // Again WRONG!!!
}为什么这段代码中的GATHER和SCATTER操作是错误的?即使索引不正确,它们都试图访问内存。但 GATHER 和 SCATTER 都不关心这一点。他们必须相信我们能为他们提供正确的索引,至少出于性能原因。如果索引不正确,它们将尝试访问可能位于“c”数据集边界之外的内存。这可能会导致内存故障,因此我们必须使用条件掩码来保护内存读取和写入:
float a[PROBLEM_SIZE], b[PROBLEM_SIZE];
float c[LARGE_DATASET_SIZE];
...
// For simplification we are assuming that: ((PROBLEM_SIZE % 8) == 0)
for(int i = 0; i < PROBLEM_SIZE; i+= 8) {
// Here we are checking if for some reason (e.g. by design?) one of the
// values in (a[i],b[i]) pair is not determined properly.
SIMDVec<float, 8> a_vec(&a[i]), b_vec(&b[i]);
SIMDVecMask<8> condition = (a_vec - b_vec).isfin();
// if (std::isfin(a[i] - b[i])) {
SIMDVec<uint32_t, 8> indices = a_vec - b_vec;
SIMDVec<float, 8> temp;
temp.gather(condition, &c[0], indices); // Now the read is CORRECT!!!
temp += 3.14; // we don't have to mask this operation
temp.scatter(condition, &c[0], indices); // Again no problems here.
}因此,在更正后的版本中,我们必须简单地将附加掩码参数传递给内存访问操作,而不是算术运算。该库将负责保护读取的安全,以便它们仅访问允许的内存地址。
4、总结
介绍了 GATHER/SCATTER 操作的概念,并解释了为什么它们是我们的 SIMD 编程模型的有用补充。我们研究了跨步和索引内存访问模式,并解释了这个概念如何概括 LOAD/STORE 操作。
虽然非常有用,但“GATHER/SCATTER”操作是一把双刃剑,既可以让我们的生活更轻松,也可以破坏我们的性能。
5、原文
https://gain-performance.com/2017/06/15/umesimd-tutorial-9-gatherscatter-operations/


![【PWN · Stack Smash】[2021 鹤城杯]easyecho](https://img-blog.csdnimg.cn/3286ed7a192649d68588888b63a46a07.png)
![解决问题:python PermissionError: [WinError 5]拒绝访问](https://img-blog.csdnimg.cn/d45e761c98454943ae2d59a40f9d37af.png)