本深度学习入门教程是在polyu HPCStudio 启发以及资源支持下进行的,在此也感谢polyu以及提供支持的老师。
本文内容:在GoogleColab平台上使用预训练模型来文字生成图片Text To Image Generation With Network
(1)你会学到什么:
了解什么是从文本生成图像以及如何使用它。 使用预先训练的模型来创造你的艺术以及如何让它变得更好
(2)大纲outline:
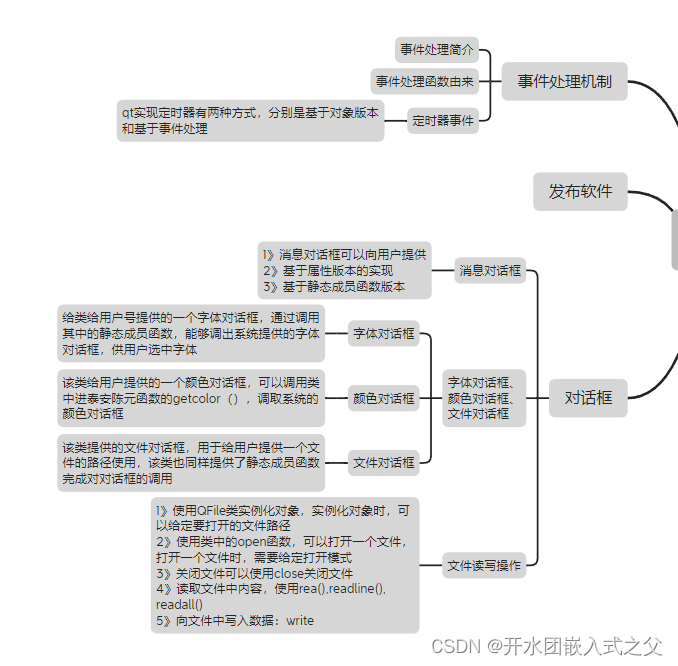
1:什么是文本到图像生成?
2:什么是稳定扩散?
3:快速工程prompt project
4:使用预训练模型生成图像的示例代码
1:什么是文本到图像生成?
文本到图像模型是一种机器学习模型,它将自然语言描述作为输入并生成与该描述匹配的图像。 由于深度神经网络的进步,此类模型于 2010 年代中期开始开发。 2022 年,最先进的文本到图像模型的输出,例如 OpenAI 的 DALL-E 2、Google Brain 的 Imagen、Midjourney 和 StabilityAI 的 Stable Diffusion 的输出开始接近真实照片和人类绘制艺术的质量。
文本到图像模型通常结合了语言模型和生成图像模型,其中语言模型将输入文本转换为潜在表示,生成图像模型生成以该表示为条件的图像。 最有效的模型通常是根据抓取的大量图像和文本数据进行训练的来自网络。

2:什么是稳定扩散 stable diffusion
Stable Diffusion 是 2022 年发布的深度学习文本到图像模型。它主要用于生成以文本描述为条件的详细图像,但它也可以应用于其他任务,例如修复、外绘和生成,由文本提示引导的图像到图像的翻译。
- 超分辨率 - 对输入图像进行去噪
- 潜在扩散模型 - 一次又一次地去噪
- 模拟出全新形象
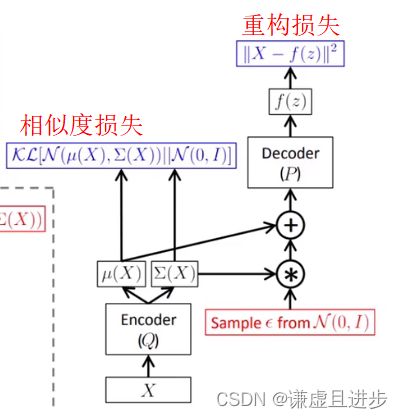
Stable diffusion 的结构
A text encoder文本编码器,可将您的提示转换为潜在向量。
A diffusion model扩散模型,反复对 64x64 潜在图像块进行“去噪”。
A decoder 解码器,将最终的 64x64 潜在补丁转换为更高分辨率512x512 图像。
3:快速工程 prompt project?
Prompt project是一种用特定措辞创作出优秀艺术作品或指示人工智能(机器人)提供所需输出(一般而言)的技能。
-
核心提示——主要主题。 例如 主角男孩、女孩、老人、动物等,多一些描述和形容词就更好了。
-
风格 - 例如 铅笔画、油画、照片等。
-
. 艺术家 - 例如 Vincent Van Gogh、Leonardo DaVinci、Greg Rutkowski 等
-
收尾工作 - 例如 artstation、unreal engine 等上的趋势。 https://beta.dreamstudio.ai/prompt-guide
-
您还可以要求 AI 帮助完善您的提示。
下面是微软为优化提示而构建的模型
https://huggingface.co/spaces/microsoft/Promptist
4:使用预训练模型生成图像的示例代码
4.1
百度搜索GoogleColab,进去后登陆账号,注册一个notebook就可以,然后点击连接到GPU

4.2
依次导入需要的库
!pip install diffusers
!pip install setuptools-rust
!pip install transformers
from diffusers import StableDiffusionPipeline
#setup pipeline to pretrained model 下载预训练模型
pipe = StableDiffusionPipeline.from_pretrained("IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1").to("cuda")
# 测试
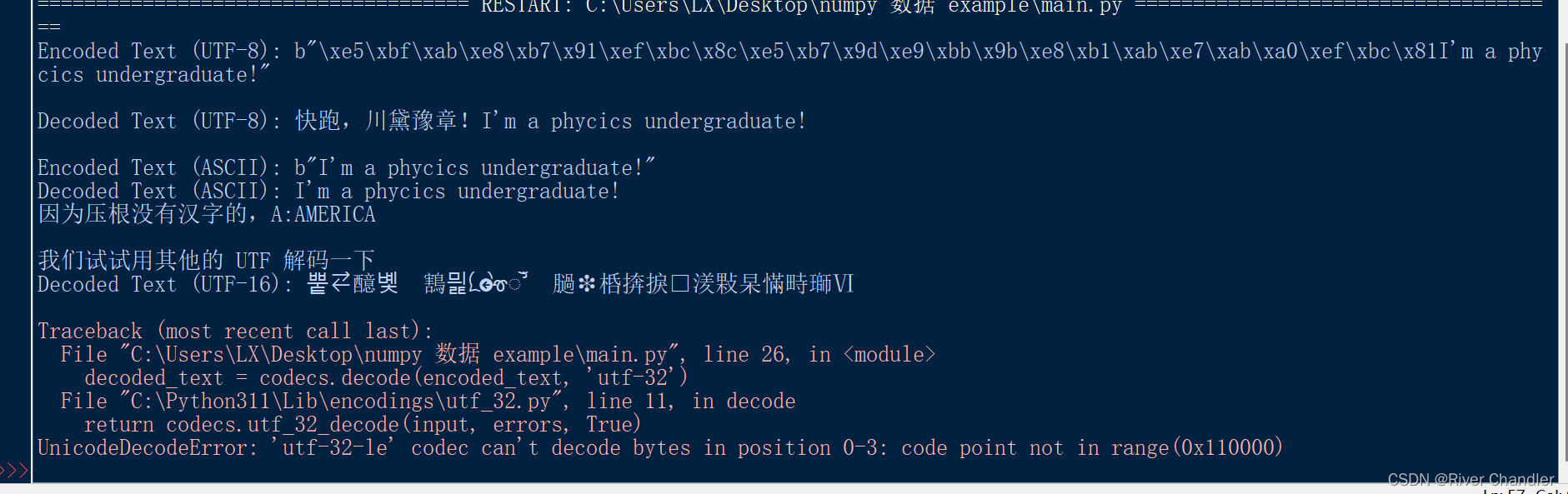
prompt = '远上寒山石径斜,白云深处有人家。'
image = pipe(prompt, guidance_scale=7.5).images[0]
image.save("白云深处.png")

prompt = '罨畫清溪上, 蓑笠扁舟一隻, 油畫'
image = pipe(prompt, guidance_scale=7.5).images[0]
image.save("罨畫清溪上.png")