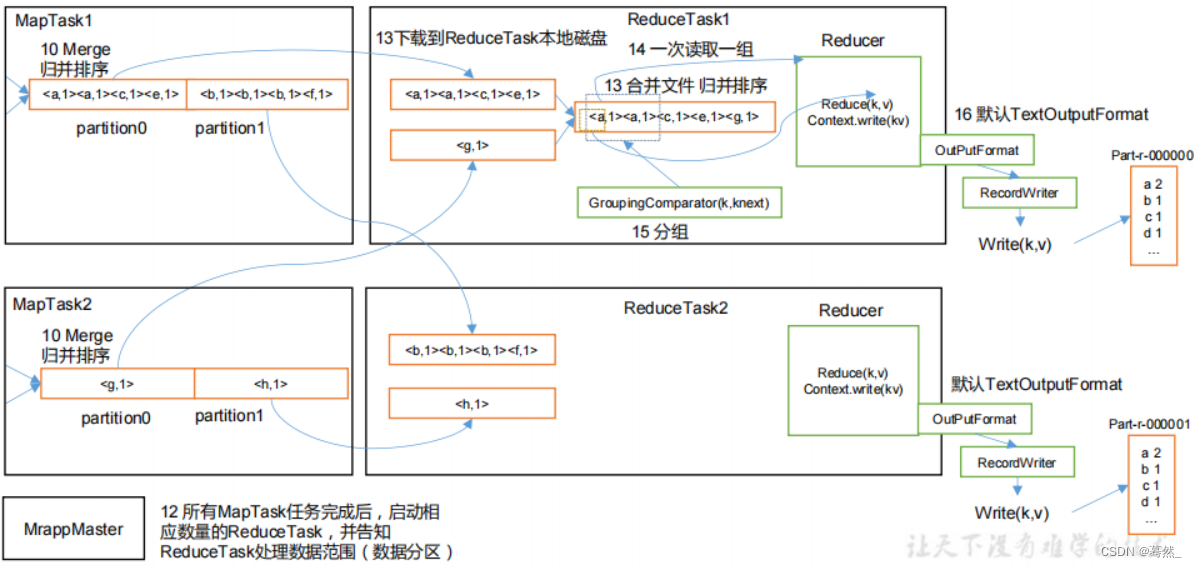
一,Auto-Encoder(AE)
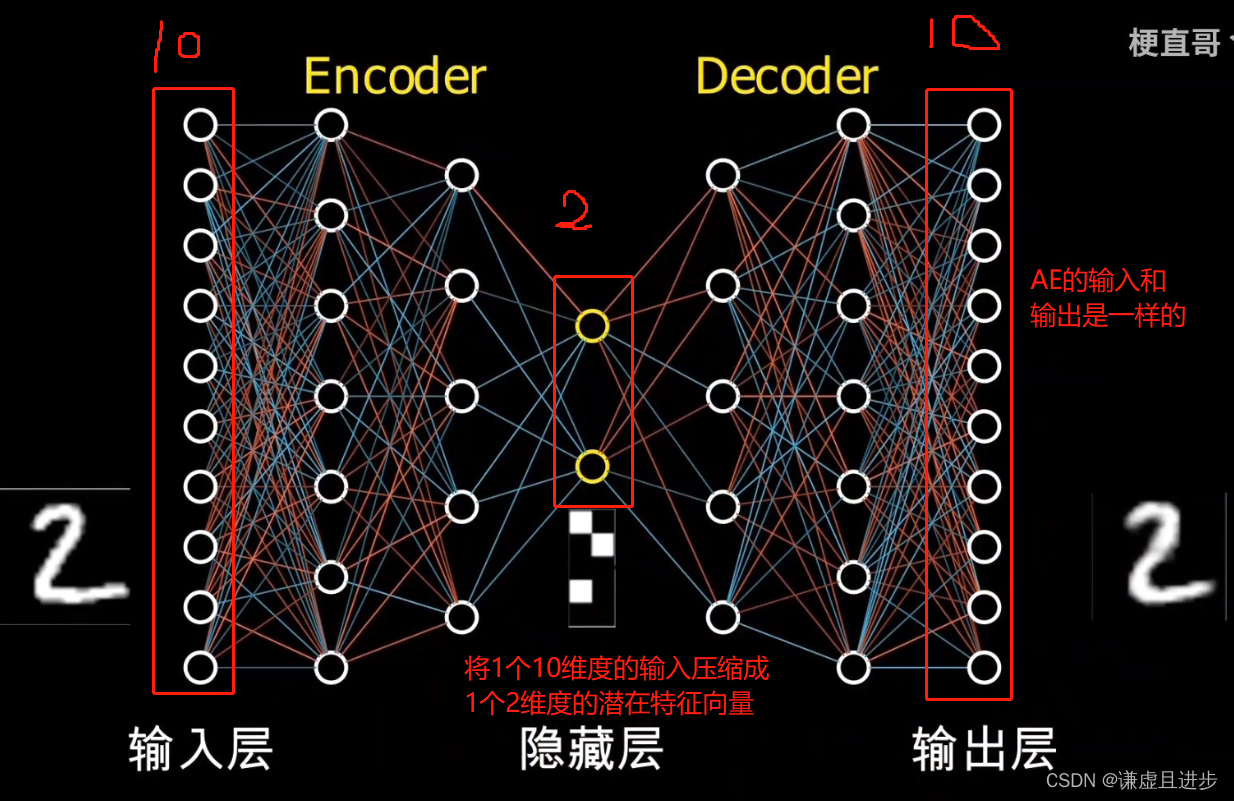
自编码器的目的是自己训练自己,他的输入和输出是一样的。比如28*28的黑白手写数字图片(单通道),如果使用矩阵形式进行表达,真正有作用的特征是哪些数值为1的地方,以及他们在矩阵空间的位置。而大部分边缘部分为0的地方对于特定任务来说都是冗余的特征。
如果不使用CNN进行特征提取,常用的方法就是把矩阵平摊为一个784维度的向量,然后将这个向量实例化为一个Tensor,作为神经网络的输入。而AE的目的就是将这个784维度的向量压缩为一个低维的向量,这个低维度向量需要能够代表原始输入的那个784维度的输入。
举个例子:手写数字图片为5的图片,平摊为784维度之后,通过AE进行降维,得到了一个20维度的向量,假设原始图片服从一个784维度的高斯分布,通过AE学习之后就变成了一个服从20维度的高斯分布。同样的,手写数字图片为6的图片也会被压缩成一个服从20维度的高斯分布。但是注意,图片5和图片6虽然都服从维度为20的高斯分布,但是他们的均值向量和方差向量肯定是存在显著差异的。
AE的代码如下:
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import mnist
from keras.models import Model
from keras.layers import Input, Dense
# 加载MNIST数据集
(x_train, _), (x_test, _) = mnist.load_data()
# 设置潜在特征维度
latent_size =64
# 数据预处理
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
# 定义输入层
input_img = Input(shape=(784,))
# 定义编码层
encoded = Dense(latent_size =64, activation='relu')(input_img)
# 定义解码层
decoded = Dense(784, activation='sigmoid')(encoded)
# 构建自编码器模型
autoencoder = Model(input_img, decoded)
# 编译模型
autoencoder.compile(optimizer='adam', loss='mse') #mse尽可能使每一个像素与原来的接近
# 训练自编码器
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
# 构建编码器模型
encoder = Model(input_img, encoded)
# 构建解码器模型
encoded_input = Input(shape=(latent_size =64,))
decoder_layer = autoencoder.layers[-1]
decoder = Model(encoded_input, decoder_layer(encoded_input))
# 对测试集进行编码和解码
encoded_imgs = encoder.predict(x_test)
decoded_imgs = decoder.predict(encoded_imgs)
# 可视化结果
n = 10 # 可视化的图片数量
plt.figure(figsize=(20, 4))
for i in range(n):
# 原始图片
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 重构图片
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
二,变分自编码器VAE
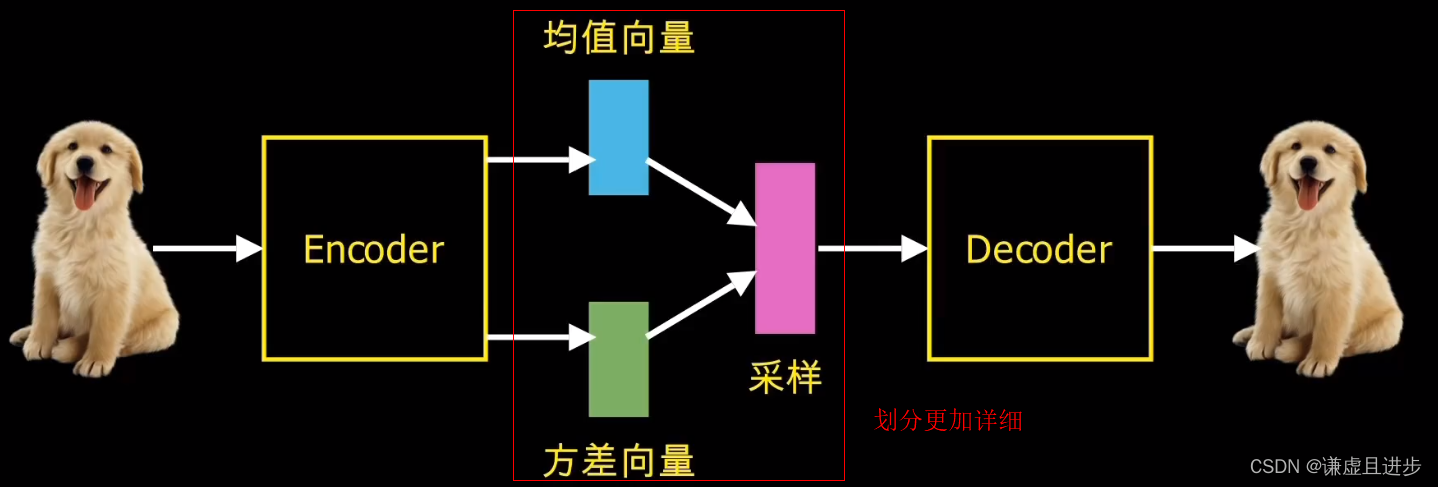
AE的目的就是将高维度的表示进行降维,实现用一个低维度的样本进行表示。而变分自编码器对AE进行了改进,其认为这个低维度的特征表示应该是服从一个多元正态分布。
举个例子:如果潜在特征维度是一个10维度的向量,那么这个向量应该是服从一个10元正态高斯分布的,那么就会存在一个10维度的均值向量和一个10维度的标准差向量。VAE的做法就是训练出这两个向量权重,然后使用重参数技巧进行采样,采样得到重构样本,然后计算损失函数。实际上VAE和AE一模一样,只不过VAE把压缩过程进行了更详细的划分。AE把均值学习、方差学习、采样部分合并在一起进行了自动操作,而VAE进行了更详细的划分。
因此,VAE实际上是学习了一个分布函数,也就是条件概率转移函数,因为神经网络能够拟合出任意的非线性函数,而梯度下降又是一个完美的解决方法。
此外,由于VAE考虑到了分布的限制,因此他的损失函数有两部分:1,与AE一样的基于重构的误差,可以是MAE、MSE等;2,基于分布相似度的损失,即KL散度,最大化潜在特征多元高斯分布与N元标准正态分布的相似度,有点类似于PINN(基于物理信息的神经网络),目的是减少反向传播时搜索的解空间,使训练过程收敛更快。

VAE的难点是数学上准确的定量刻画两个分布之间的相似度以及从潜在特征向量进行采样时的可微性,即从离散采样变成连续表达的过程,且这个过程保持着相同的效果。可以这么认为,假如一个班级的身体平均值为170cm,我们采样时就以170cm为中心,以5*N(0,1)进行采样,得到的值就是165——175之间,而这个采样过程可以用N(170,0)+5*N(0,1)的正态分布进行代替。
总结VAE的思想就是:我们需要从观测值(也就是样本)去近似求得样本的分布函数P(x),遗憾的是这是很难实现的,但是我们可以把这个工作交给神经网络去实现。根据GMM高斯混合模型,一个复杂分布可以通过任意个标准正态叠加得到。那么我们就假设潜在特征向量code就是服从一个标准正态分布的,通过code重构出原始图片,我们可以利用decoder不断叠加正态分布,从而后验近似出原始数据的分布。这个decoder拟合出来的非线性函数就是原始数据的分布。
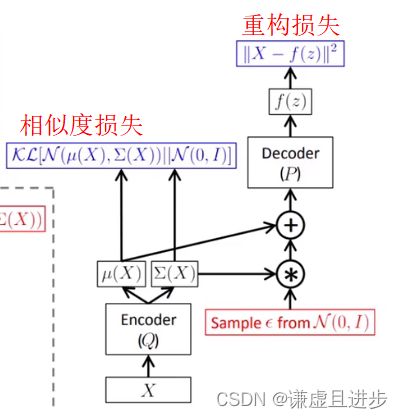
上图中,u(x)、E(x)都是由神经网络进行代替的。VAE的代码如下。
# %%
import os
import tensorflow as tf
import numpy as np
import keras
from keras.layers import Dense,Input,concatenate,Lambda,add
from matplotlib import pyplot as plt
from keras.datasets import mnist
import keras.backend as K
# %%
# 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
# %%
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
# %%
h_dim = 20
batchsz = 512
lr = 1e-3
z_dim = 10
# %%
class VAE(keras.Model):
# 变分自编码器
def __init__(self):
super(VAE, self).__init__()
# Encoder网络
self.fc1 = Dense(128)
self.fc2 = Dense(z_dim) # get mean prediction
self.fc3 = Dense(z_dim)
# Decoder网络
self.fc4 = Dense(128)
self.fc5 = Dense(784)
def encoder(self, x):
# 获得编码器的均值和方差
h = tf.nn.relu(self.fc1(x))
# 获得均值向量
mu = self.fc2(h)
# 获得方差的log向量
log_var = self.fc3(h)
return mu, log_var
def decoder(self, z):
# 根据隐藏变量z生成图片数据
out = tf.nn.relu(self.fc4(z))
out = self.fc5(out)
# 返回图片数据,784向量
return out
def reparameterize(self, mu, log_var):
# reparameterize技巧,从正态分布采样epsilon
eps = tf.random.normal(log_var.shape)
# 计算标准差
std = tf.exp(log_var*0.5)
# reparameterize技巧
z = mu + std * eps
return z
def call(self, inputs, training=None):
# 前向计算
# 编码器[b, 784] => [b, z_dim], [b, z_dim]
mu, log_var = self.encoder(inputs)
# 采样reparameterization trick
z = self.reparameterize(mu, log_var)
# 通过解码器生成
x_hat = self.decoder(z)
# 返回生成样本,及其均值与方差
return x_hat, mu, log_var
# 创建网络对象
model = VAE()
# %%
model.build(input_shape=(4, 784))
# 优化器
optimizer = tf.optimizers.Adam(lr)
# %%
for epoch in range(10): # 训练100个Epoch
for step, x in enumerate(x_train): # 遍历训练集
# 打平,[b, 28, 28] => [b, 784]
x = tf.reshape(x, [-1, 784])
# 构建梯度记录器
with tf.GradientTape() as tape:
# 前向计算
x_rec_logits, mu, log_var = model(x)
# 重建损失值计算
rec_loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=x, logits=x_rec_logits)
rec_loss = tf.reduce_sum(rec_loss) / x.shape[0]
kl_div = -0.5 * (log_var + 1 - mu**2 - tf.exp(log_var))
kl_div = tf.reduce_sum(kl_div) / x.shape[0]
# 合并误差项
loss = rec_loss + 1. * kl_div
# 自动求导
grads = tape.gradient(loss, model.trainable_variables)
# 自动更新
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 100 == 0:
# 打印训练误差
print(epoch, step, 'kl div:', float(kl_div), 'rec loss:', float(rec_loss))
# %%
# evaluation
# 测试生成效果,从正态分布随机采样z
z = tf.random.normal((batchsz, z_dim))
logits = model.decoder(z) # 仅通过解码器生成图片
x_hat = tf.sigmoid(logits) # 转换为像素范围
x_hat = tf.reshape(x_hat, [-1, 28, 28]).numpy() *255.
x_hat = x_hat.astype(np.uint8)
参考:耿直哥,深度学习之自编码器(5)VAE图片生成实战_vae图像生成_炎武丶航的博客-CSDN博客