- Numpy 数据文件
Numpy 数据处理函数
loadtxt
- np.loadtxt()函数常用的传入参数
- dtype:所需的返回数组的数据类型。默认为float
- comments:用于标识注释行的字符。默认为'#'
- delimiter:指定分隔符字符或字符串。默认为任何空格字符
- skiprows:指定要跳过的行数。默认为0,即不跳过任何行
- usecols:指定要加载的列索引或范围。默认为None,表示加载所有列
- encoding:指定文件的编码方式。默认为None,表示使用系统默认编码
savetxt
- np.savetxt()函数常用的传入参数
- fname:要保存的文件名或文件路径
- fmt:格式化字符串,用于指定保存数据的格式
- delimiter:指定分隔符字符或字符串。默认为空格
- newline:行结束符。默认为系统默认行结束符
- header:要写入文件开头的字符串。默认为空字符串
- footer:要写入文件末尾的字符串。默认为空字符串
- comments:注释字符或字符串,用于在每行开头添加注释。默认为'#'
- encoding:指定文件的编码方式。默认使用系统默认编码
example1
data.txt
1,2,3,4
2,3,4,5
5,6,7,8
6,7,8,9
main.py
import numpy as np
data = np.loadtxt("data.txt", delimiter=",")
print("raw data:")
print(data)
new_data = np.array([[7, 8, 9]])
np.savetxt("data.txt", new_data, delimiter=",", fmt="%d")
result


example2
data.txt
7,8,9,23,4123,5
0)data denote sentence
2,3,21,231,2,5
7,8,9,0,6,2
123,221,312,332,443,63
231,4,237,78,87,6
main.py
import numpy as np
data = np.loadtxt('data.txt', delimiter=',', \
dtype=int, skiprows=1, \
comments="0)",usecols=(0, 1))
print(data)
result
[[ 2 3]
[ 7 8]
[123 221]
[231 4]]
>>> data[0][0]
2
>>> data[0][1]
3
example3
main.py
import numpy as np
data = np.loadtxt('data.txt', delimiter=',', \
dtype=int, skiprows=1, \
comments="0)",usecols=(0, 1))
data
#Array Data
1,2,3
4,5,6
#End of File
文件编码格式
几种常见的文件编码格式
- ASCII码(American Standard Code for Information Interchange)
- ASCII码是最早的字符编码标准,它使用8位二进制数表示256个字符
- Unicode
- Unicode是一种用于表示世界上所有字符的编码标准。Unicode为每个字符分配了一个唯一的二进制编码。
- Unicode编码使用不同的方案来存储字符如UTF-8、UTF-16和UTF-32
- UTF-8(Unicode Transformation Format-8)
- UTF-8 是一种变长字符编码方案,它可以使用1到4个字节来表示Unicode字符。UTF-8编码在表示ASCII字符时与ASCII码兼容
- UTF-16(Unicode Transformation Format-16)
- UTF-16 是一种固定长度字符编码方案,它使用2个或4个字节来表示Unicode字符
- UTF-16 编码主要用于表示表情符号和某些罕见字符
- UTF-32(Unicode Transformation Format-32)
- UTF-32 是一种固定长度字符编码方案,它使用4个字节来表示Unicode字符
chardet
- 根据文件内容推断出最可能的编码方式
import chardet
with open('data.txt', 'rb') as f:
content = f.read()
result = chardet.detect(content)
print(result)
encoding = result['encoding']
confidence = result['confidence']
decoded_content = content.decode(encoding)
print(decoded_content)
{'encoding': 'ascii', 'confidence': 1.0, 'language': ''}
#Array Data
1,2,3
4,5,6
#End of File
codecs
- 指定所需的输入和输出编码方式
import codecs
text = "快跑,川黛豫章!I'm a phycics undergraduate!"
encoded_text = codecs.encode(text, 'utf-8')
print("Encoded Text (UTF-8):", encoded_text)
print()
decoded_text = codecs.decode(encoded_text, 'utf-8')
print("Decoded Text (UTF-8):", decoded_text)
print()
encoded_text_ascii = codecs.encode(text, 'ascii', "ignore")
print("Encoded Text (ASCII):", encoded_text_ascii)
decoded_text_ascii = codecs.decode(encoded_text_ascii, 'ascii', "ignore")
print("Decoded Text (ASCII):", decoded_text_ascii)
print("因为压根没有汉字的,A:AMERICA")
print()
print("我们试试用其他的 UTF 解码一下")
decoded_text = codecs.decode(encoded_text, 'utf-16')
print("Decoded Text (UTF-16):", decoded_text)
print()
decoded_text = codecs.decode(encoded_text, 'utf-32')
print("Decoded Text (UTF-32):", decoded_text)
print()
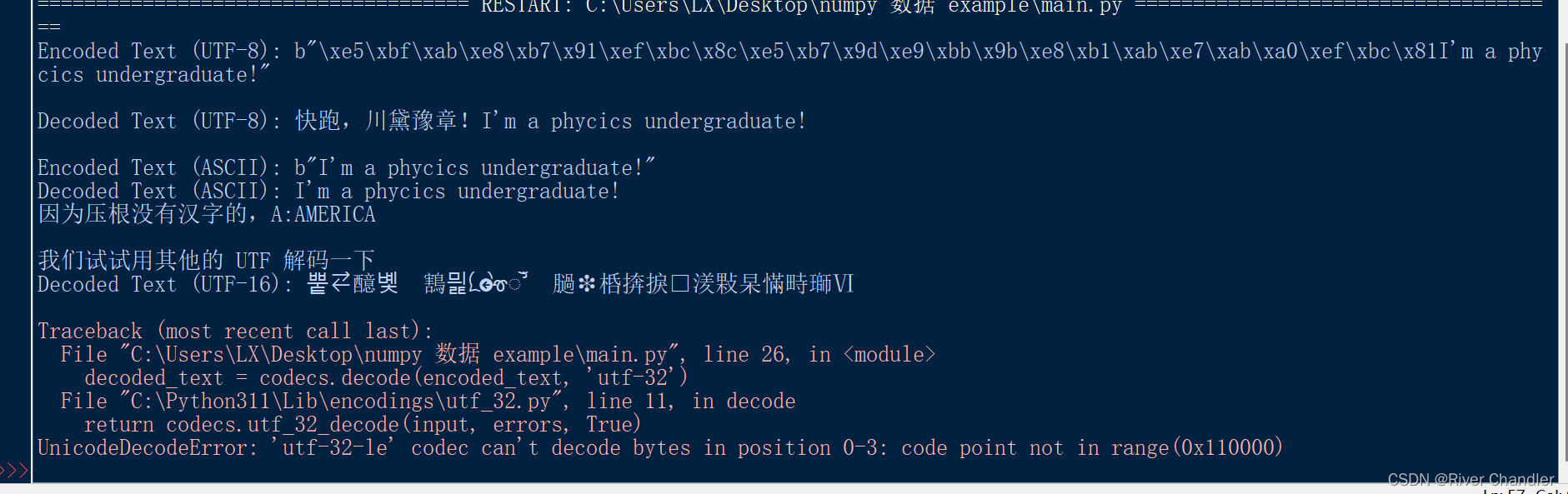
Encoded Text (UTF-8): b"\xe5\xbf\xab\xe8\xb7\x91\xef\xbc\x8c\xe5\xb7\x9d\xe9\xbb\x9b\xe8\xb1\xab\xe7\xab\xa0\xef\xbc\x81I'm a phycics undergraduate!"
Decoded Text (UTF-8): 快跑,川黛豫章!I'm a phycics undergraduate!
Encoded Text (ASCII): b"I'm a phycics undergraduate!"
Decoded Text (ASCII): I'm a phycics undergraduate!
因为压根没有汉字的,A:AMERICA
我们试试用其他的 UTF 解码一下
Decoded Text (UTF-16): 뿥醷볯鶷믩ꮱꯧ膼❉桰捹捩湵敤杲慲畤瑡Ⅵ
Traceback (most recent call last):
File "C:\Users\LX\Desktop\numpy 数据 example\main.py", line 26, in <module>
decoded_text = codecs.decode(encoded_text, 'utf-32')
File "C:\Python311\Lib\encodings\utf_32.py", line 11, in decode
return codecs.utf_32_decode(input, errors, True)
UnicodeDecodeError: 'utf-32-le' codec can't decode bytes in position 0-3: code point not in range(0x110000)