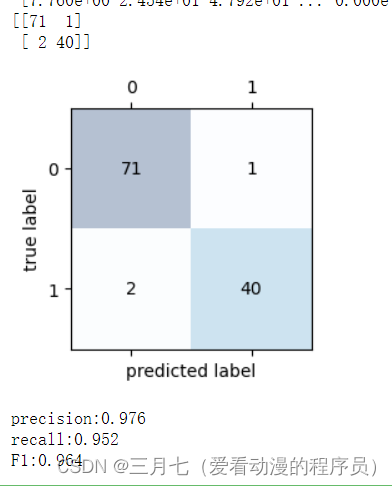
原文链接:https://arxiv.org/abs/2307.07362
一个医学多模态综述,本人搞分割的重点看了一下分割的,其余任务没时间细看我就截了个模型汇总图,想详细了解的去喵一下上面这个论文就行
数据集汇总
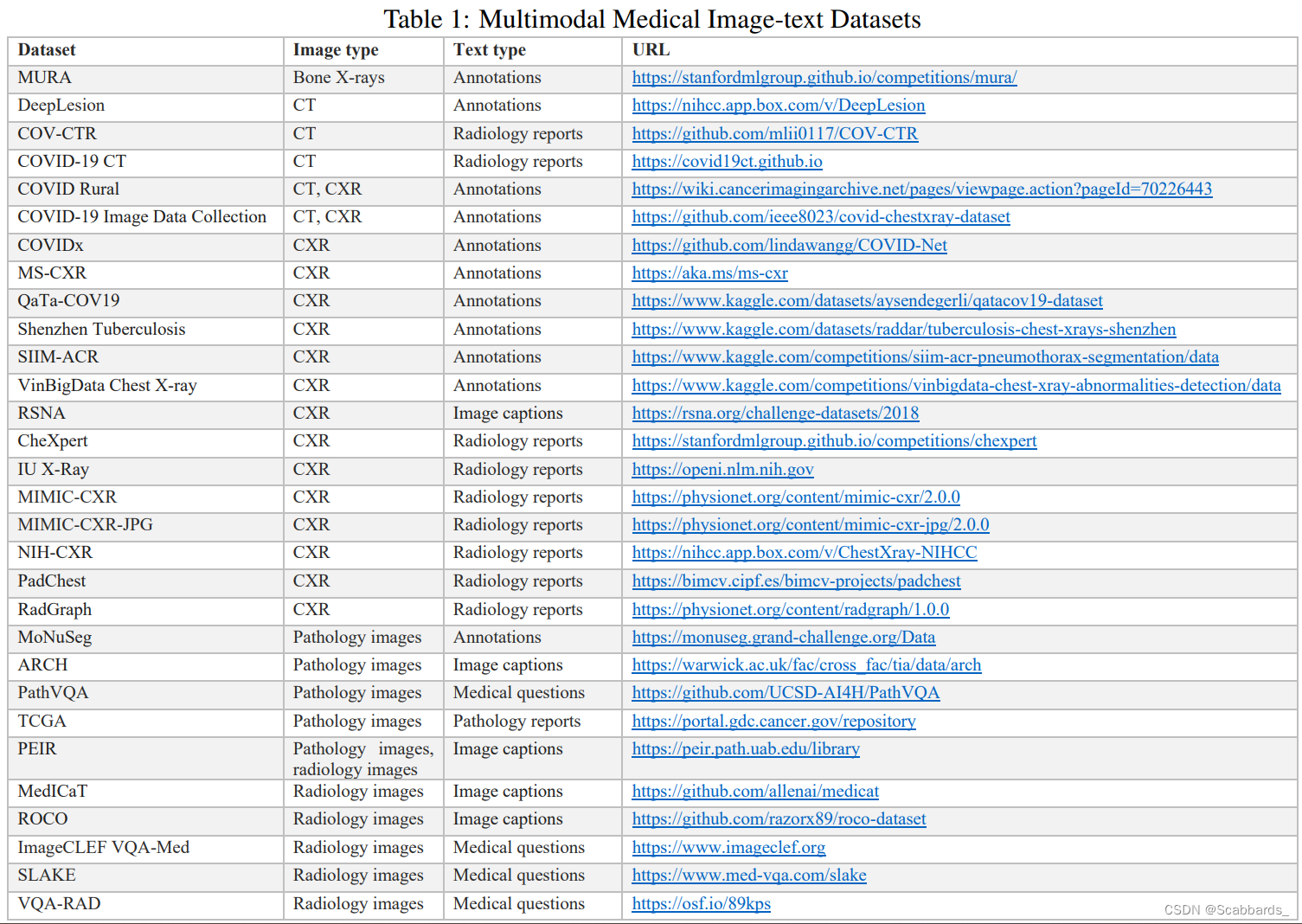
Report generation 报告生成
报告生成旨在从EHR和医学图像中自动生成描述。
它可以减轻临床医生的工作负担,提高报告本身的质量。由于报告生成的训练过程通常需要临床医生编写的医学图像和文本报告,因此可以自然地将其视为多模式学习过程。
1)a CNN encoder and hierarchical LSTM decoder
2)Transformer architecture
3)AlignTransformer
4)self-supervised learning techniques, such as CLIP
5)reward mechanisms 提高准确性
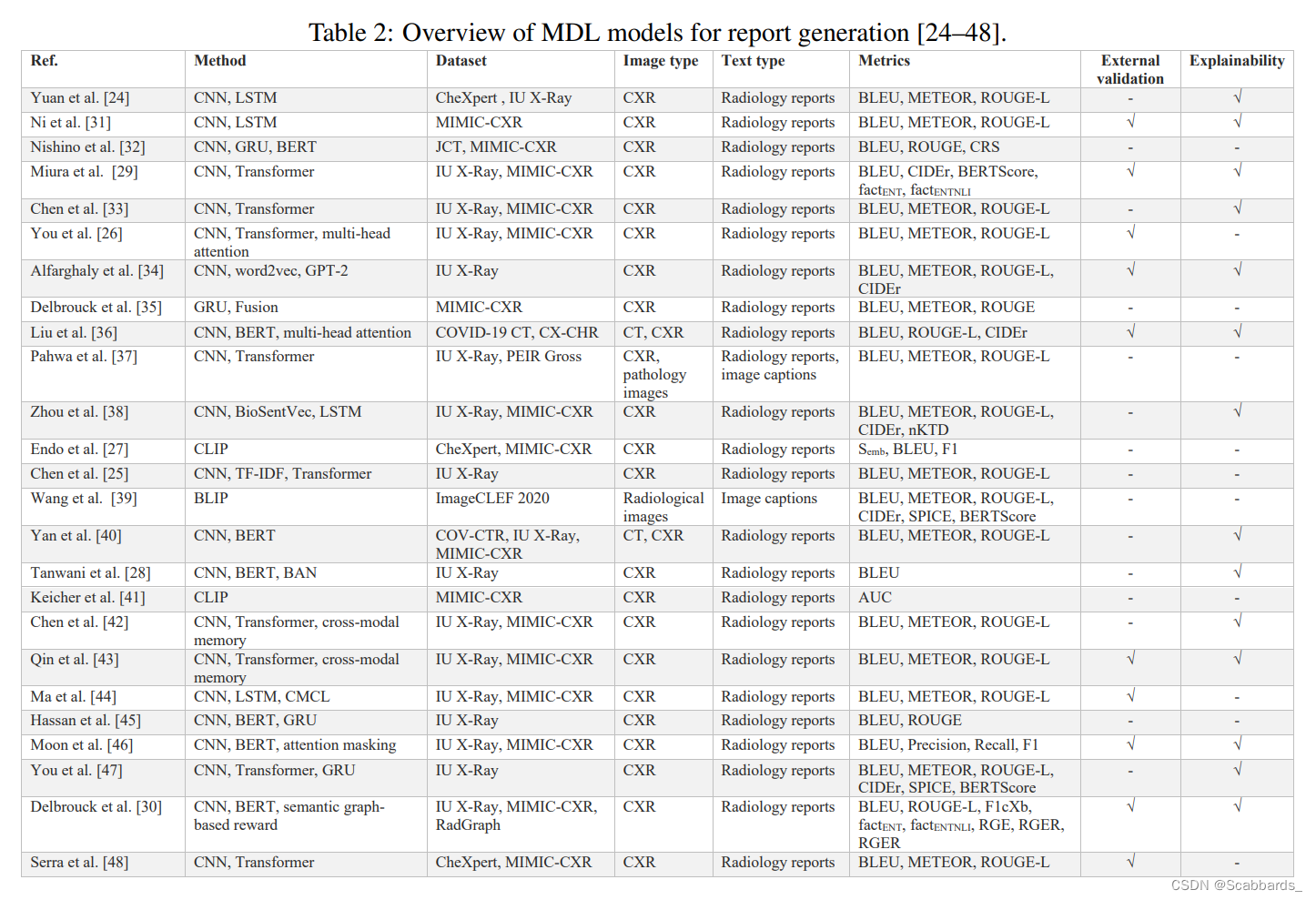
模型总结
判断标准
1. text quality 文本质量
指文本的可读性、准确性和有效性。
BLEU [19], METEOR [50], and ROUGE-L [51]
2. medical correctness 医学上的正确性
AUC, precision, recall, F1, RadCliQ
3. explainability 可解释性,可说明性
factENT, factENTNLI
Visual question answering 视觉问答
模型总结
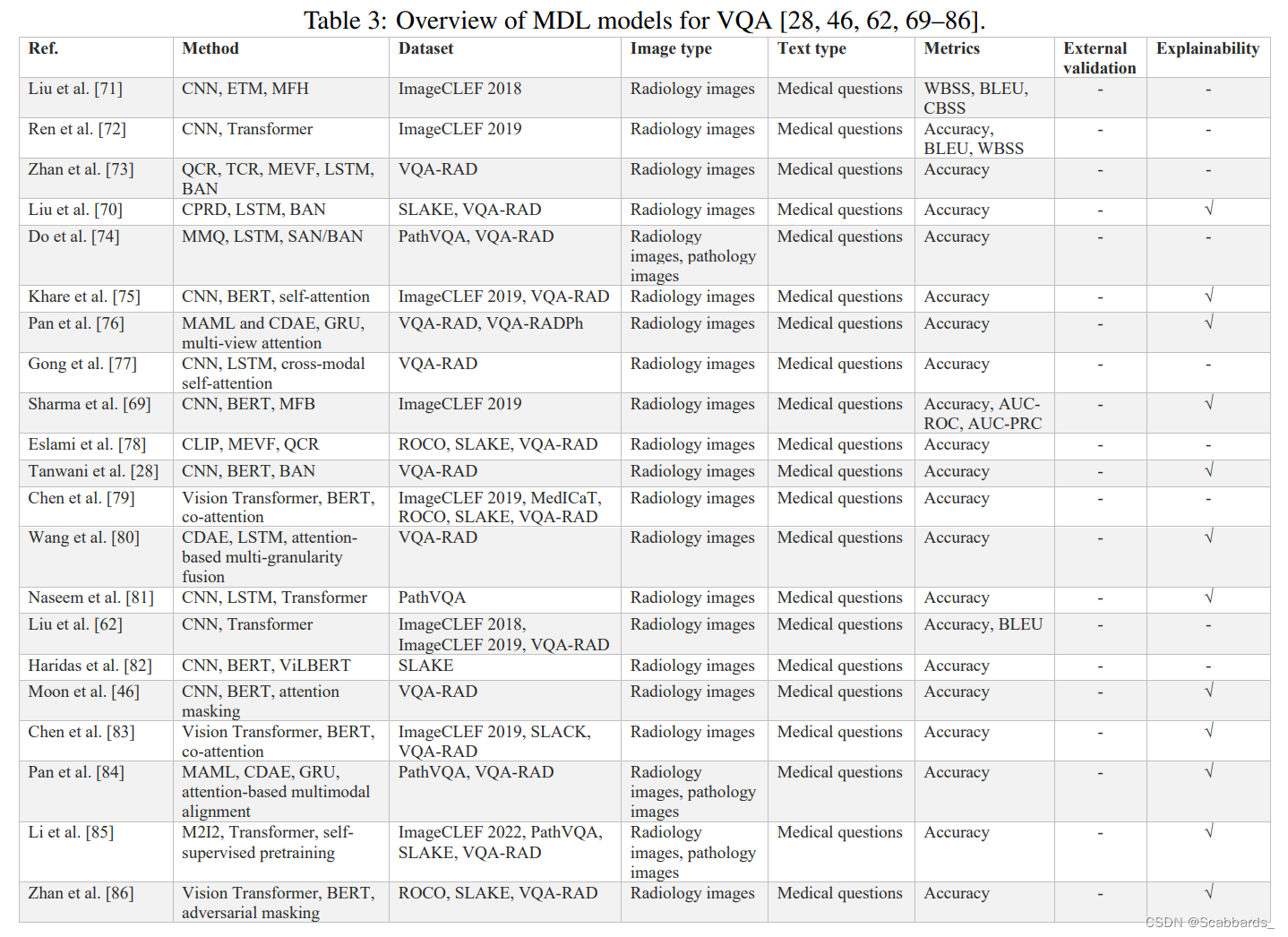
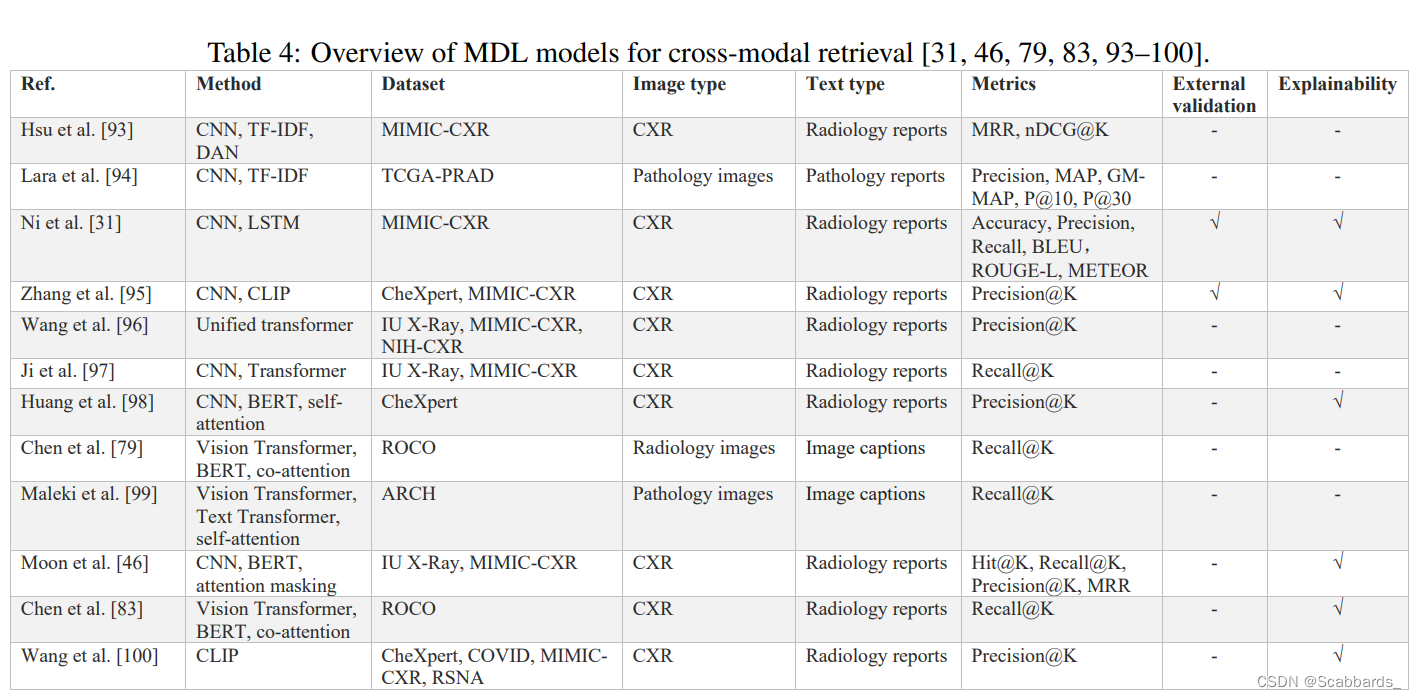
Cross-modal retrieval 跨模态信息检索
模型总结
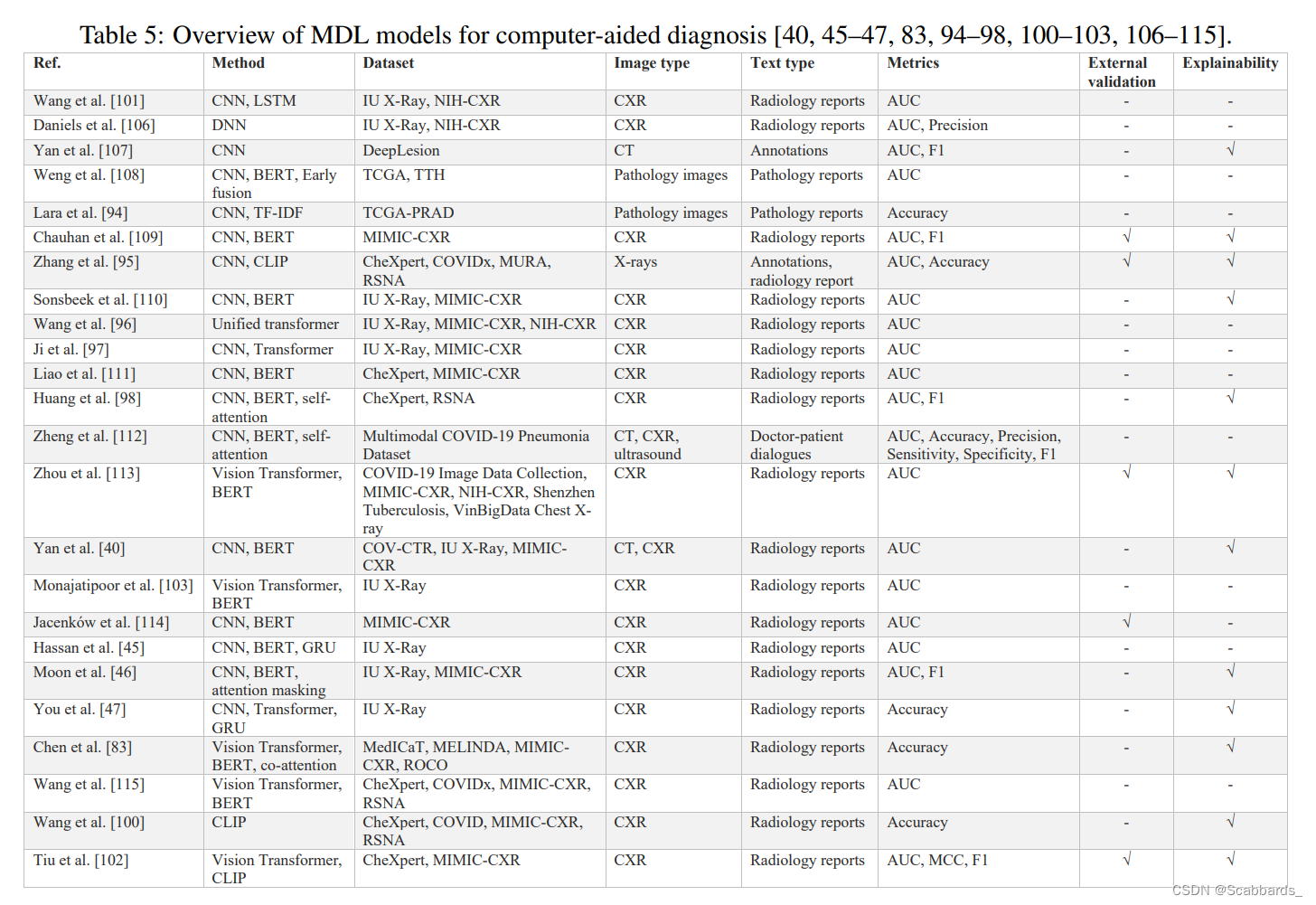
Diagnostic classification 诊断分型
模型总结
Semantic segmentation 语义分割
图像-文本对比学习的有效性,其中包括利用语义分割提取可以与文本特征并置的视觉特征,以促进对图像及其相应文本描述之间关系的理解(表6)。此外,使用语义分割技术评估对比学习中的局部对齐评估。
图像-文本对齐(Image-Text Alignment)和局部表示学习(Local Represntation Learning)是MDL中常用的语义分割方法,这些技术可以帮助提高模型的准确性,使其能够更好地理解图像中不同区域之间的空间关系以及视觉和文本信息之间的关系[119]
Li等[120]提出了LViT,利用医学文本标注来提高图像数据的质量,并指导伪标签的生成,从而获得更好的分割性能。Muller等人[121]设计了一种新颖的预训练方法LoVT,旨在专门解决局部医学成像任务。与常用的预训练技术相比,他们的方法在18个本地化任务中的10个上表现优异。
模型总结
数据集
SIIM
数据集包括12,047张胸片,以及相应的人工标注
RNSA
数据集包括用于评估的29,700张正面透视片肺炎的证据
MS-CXR
它由1153个带有注释边界框的图像句子对和相应的经过放射科医生验证的短语。这个数据集涵盖了八种不同的心肺放射学发现。
判断标准
1)Dice
2)Miou (mean intersection over union)
3)CNR (contrast-to-noise ratio)