🔥 DL里的优化器相关考点,面试时面试官偶尔会问甚至变态点的会叫代码手撕,笔试选择题只要跟DL相关基本必考。废话不多说,直接上!
😄 当然并不是纯为了面试,只不过说你如果是搞DL的连优化器都说不清楚,那真的有点丢人~
文章目录
- 0、先验知识
- 1、SGD
- 2、Momentum
- 2、AdaGrad
- 3、RMSprop
- 4、Adam
- 5、AdamW
这里有动画大家可以直观感受下各优化器带来的快感~: https://imgur.com/a/Hqolp

0、先验知识
- 说白了,优化器其实就是个数学公式,用于更新模型的权重。常见的如梯度下降算法,能够让模型朝着使损失函数下降最快的方向 (梯度的负方向) 去更新权重。具体我在此链接用泰勒展开做了证明:
梯度下降算法可能降低损失函数值的原因?(一维简单解释)

1、SGD
梯度下降算法:
- SGD:随机梯度下降。每次随机基于单个样本计算梯度来更新权重。【迭代次数过多,收敛慢,容易陷入局部最优】
- BGD:批量梯度下降。对所有样本计算梯度提取然后取平均来跟新权重。【全局最优,迭代耗时】
- MBGD:小批量梯度下降。每次随机对小批样本计算梯度提取然后取平均来跟新权重。【最常用,前面两者的权衡】
2、Momentum
- 思想很简单,基于上一步的梯度和当前梯度进行加权得到当前新的梯度(即滑动平均),以此新的梯度更新权重。


- beta参数可调,经验值为0.9,这就意味着下降方向主要是此前累积的下降方向,并略微偏向当前时刻的下降方向。在梯度方向改变时,momentum能够降低参数更新速度,从而减少震荡,在梯度方向相同时,momentum可以加速参数更新, 从而加速收敛!【😄减少噪声干扰更新方向!一定程度上缓解局部最优的可能】
2、AdaGrad
-
思想也很简单,对学习率进行约束。这是因为随着更新次数的增大,我们希望学习率越来越慢。因为我们认为在学习率的最初阶段,我们距离损失函数最优解还很远,随着更新次数的增加,越来越接近最优解,所以学习率也随之变慢。


-
该方法引入了二阶动量,我们知道一阶动量决定了梯度的方向,二阶动量反映了梯度的大小和变化趋势。这里二阶动量是是迄今为止所有梯度值的平方和。
-
从下面公式可知,梯度一直累加,并用于缩减学习率。
-
有个缺点就是:若中后期,分母上梯度累加的平方和会过大,使得学习率为0,导致训练提前结束,无法学习。
3、RMSprop
- 基于Adagrad做改进,又是一个骚操作(学Momentum的滑动平均):将AdaGrad的梯度平方和改为梯度平方和加权移动平均。另外地,对滑动平均的结果取期望。
- beta作为decay rate衰减率,默认为0.9。
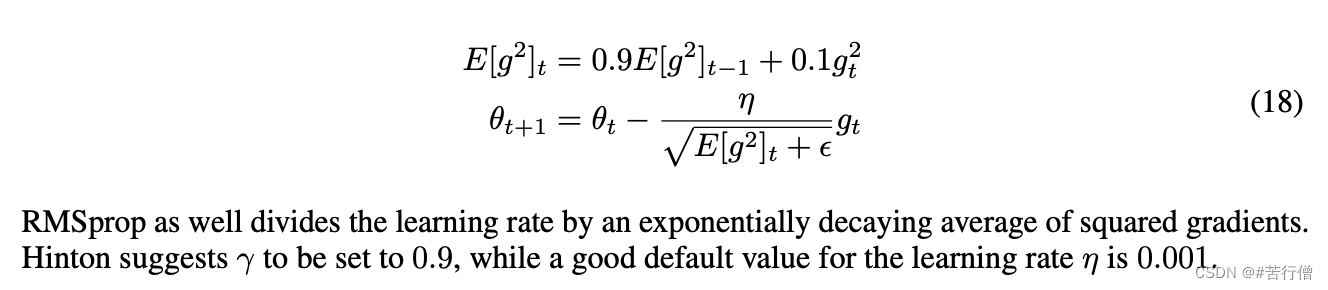
4、Adam
👍 这再熟悉不过了吧~刚玩DL的时候基本都有事没事用Adam。优点:自适应地调整每个参数的学习率,从而提高模型的收敛速度和泛化能力。
- 又是骚操作,对AdaGrad的优化,一种通过计算模型参数的梯度以及梯度平方的加权平均值(一阶动量和二阶动量),来调整模型的参数。【可以看到,这一路来都是结合别人的整合改进】
- 一二阶动量如下:


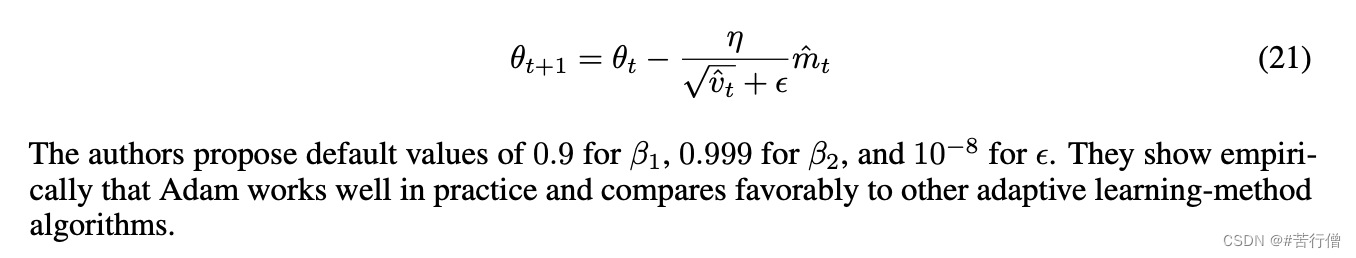
那为何需要对一二阶动量纠正呢?因为上述方法求出来的一二阶动量的期望是有偏的。所以为了更准确地估计梯度的方向和大小,从而提高Adam优化器的性能和收敛速度。Adam通过如下方式进行偏置差校正后的一二阶矩估计:
- Adam优点:结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点。它可以根据训练过程中每个参数的历史梯度和更新情况来自适应地调整每个参数的学习率,从而加速神经网络的训练。
5、AdamW
🐮 AdamW基本是现在的预训练模型、大模型的标配了。
😄 AdamW是在Adam+L2正则化的基础上进行改进的算法。AdamW = Adam + weight decay
-
因为Adam存在的权重过拟合问题并没有很好解决。一般做法是在loss上加l2正则来缓解过拟合,但在Adam公式中,如果本身比较大的一些权重对应的梯度也会比较大,由于Adam计算步骤中减去项会除以梯度平方的累积开根号,使得减去项偏小。按常理说,越大的权重应该惩罚越大,但是在Adam并不是这样。分子分母隐式地相互抵消掉了。
-
AdamW引入权重衰减对所有的权重都采用相同的系数进行更新,越大的权重显然惩罚越大。

-
Adam+L2 与 AdamW
图片中粉色是传统的Adam+L2 regularization的方式(这一项实际上就是权重乘以L2项的导数,因为x2 的导数就是本身x。而不要粉色,要绿色那就是Adam + weight decay的方式。

Reference
[1]《An overview of gradient descent optimization algorithms∗》
[2] 理解AdamW+代码
[3] 大梳理!深度学习优化算法:从 SGD 到 AdamW 原理和代码解读

![#P1009. [NOIP2016提高组] 玩具小人](https://kedaoi.cn/p/1009/file/4o5I-aguA_OhsPMLmAwmM.png)