视觉分割大模型的过去、现在和未来!SAM最新综述来了!今天自动驾驶之心很荣幸邀请到Garfield来分享视觉SAM分割大模型的最新综述,如果您有相关工作需要分享,https://mp.weixin.qq.com/s/-_QFvxBGzFpAgVGF-t-XRgSegment Anything Model (SAM)发布了一个多月,有哪些应用呢?请看综述(一) - 知乎1. 简介:一个多月以前,Meta发布了Segment Anything Model (SAM) 当时我还测试了一下,大家需要了解的话可以看一下: 北方的郎:Meta Segment Anything 测试效果到现在,一个多月过去了,SAM都有哪些应用呢? 答…
![]() https://zhuanlan.zhihu.com/p/6313887361.introduction
https://zhuanlan.zhihu.com/p/6313887361.introduction
1.1 将视觉transformer扩展到极大规模。
1.2 大量工作致力于添加附加模态的知识,例如clip和align。
1.3 模型的一个共同的特征是依靠在广泛数据集上预训练的基础模型,使用可以解决各种下游的提示学习,从而具备了强大的零样本泛化能力。
2.背景
图像分割、交互分割和基础模型。
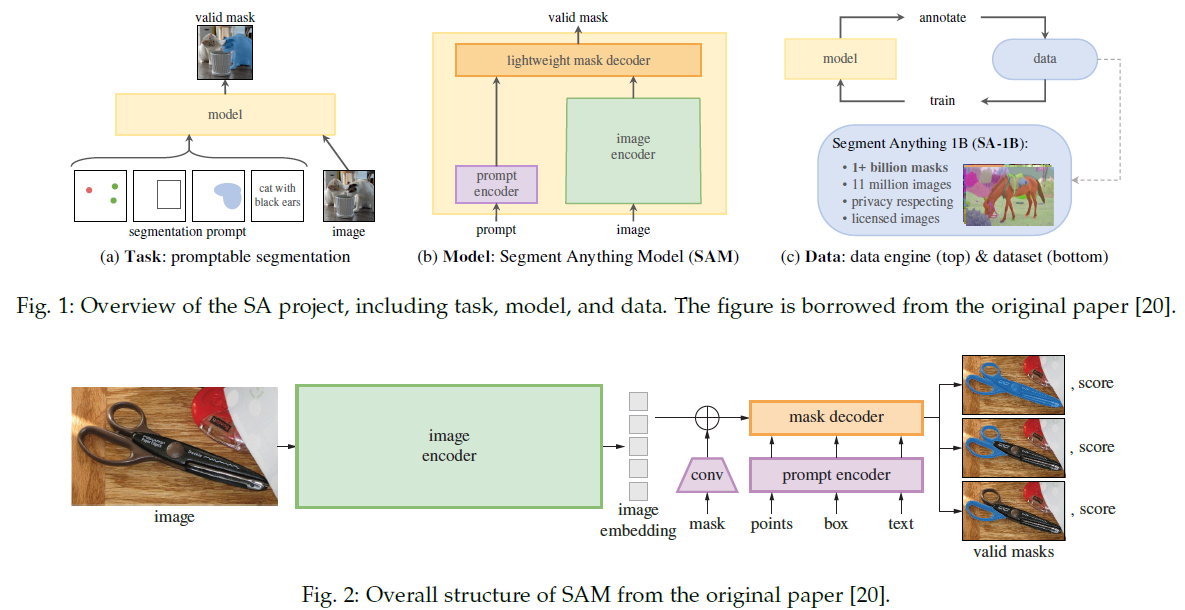
sam:任务、模型和数据。提出了一个包括可提示分割任务(分割目标的point,box,mask和文本)、可以接受多个提示输入并实现交互使用的sam和使用交互式训练注释循环过程的数据引擎形成的数据集SA-1B。sam结构包括,图像编码,prompt编码,mask解码,其中图像编码采用MAE,prompt编码分为稀疏输入(使用clip的文本编码器作为位置编码器来处理点、框和文本形式的提示)和密集输入(使用卷积处理mask输入),mask解码使用prompt-image双向transformer解码器。使用dice loss和focal loss,数据获取包括辅助手动阶段,半自动化阶段和全自动化阶段。
3.方法
3.1 software scenes
Image Editing:图像编辑
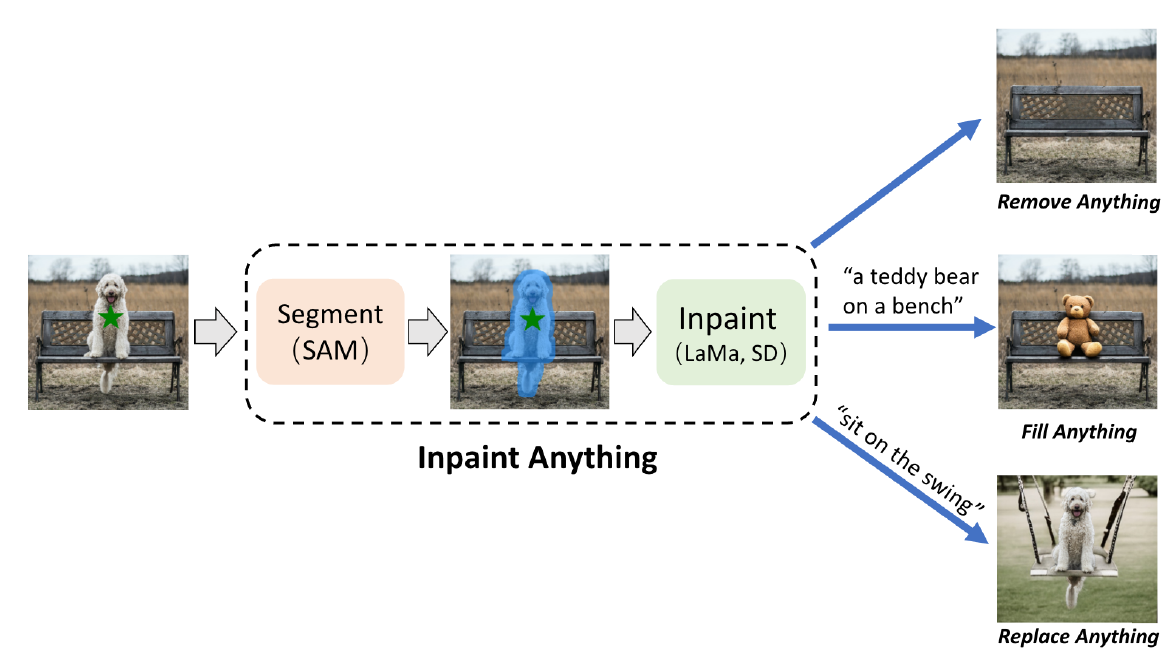
Inpaint anything,用户点击操作用作sam中提示,生成对象区域的mask,然后lama使用腐蚀和膨胀操作操作进行填充,使用sd通过文本提示生成新的对象来替换和填充。
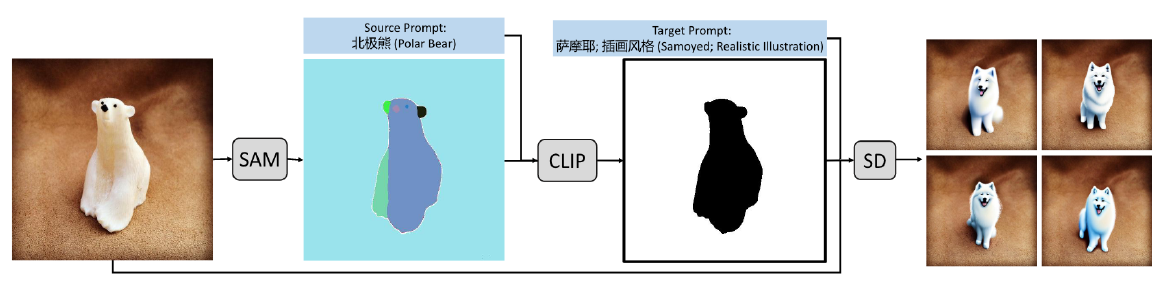
Edit everything,在输入图像时,sam首先将其分割成几个段落而无需提示,然后使用源提示指导clip对收到的段落进行排序,只选择得分最高的座位目标,使用sd来生成,在中文场景下重新训练了4亿参数的clip和10亿参数的sd。

style transfer:固定区域的风格迁移
sam在自然图像场景中有出色的泛化能力,但在低对比度场景中显示出较少的结果,并且在复杂场景中需要先验知识。
3.2 real-world scenes
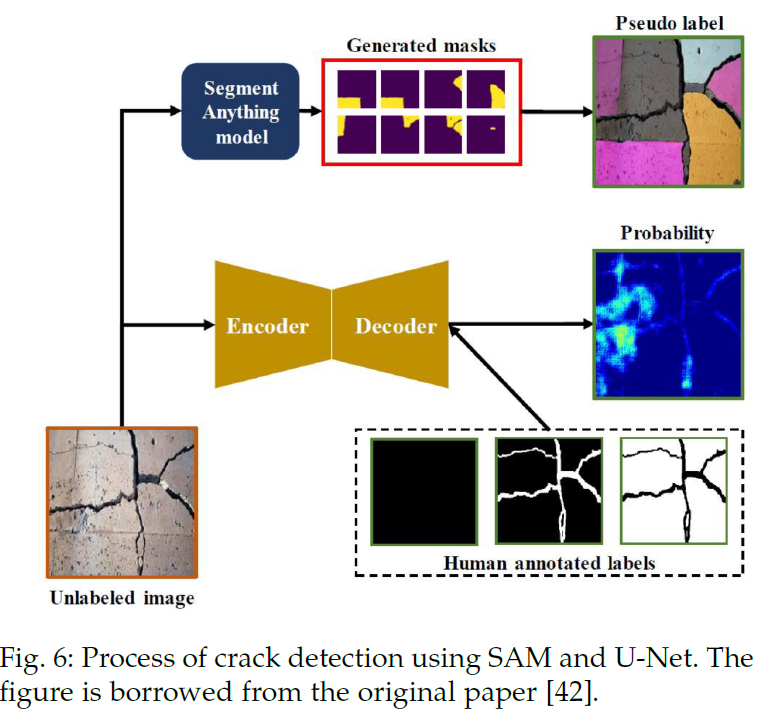
Detection:
Counting:使用sam进行图像分割,然后将分割出的每个目标物体作为计算对象,另一种是使用sam生成目标物体的特征向量,然后使用这些特征向量来计算相似度,从而确定数量。
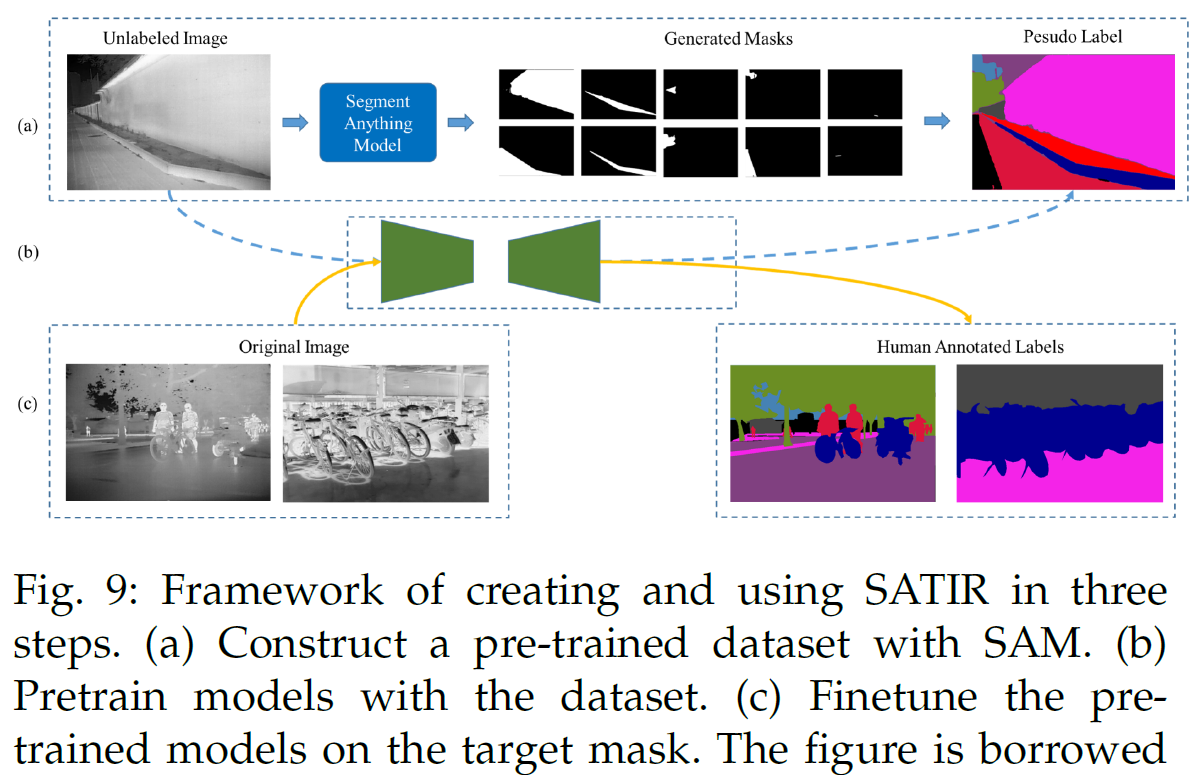
Moving object:tracking anything
3.3 complex scenes

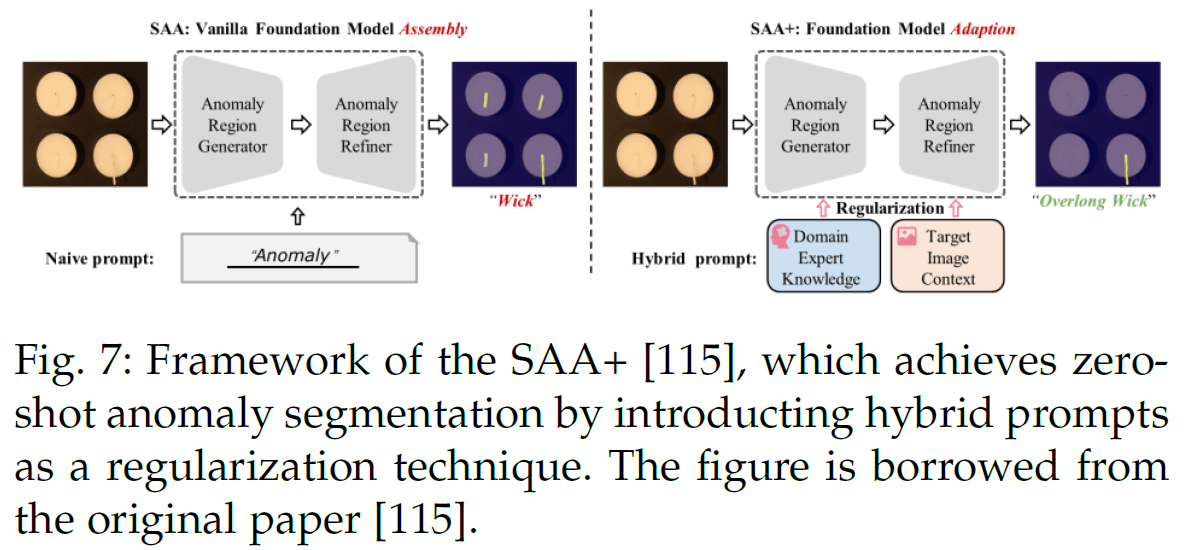
低对比度场景:伪装目标分割、工业缺陷、医学病变
热红外成像:
鸟瞰:
4.vision related application
4.1.1 medical image
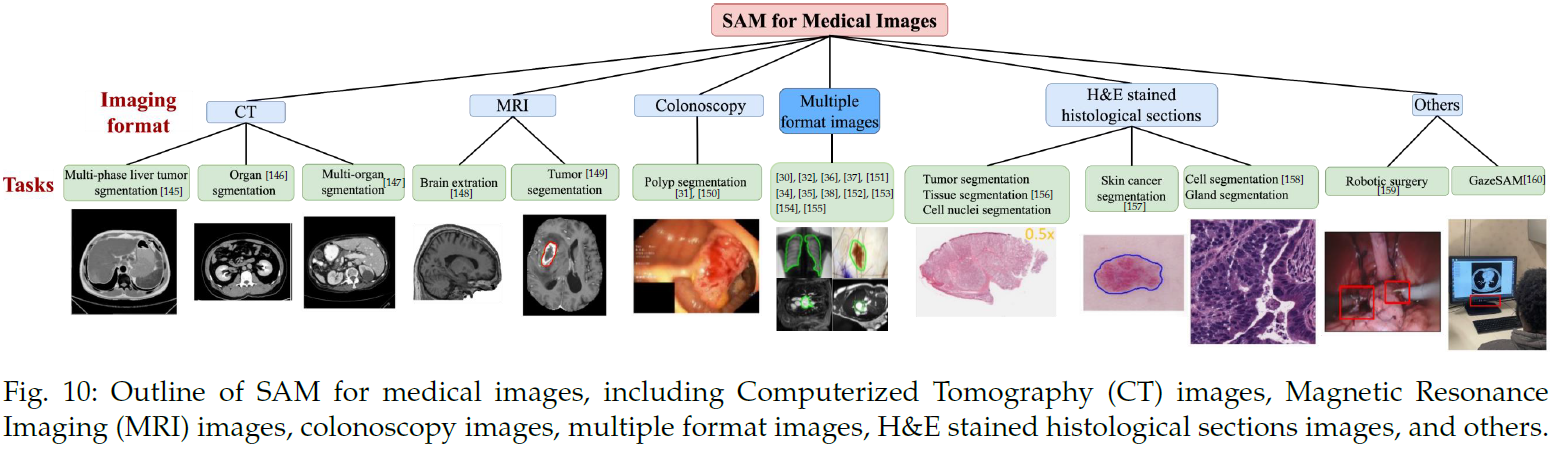
医学图像:计算机断层扫描(CT)图像、磁共振成像(MRI)图像、结肠镜图像、H&E染色组织切片图像、多种格式图像和其他图像。
4.1.2 video
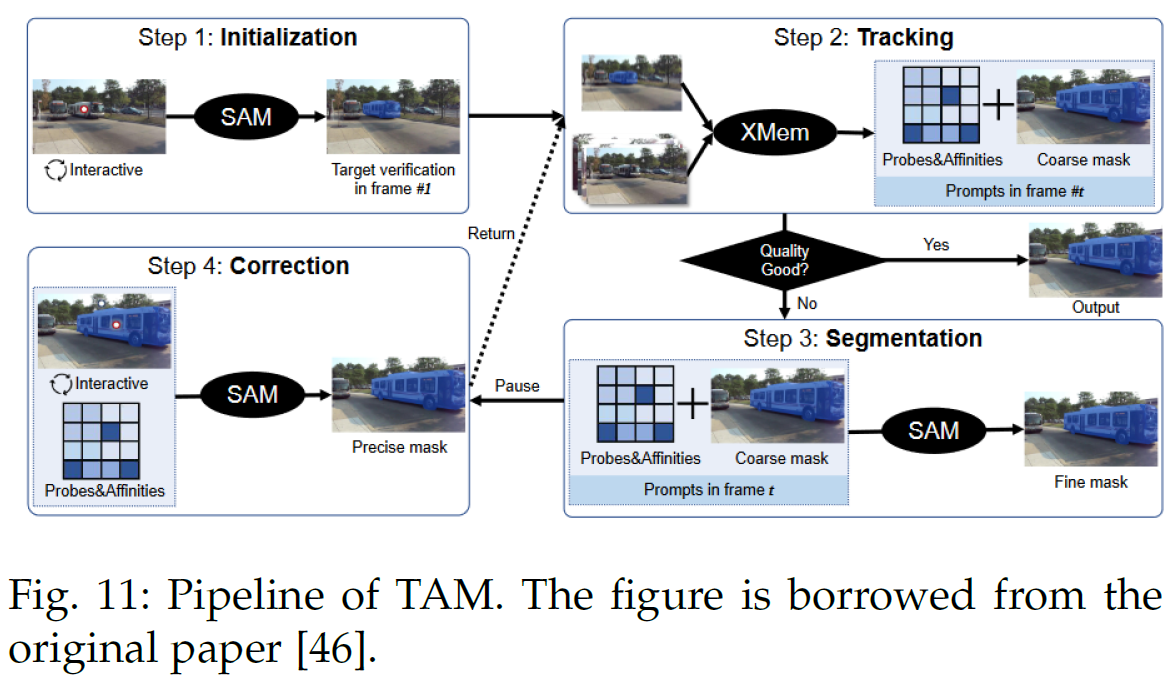
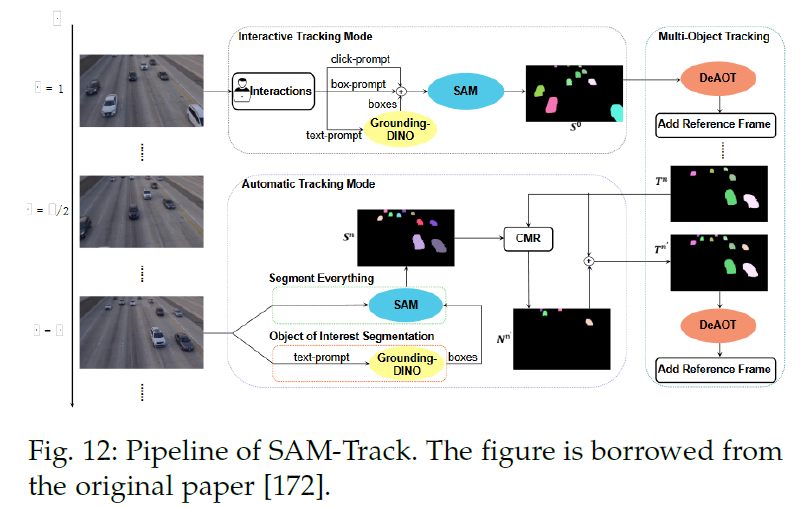
Track anything,sam-track
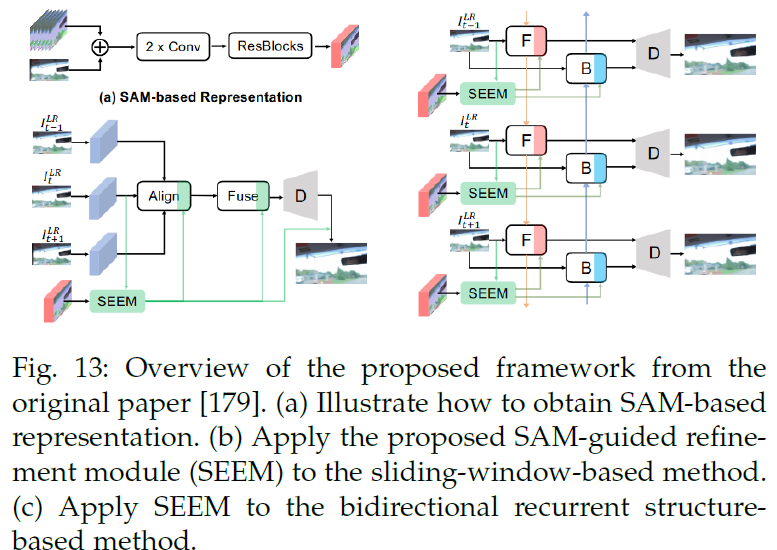
seem,VSR
4.1.3 data annotations
4.2 beyond vision
4.2.1 3D reconstruction
4.2.4 视频文字定位
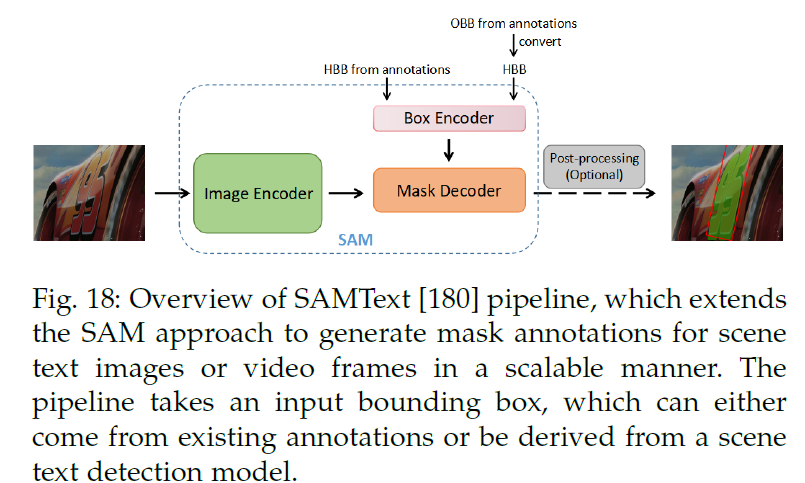
传统的视频文字定位依赖于检测边框和边界框内识别文本实例,在具有不规则形状或者方向的文本实例存在局限性。SamText,给定一个输入的场景文本图像或视频帧,SamText首先从现有注释中提取边界框坐标或从场景文本检测中生成,如果框是带方向的,SamText将计算它们最小包围矩形亿获取水平边界框,然后将其作为SAM的输入提取,以获取mask,sam模型是一个分割模型,预先在自然图像上进行预训练,并在coco-text上进行微调,已生成文本实例的mask,获取mask之后进行后处理以确保其连通性。
4.2.5 vision and language
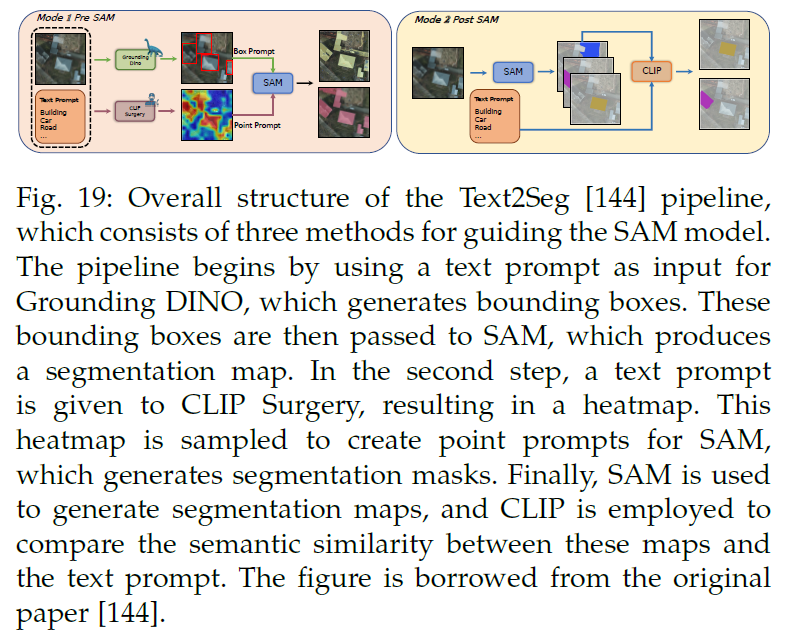

CAT:caption anything fraamework,可控制的图像描述方法,采用sam模型作为分割器,并通过视觉提示与用户交互,实现对图像描述的多模态控制,包括三个组件,分割器、描述器和文本优化器,分割器使用sam生成图像中感兴趣的区域,描述器生成初始图像描述,文本优化器通过用户定义的语言控制来优化描述图像。
4.2.6 audio and vision
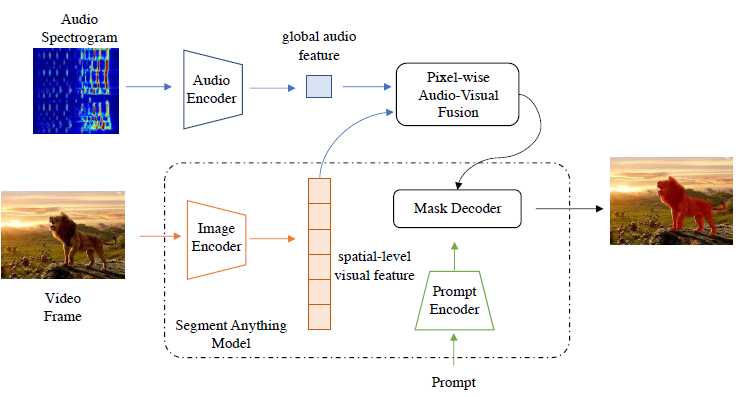
4.2.7 多模态可视化和开放词汇交互式分割