序言
腾讯大数据处理套件(Tencent Big Data Suite,TBDS)是基于腾讯多年海量数据处理经验,对外提供的可靠、安全、易用的大数据处理平台。您可以借助 TBDS 在公有云、私有云、非云化环境,根据不同数据处理需求选择合适的大数据分析引擎和相应的实时数据开发、离线数据开发以及算法开发服务,来构建您的数据仓库、用户画像、精准推荐、风险管控等大数据应用服务。cuiyaonan2000@163.com
根据不同数据处理需求选择合适的大数据存算分析组件包括 Hive、Spark、HBase、Flink、presto、Iceberg、Alluxio 等,以快速构建企业级数据湖、数据仓库。
参考资料:
- 大数据处理套件_大数据处理工具_大数据处理平台 -腾讯云
相关词汇
Ranger
一种开源的安全管理框架,用于管理大数据平台中的访问控制和安全策略。Ranger支持对多种大数据平台进行访问控制和安全管理,并提供了一个集中式的管理界面,可以简化访问控制和安全管理的过程,同时支持审计和报告功能,以便于监控系统安全和合规性。
数据仓库
一个面向企业的数据存储系统,用于支持企业的决策和分析。
数据地图
业务数据可视化展示,可共享、协作数据资产。
数据分析
提供简单的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce/Spark 任务运行,进行在线 Scala、Python、SQL 脚本调试。
数据湖
一个存储海量原始数据的存储系统,可以存储结构化、半结构化和非结构化的数据。
数据血缘
数据产生的链路或者路径,例如通过数据 A 数据 B 产生了数据 C,那么 C 的父血缘就是 A 和 B,反之亦然。在大数据套件中描述数据“父子”关系,以思维导图形式展现了数据变化影响和数据生产溯源,清晰刻画表与表之间、任务与任务之间的关系。
在a) 统一元数据平台(Unified MetaData Platform,UDP)中,是指由 SQL 语句构成的数据来源与去向的关系表达,指数据在产生、处理、流转到消亡过程中,数据之间形成的一种类似于人类社会血缘关系的关系。----数据血缘在针对不同的角色,有着不同的血缘展现形式,总来的来说就是数据从哪里来,到哪里去cuiyaonan2000@163.com
数据质量
提供内置规则和自定义规则,对数据质量进行检测,通过数据质量全息图对数据质量健康度进行实时监控,进而实现数据质量缺陷定位、追溯提供决策支撑。
特性
技术开放(重)
存储标准兼容开源 Hadoop 标准,使历史构建在 hadoop 上的大数据平台可以平滑迁移。支持多驱动接入、完美兼容社区标准;支持 Sql2003 标准的内存迭代运算引擎 SparkSQL。
简单易用(重)
支持一键式部署,只需选择适合的服务即可快速完成部署。支持数据接入、处理、存储、分析、机器学习的拖拽式全链路大数据开发和开箱即用的数据治理工具集,数据开发者只需专注于业务开发。
安全可靠
数据节点分布式部署,可选多份备份。所有系统控制节点主从热备,故障秒级切换,腾讯95%业务考验,可用性99.999%。支持数据加密传输、存储。全平台单点登录,统一策略管控中心。
性能卓越
高性能数据接入引擎,内部业务日接入五万亿条数据。性能全面超越社区方案,数据处理能力提升30%左右。支持上千维度、千亿规模数据的秒级交互式多维分析。
场景丰富
在金融、政务、零售、传统企业等领域积累了丰富的业务应用案例,特别是在 PB 级离线、近线、实时数仓企业级用户画像、金融实时风控、精准推荐、物联网大数据等场景都有成熟的解决方案。
生态完善
深度与各行业优秀的大数据开发、数据治理服务及应用商合作,为政务、金融等行业客户提供基础软件平台+应用+服务在内的专业一体化大数据解决方案。
应用场景
数据仓库创建
大数据处理套件完整覆盖数据抽取、转换、加载、建模、分析、报表呈现、数据治理等数仓建设环节,用户可借助大数据套件在公有云、私有云、非云化环境快速建设 TB 到 PB 级的企业数据仓库和数据集市,搭建专属的大数据应用。使用 TBDS,用户可显著降低基于企业数据仓库的数据应用开发周期、开发成本,还可降低数据仓库、数据处理、数据应用的运维成本。
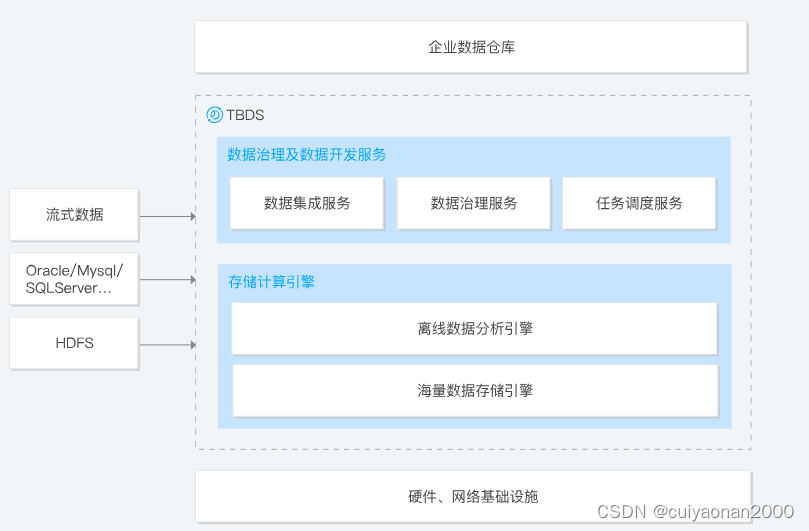
实时流式数据处理
用户可基于 TBDS 快速开发本行业在实时流式场景下的大数据处理、分析的应用程序,以实现对企业实时业务的风险监控与告警,以占据大数据时代的优势地位。流式数据处理可用于金融行业的风险管控、物联网的海量传感器数据处理、工业生产线的实时故障预警、病人特征数据实时分析、实时交通流量分析、互联网实时流量分析等应用场景。
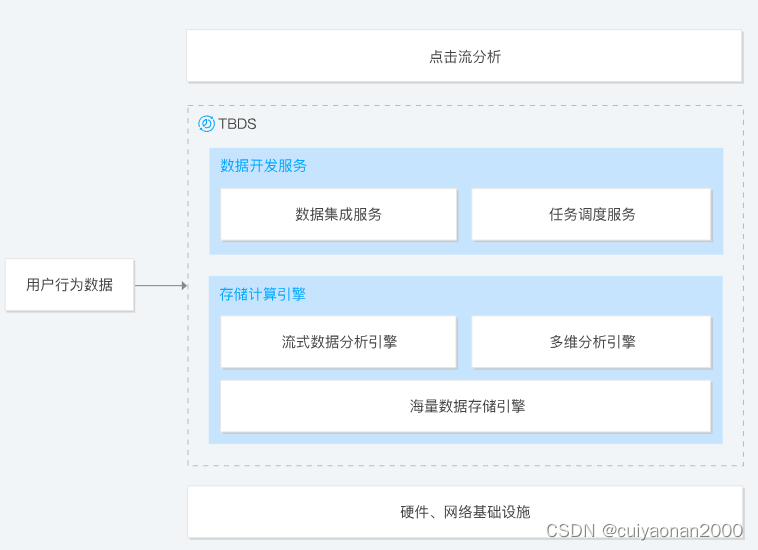
数据探索挖掘(流式处理+数据仓库)
通过腾讯大数据处理套件所提供的强大数据分析与探索挖掘能力,用户可快速对企业在 PB 级规模下的大数据进行可视化的数据分析探索,在纷繁复杂的商业数据中快速获取数据洞察力,占领商业先机。用户还可通过 TBDS 所提供的强大机器学习能力对企业数据进行深度挖掘,进一步发掘海量数据中蕴藏的无限价值。
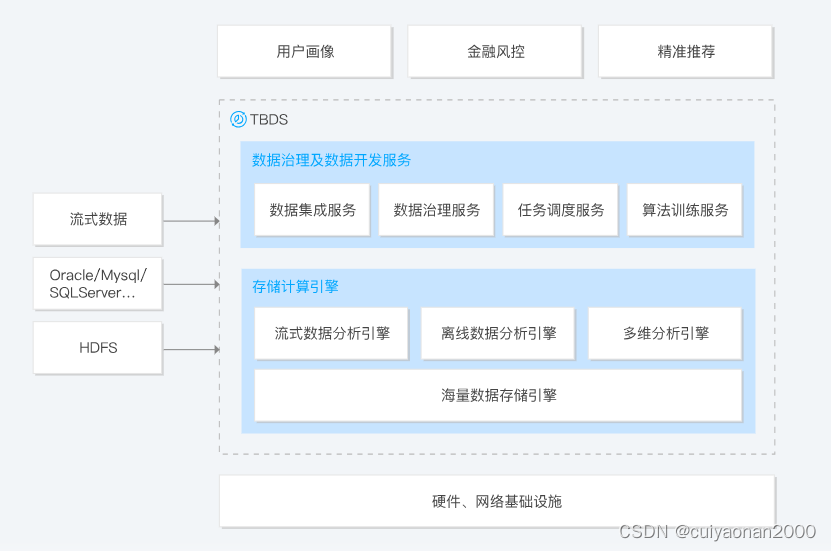
主要功能
大数据引擎底座
提供开源稳定、卓越性能、按需灵活搭配的 HDFS、Hive、HBase、Spark、Presto、Flink 等全栈大数据引擎,深度优化组件性能、稳定性、兼容性、场景化能力,满足内外部用户私有化大数据场景的项目交付。
云原生大数据平台
支持存算分离架构,计算引擎容器化,支持跨集群统一资源调度,实现资源无感弹性伸缩、灵活配比、混合部署、按需使用,降低综合资源成本;支持 GB ~ 100PB 不同规模的离线和流式数据的接入、存储、计算分析、查询应用服务,助力企业级云原生大数据平台的构建。
国产化安全可信
全面适配国产化主流芯片、操作系统,支持单集群异构混部;完善的4A 安全体系满足安全合规性要求,多租户数据隔离,支持 Kerberos 身份认证,支持基于 Ranger 对本地及 COS 数据细粒度权限管控。
一站式运维管控
包含一键式集群部署、增量部署、升级/替换迁移、可观测运维、全链路诊断、智能巡检、自动参数调优、自动评测等高阶功能,完善的面向多租户的计算资源管控体系和用户权限管理体系,提供企业级的大数据平台运维管理能力支撑。
多场景容灾管理
提供数据备份恢复策略和数据全生命周期管理;支持多集群多地域容灾、容灾一键切换、容灾演练、集群全类型数据可视化对比、可视化检测和预警、校验规则模板等功能,满足不同场景下集群灾备需求。
工具链产品融合
TBDS 可深度融合 WeData 一站式数据开发治理平台、机器学习 TI 平台、BI 报表应用工具等产品能力,快速支撑 BI、AI 类数据应用场景,助力用户发现大数据价值。