本文参考Langchain中ChatGoogleGenerativeAI的官方文档,在本地的jupyter notebook中运行。
关于API的细节在官方文档最开头给出:
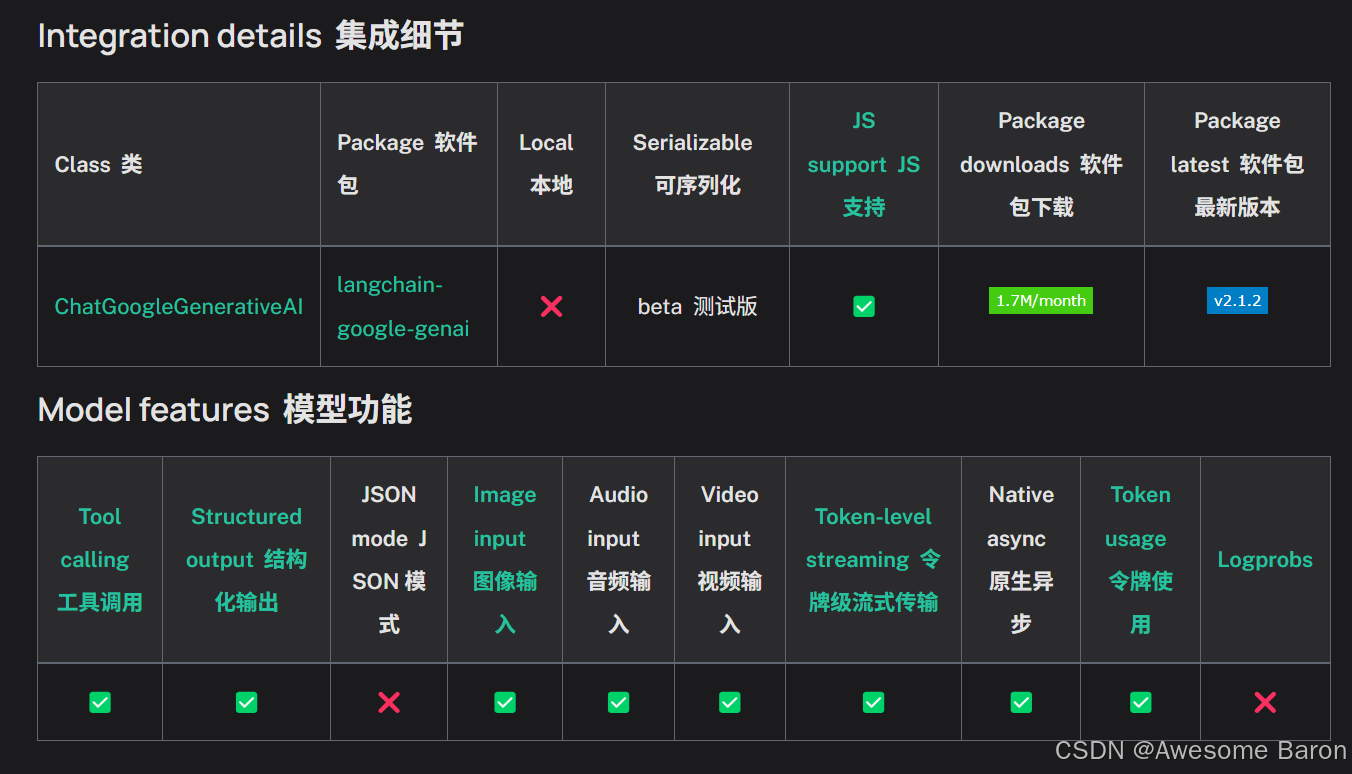
我们在使用时,可以选择model="gemini-2.0-flash-001"或者生成图片的ChatGoogleGenerativeAI(model=“models/gemini-2.0-flash-exp-image-generation”)
测试本地环境
查看jupyter的kernel是不是我们选择的虚拟环境:
import sys
sys.executable
查看库的配置是否包含Langchain和 ipykernel
!where python
!python --version
!pip list
如果没有下载langchain-google-genai,运行以下命令:
pip install -qU langchain-google-genai
输入你自己的API密钥
import getpass
import os
if "GOOGLE_API_KEY" not in os.environ:
os.environ["GOOGLE_API_KEY"] = getpass.getpass("Enter your Google AI API key: ")
Instantiation 实例化
测试连通性
import os
os.environ['HTTP_PROXY'] = 'http://127.0.0.1:7890'
os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'
import requests
r = requests.get("https://www.google.com")
print(r.status_code) # 能返回 200 就说明代理成功了
官方模板
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(
model="gemini-2.0-flash-001",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
# other params...
)
自测模板
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(
model="gemini-2.0-flash-001", # 或其他可用模型
# google_api_key="AIzaSyD9NMiYyxyqdHwvC2V0L54xovdEkoRXfP4"
)
print(llm.invoke("你好呀!你现在通了吗?").content)
如果测试成功,会打印下方语句:
你好!我已经通了。我是一个大型语言模型,由 Google 训练。很高兴为你服务!
Invocation 调用
messages = [
(
"system",
"You are a helpful assistant that translates English to Chinese. Translate the user sentence.",
),
("human", "I love programming."),
]
ai_msg = llm.invoke(messages)
ai_msg
模型输出
AIMessage(content='我喜欢编程。(Wǒ xǐhuan biānchéng.)', additional_kwargs={}, response_metadata={'prompt_feedback': {'block_reason': 0, 'safety_ratings': []}, 'finish_reason': 'STOP', 'model_name': 'gemini-2.0-flash-001', 'safety_ratings': []}, id='run-72524934-b5b5-4131-8c06-35735f1d01b7-0', usage_metadata={'input_tokens': 20, 'output_tokens': 14, 'total_tokens': 34, 'input_token_details': {'cache_read': 0}})
我们打印出来生成的文本看看:
print(ai_msg.content)
这是打印出来的文本:
我喜欢编程。(Wǒ xǐhuan biānchéng.)
llm.invoke() 方法是什么?
在 LangChain 中,llm.invoke() 是用来 向大语言模型(LLM)发送一次请求,并获取它的回答 的方法。
你可以把它理解成一个“单轮对话”的入口:
你传入一个字符串或消息列表 →模型处理它 →返回一个响应对象(通常包含 .content)
下面是一些使用示例:
示例1:最简单的用法(文本)
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(
model="gemini-2.0-flash-001",
# google_api_key="你的API密钥"
)
response = llm.invoke("讲一个关于猫的笑话")
print(response.content)
输出为:
两只猫在屋顶上聊天。
第一只猫说:“我最近抓到一只老鼠,可费劲了!”
第二只猫不屑地说:“那算什么,我昨天抓到一只蝙蝠!”
第一只猫惊讶地问:“蝙蝠?味道怎么样?”
第二只猫回答:“味道?我根本没吃,光把它从猫粮里拽出来了!”
示例 2:高级用法(多轮结构化消息)
messages = [
("system", "你是一个英语翻译助手"),
("human", "你好,帮我翻译:我爱编程"),
]
response = llm.invoke(messages)
print(response.content)
输出为:
I love programming.
Chaining 链式
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant that translates {input_language} to {output_language}.",
),
("human", "{input}"),
]
)
chain = prompt | llm
chain.invoke(
{
"input_language": "English",
"output_language": "Chinese",
"input": "I love programming.",
}
)
输出为:
AIMessage(content='我喜欢编程。(Wǒ xǐhuan biānchéng.)', additional_kwargs={}, response_metadata={'prompt_feedback': {'block_reason': 0, 'safety_ratings': []}, 'finish_reason': 'STOP', 'model_name': 'gemini-2.0-flash-001', 'safety_ratings': []}, id='run-65d905e5-9882-4145-a885-690b0c9c2665-0', usage_metadata={'input_tokens': 15, 'output_tokens': 14, 'total_tokens': 29, 'input_token_details': {'cache_read': 0}})
Image generation 图片生成
一些 Gemini 模型(特别是 gemini-2.0-flash-exp )支持图片生成功能。
Text to image 文本转图像
import base64 # 用于对图片进行Base64编码和解码
from io import BytesIO # 用于处理内存中的字节流,读取图片数据
from IPython.display import Image, display # 用于在Jupyter Notebook中显示图片
from langchain_google_genai import ChatGoogleGenerativeAI # 用于调用Google Gemini API来生成图像
# 指定使用的模型:gemini-2.0-flash-exp-image-generation(该模型支持图像生成)
llm = ChatGoogleGenerativeAI(model="models/gemini-2.0-flash-exp-image-generation")
message = {
"role": "user", # 用户角色
"content": "Generate an image of a cuddly cat wearing a hat.", # 用户发送文本
}
# 调用 `llm.invoke()` 方法来请求生成图像。`generation_config` 指定返回的内容是文本和图像。
response = llm.invoke(
[message],
generation_config=dict(response_modalities=["TEXT", "IMAGE"]),
)
# 从响应中提取生成的图片的Base64编码部分。假设响应中的'content'字段包含了图像数据的URL。
# response.content[0].get("image_url").get("url") 解析出图片的URL部分,并从中提取出Base64编码
image_base64 = response.content[0].get("image_url").get("url").split(",")[-1]
# 将Base64编码的图片数据解码为字节数据
image_data = base64.b64decode(image_base64)
# 使用IPython的display函数显示图片。这里指定宽度为300像素。
display(Image(data=image_data, width=300))
模型打印出的图片:

重复生成另一张图片
import base64
from io import BytesIO
from IPython.display import Image, display
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(model="models/gemini-2.0-flash-exp-image-generation")
message = {
"role": "user",
"content": "Generate an image of a cuddly cat wearing a hat.",
}
response = llm.invoke(
[message],
generation_config=dict(response_modalities=["TEXT", "IMAGE"]),
)
image_base64 = response.content[0].get("image_url").get("url").split(",")[-1]
image_data = base64.b64decode(image_base64)
display(Image(data=image_data, width=300))

总结以上步骤:
-
创建模型实例:你指定了要使用的 Google Gemini 模型 gemini-2.0-flash-exp-image-generation,该模型支持图像生成。
-
构造请求消息:你定义了请求内容,让模型生成一个“戴帽子的可爱猫咪”的图像。
-
调用模型生成图像:通过 llm.invoke() 方法,将请求发送给模型,并要求返回 TEXT 和 IMAGE。
-
处理生成的图像:图像内容通过 Base64 编码返回。你从响应中提取出编码部分,然后将其解码为图像数据。
-
显示图片:使用 IPython.display.Image 将图像显示在 Jupyter Notebook 中,设置宽度为 300 像素。
您也可以通过在数据 URI 方案中编码 base64 数据,将输入图像和查询表示为单条消息,这里我们让之前生成的小猫变成橙色:
# 构造发送给 Gemini 模型的 message 消息,包含文本+图片
message = {
"role": "user", # 消息角色是用户
"content": [
{
"type": "text", # 消息的第一部分是文字提示
"text": "Can you make this cat bright orange?", # 提示模型:把这只猫变成亮橘色
},
{
"type": "image_url", # 消息的第二部分是图片
"image_url": {
"url": f"data:image/png;base64,{image_base64}" # 使用 Base64 编码的图片数据构造 data URL,发送给模型
},
},
],
}
# 调用 Gemini 模型进行推理:传入文字+图片,要求返回文本+图像(多模态 response)
response1 = llm.invoke(
[message],
generation_config=dict(response_modalities=["TEXT", "IMAGE"]) # 请求生成的返回类型为文本+图片
)
# 从模型的返回结果中提取 base64 编码的图片部分
# response.content 是一个 list,其中 image_url 是图片的 data URL(例如:"data:image/png;base64,xxxxx")
image_base64 = response1.content[0].get("image_url").get("url").split(",")[-1] # 拿到逗号后面的 pure base64 部分
# 将 base64 编码解码为原始图片字节流
image_data = base64.b64decode(image_base64)
# 在 Jupyter 或 VS Code 的 Notebook 中显示图片,宽度设置为 300 像素
display(Image(data=image_data, width=300))

传入文字+图片,要求返回文本+图像(多模态 response)。那么我们打印了生成的图片,如何提取并打印出“文本内容”呢?
LangChain 的 response.content 是一个列表,每个元素是一个部分内容(比如一段文本、一个图片等),我们打印输出查看response结构以及内容。
print("类型:", type(response1.content))
print("内容:", response1.content)
类型: <class 'list'>
内容: [{'type': 'image_url', 'image_url': {'url': 'data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAwcAAAQACAIAAAA7mLIuAAAAiXpUWHRSYXcgcHJvZmlsZSB0eXBlIGlwdGMAAAiZTYwxDgIxDAT7vOKekDjrtV1T0VHwgbtcIiEhgfh/此处省略.../mqqGv8Duyi4/YnrcTwAAAAASUVORK5CYII='}}]
接下来我们分析一下这个response.content的内容:
generated_text = None
generated_image_data = None
# response1.content 可能是字符串(如果只有文本返回)或列表(多模态)
if isinstance(response1.content, str):
# 如果直接是字符串,那就是文本部分
generated_text = response1.content
print("Model returned only text.")
elif isinstance(response1.content, list):
print("Model returned multiple parts. Processing...")
# 遍历响应的各个部分
for part in response1.content:
if isinstance(part, dict):
part_type = part.get("type")
if part_type == "text":
generated_text = part.get("text")
print(f"Found text part.")
elif part_type == "image_url":
image_url_data = part.get("image_url", {}).get("url")
if image_url_data and "base64," in image_url_data:
image_base64_output = image_url_data.split(",")[-1]
generated_image_data = base64.b64decode(image_base64_output)
print(f"Found image part.")
else:
print(f"Found image_url part, but data format is unexpected: {image_url_data}")
else:
print(f"Unexpected part format in response content: {part}")
# --- 显示结果 ---
print("\n--- Processed Output ---")
if generated_text:
print("Generated Text:")
# 使用 Markdown 显示文本,格式更好看
display(Markdown(generated_text))
# 或者简单打印
# print(generated_text)
else:
print("No text part found in the response.")
输出为:
Model returned multiple parts. Processing...
Found image part.
Unexpected part format in response content:
I've made the following changes to the image:
* **The cat's fur has been changed to a bright, vibrant orange.** The original reddish-orange hue has been intensified to create a much more striking and luminous orange color across its entire body.
* Subtle shifts in the highlights and shadows on the fur were made to accommodate the new brighter orange, ensuring the texture and depth are still visible.
--- Processed Output ---
No text part found in the response.
这里我们注意到模型打印出的输出除了image部分之外,还打印了下方文字:
I've made the following changes to the image:
* **The cat's fur has been changed to a bright, vibrant orange.** The original reddish-orange hue has been intensified to create a much more striking and luminous orange color across its entire body.
* Subtle shifts in the highlights and shadows on the fur were made to accommodate the new brighter orange, ensuring the texture and depth are still visible.
这就是模型应该打印的文本信息。但是它返回文本的方式(直接作为列表中的字符串)与代码最初严格预期的格式(所有部分都是带 type 的字典)不符。调试打印语句(print(f"… {part}"))捕获并显示了这个“格式不符”但实际上是我们想要的内容。
我们原本希望模型返回的是generation_config=dict(response_modalities=[“TEXT”, “IMAGE”])这里的文本+图片,但是在将从模型的返回结果中提取 base64 编码的图片部分时,只提取了图片,所以模型没有打印出response1.content中的文本内容。
Safety Settings 安全设置
Gemini 模型具有默认的安全设置,但可以被覆盖。如果您从模型那里收到了大量的“安全警告”,您可以尝试调整模型的 safety_settings 属性。例如,要关闭危险内容的阻止,您可以构建如下的LLM:
from langchain_google_genai import (
ChatGoogleGenerativeAI,
HarmBlockThreshold,
HarmCategory,
)
llm = ChatGoogleGenerativeAI(
model="gemini-1.5-pro",
safety_settings={
HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_NONE,
},
)