目录
一.引言
二.json 方法
1.json.dumps
2.json.dump
3.json.loads
4.json.load
三.json 参数
1.ensure_ascii
2.allow_nan
3.indent
4.sortKeys
5.Other
四.LLM 数据构建
1.json 数据构建
2.Train.py
五.总结
一.引言

上文中我们介绍了 LLama2-Chinese 的简单调用与数据样本形式,在构造 LLama2 对应的数据样本过程中,发现对 json 的使用不熟练,这里整理下 json 的常用方法和常用参数,并在最后给出训练 json 生成的方法。
二.json 方法
1.json.dumps

json.dumps 用于将 python 数据结构 转换为 json 字符串,一般数据结构为 Python Dict。
train = {"instruction": "", "id": "1",
"conversations": [{"from": "human", "value": "Find the product of the numbers: 5 and 8"},
{"from": "gpt", "value": "The product of 5 and 8 is 40."}]}
print(json.dumps(train, ensure_ascii=False, indent=4))
2.json.dump

json.dump 用于将 json 字符串 存储至 文件
◆ 存储单条数据到 test.json 文件下
train = {"instruction": "", "id": "1",
"conversations": [{"from": "human", "value": "Find the product of the numbers: 5 and 8"},
{"from": "gpt", "value": "The product of 5 and 8 is 40."}]}
with open("./test.json", "w", encoding='utf8') as f:
json.dump(train, f, ensure_ascii=False, indent=4)
◆ 存储多条数据到 test.json 文件下
train_1 = {"instruction": "", "id": "1"}
train_2 = {"instruction": "", "id": "2"}
candidate = []
candidate.append(train_1)
candidate.append(train_2)
with open("./test.json", "w", encoding='utf8') as f:
json.dump(candidate, f, ensure_ascii=False, indent=4
◆ Tips
这里每一条 json 并未按一行一行存储,是因为采用了 indent 缩进参数,采用缩进参数的 json 文件更加美观易读,如果想要一行一行展示,可以去掉该参数:
with open("./test.json", "w", encoding='utf8') as f:
json.dump(candidate, f, ensure_ascii=False)
3.json.loads
json.loads 用于将 字符串 转换为 Json 对象

json_string = """[ { "from": "human", "value": "Find the product of the numbers: 5 and 8" },
{ "from": "gpt", "value": "The product of 5 and 8 is 40." } ]"""
json_info = json.loads(json_string)
print(json_info)
print(json_info[0]["from"])[{'from': 'human', 'value': 'Find the product of the numbers: 5 and 8'}, {'from': 'gpt', 'value': 'The product of 5 and 8 is 40.'}]
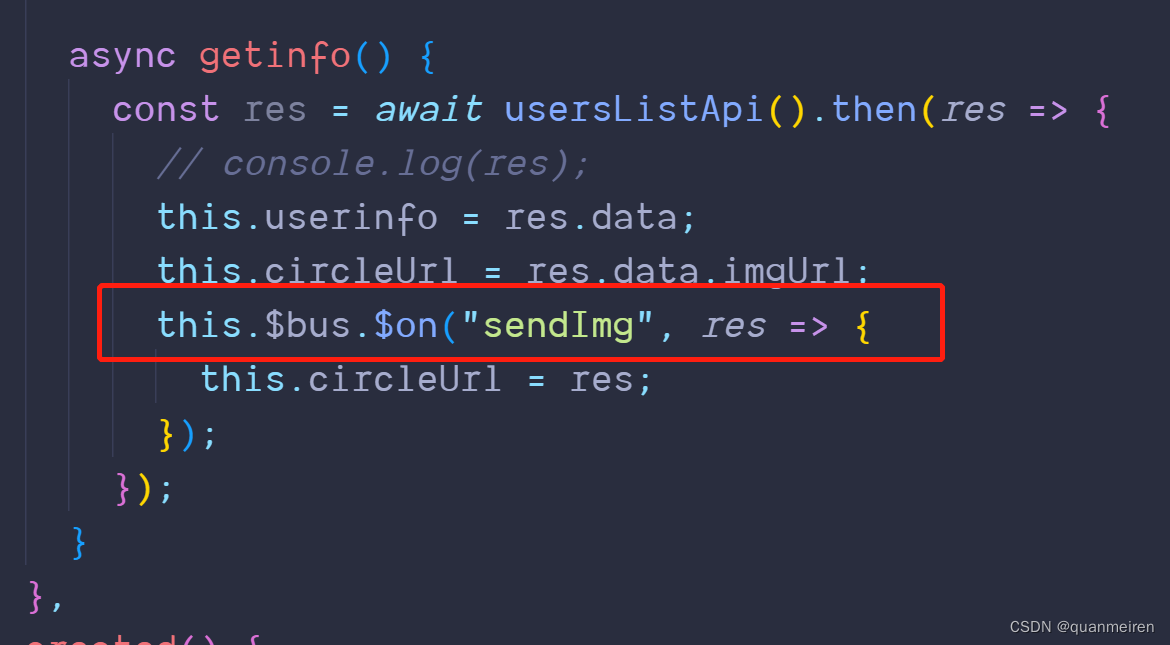
human4.json.load
json.load 用于打开 文件 并解析为 Json 对象
![]()
下面读取上面生成的 test.json 文件:
test_json = json.load(open("./test.json", "r"))
for js in test_json:
print(js){'instruction': '', 'id': '1'}
{'instruction': '', 'id': '2'}三.json 参数
LLM 样本构造时博主主要先用 dumps 方法将 Dict 转换为 Json String,然后调用 dump 方法将批量的 Json String 存入文件用于后续 LLM 模型训练,这里生成的样式与开头提到的 LLAMA-2 是一致的,也可用于 LLAMA-2 的 tokenizer 代码。
dump 和 dumps 参数整体一致,下面介绍几个常用参数含义。
1.ensure_ascii
布尔值。如果为 True,则以 ASCII 编码输出。如果为 False,则输出 UTF-8 格式,默认为 True。
train = {"instruction": "", "id": "1",
"conversations": [{"from": "人类", "value": "Find the product of the numbers: 5 and 8"},
{"from": "机器", "value": "The product of 5 and 8 is 40."}]}
print(json.dumps(train, ensure_ascii=True, indent=4))这里主要影响中文字符,例如构建中文对话样本且需要本地查看时,需要注意该参数。

2.allow_nan
布尔值。如果为 True,则允许序列化 NaN,Infinity 和 -Infinity。如果为 False,则在遇到这些值时会引发 ValueError。默认为 True。
train = {"instruction": "", "id": NaN,
"conversations": [{"from": "人类", "value": "Find the product of the numbers: 5 and 8"},
{"from": "机器", "value": "The product of 5 and 8 is 40."}]}
print(json.dumps(train, ensure_ascii=True, indent=4, allow_nan=False))json 包含 NaN 且 allow_nan=False 时,dumps 报错:

3.indent
非负整形,如果不设置该参数 json 会显示为一行,否则会以更优雅的缩进方式展示。
train = {"instruction": "", "id": NaN,
"conversations": [{"from": "人类", "value": "Find the product of the numbers: 5 and 8"},
{"from": "机器", "value": "The product of 5 and 8 is 40."}]}
print(json.dumps(train, ensure_ascii=True, indent=4, allow_nan=True))
print(json.dumps(train, ensure_ascii=True, allow_nan=True))
4.sortKeys
根据 json 的 key 进行排序,根据 key 的类型不同,排序方式也不同。
◆ Key 为文本
print(json.dumps({"A": 5, "F": 8, "D": 7, "C": 9}, sort_keys=True, indent=4)) # Key = Text && sort_keys = True
print(json.dumps({"A": 5, "F": 8, "D": 7, "C": 9}, sort_keys=False, indent=4)) # Key = Text && sort_keys = Falsekey 为文本,sort_keys = True 按顺序排列。

◆ Key 为数字
print(json.dumps({1: 5, 3: 8, 2: 7, 4: 9}, sort_keys=True, indent=4)) # Key = Num && sort_keys = True
print(json.dumps({1: 5, 3: 8, 2: 7, 4: 9}, sort_keys=False, indent=4)) # Key = Num && sort_keys = Falsekey 为数字, sort_keys = True 按顺序排列。

5.Other
◆ check_circular
布尔值。如果为 True,则检查循环引用。如果为 False,则不检查。默认为 True。
◆ separators
分隔符,是一个元祖默认 (',', ':'),代表 keys 之间用 ',' 隔开,Key-Value 用 ':' 隔开。正常情况下只要是默认 json 形式就无需修改。
◆ cls
可选的类。如果提供了这个参数,则使用这个类的实例来序列化对象。该类必须实现一个 default() 方法,接受一个要序列化的对象作为参数,返回一个可以被 JSON 库解析的 Python 对
四.LLM 数据构建
1.json 数据构建
基于上面的 json 用法,在结合我们的对话即可构造 LLM 所需要的不同格式数据,以 LLama-2 为例。这里 train_json 为我们的原始数据,我们通过 load 加载原始 json,并把 input、output 分别添加到 human_json 与 gpt_json 中,最后调用 dump 方法批量存储至新的 json 文件中。
train_json = json.load(open(inputPath, "r"))
candidate = []
id = 0
for dialogue in train_json:
human = dialogue["input"]
gpt = dialogue["output"]
train = {"instruction": "", "id": str(id)}
human_json = {"from": "human", "value": human}
gpt_json = {"from": "gpt", "value": gpt}
train["conversations"] = [human_json, gpt_json]
candidate.append(train)
id += 1
with open("./train.json", "w", encoding='utf8') as f:
json.dump(candidate, f, ensure_ascii=False, indent=4官方使用的数据集,human 和 gpt 是多轮对话,上面示例为单轮,如果为多轮只需在 conversations 列表里持续添加多轮对话再 dump json 文件即可。

运行后我们会得到类似的样本格式:

2.Train.py
LLama-2-7B Chinese 的加载 json 和处理 dataset 逻辑:Train.py ,有兴趣的同学可以回看下。

五.总结
最后是用 C-知道 追问的 json 常用方法,也算是上面的总结啦。