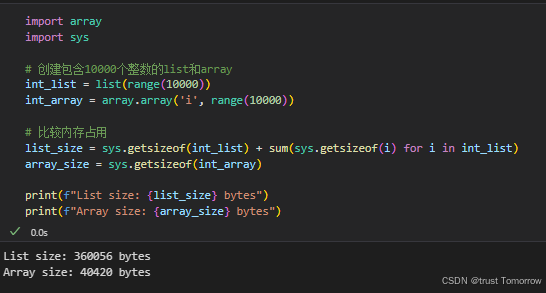
回答重点
Redis 集群(Redis cluster)是通过多个 Redis 实例组成的,每个主节点实例负责存储部分的数据,并且可以有一个或多个从节点作为备份。
具体是采用哈希槽(Hash Slot)机制来分配数据,将整个键空间划分为 16384 个槽(slots)。每个 Redis 主节点实例负责一定范围的哈希槽,数据的 key 经过 CRC16-CCITT 哈希算法计算后对 16384 取余即可定位到对应的节点。
客户端在发送请求时,会通过集群的任意节点进行连接,如果该节点存储了对应的数据则直接返回,反之该节点会根据请求的键值计算哈希槽并路由到正确的节点。现代 Redis 客户端通常会缓存槽位映射信息,避免频繁重定向。
简单来说,集群就是通过多台机器分担单台机器上的压力,同时通过主从复制提供高可用性。
扩展知识
Redis 集群中节点之间的信息如何同步?
Redis 集群内每个节点都会保存集群的完整拓扑信息,包括每个节点的 ID、IP 地址、端口、负责的哈希槽范围等。
节点之间使用 Gossip 协议进行状态交换,以保持集群的一致性和故障检测。每个节点会周期性地发送 PING 和 PONG 消息,交换集群信息,使得集群信息得以同步。
Gossip 的优点:
- 最终一致性:Gossip 协议能够在一段时间后使集群信息达成一致,虽然传播速度不如中心化方案快,但网络开销更小。
- 降低网络负担:由于信息是以随机节点间的对话方式传播,避免了集中式的状态查询,从而降低了网络流量。
Gossip 协议
Gossip 主要特点:
- 分布式信息传播:每个节点定期向其他节点发送其状态信息,确保所有节点对集群的状态有一致的视图。
- 低延迟和高效率:Gossip 协议设计为轻量级的通信方式,能够快速传播信息,减少单点故障带来的风险。
- 去中心化:没有中心节点,所有节点平等地参与信息传播,提高了系统的鲁棒性。
工作原理:
- 状态报告:每个节点在特定的时间间隔内,向随机选择的其他节点发送其自身的状态信息,包括节点的主从关系、槽位分布等。
- 信息更新:接收到状态信息的节点会根据所接收到的数据更新自己的状态,并将更新后的状态继续传播给其他节点。
- 节点检测:通过周期性交换状态信息,节点可以检测到其他节点的存活状态。如果某个节点未能在预定时间内响应,则该节点会被标记为故障节点。
- 容错处理:在检测到节点故障后,集群中的其他节点可以采取措施(如重新分配槽位)以保持系统的高可用性。
Redis 集群分片原理图示
Redis 集群会将数据分散到 16384(2^14)个哈希槽中,集群中的每个主节点负责一定范围的哈希槽,在 Redis 集群中,使用 CRC16-CCITT 哈希算法计算键的哈希槽,以确定该键应存储在哪个节点。
集群哈希槽分片如下图所示:
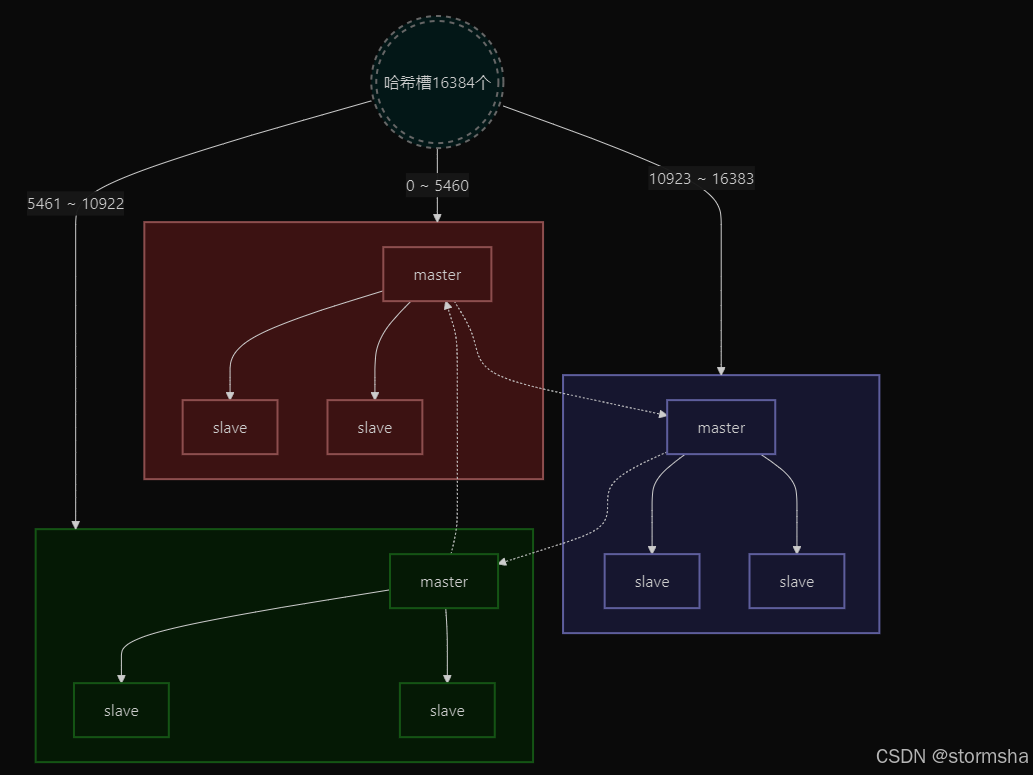
每个节点会拥有一部分的槽位,然后对应的键值会根据其本身的 key,映射到一个哈希槽中,其主要流程如下:
- 根据键值的 key,按照 CRC16-CCITT 算法计算一个 16 bit 的值,然后将 16 bit 的值对 16384 进行取余运算,最后得到一个对应的哈希槽编号。
- 值得注意的是,Redis 支持哈希标签(Hash Tags)机制,即如果键名中包含 “{…}” 格式的内容,那么只有花括号内的内容会被用来计算哈希槽,这样可以确保相关联的键被分配到同一个槽中。
- 根据每个节点分配的哈希槽区间,对应编号的数据落在对应的区间上,就能找到对应的分片实例。
为了方便大家理解,我这里画一个对应的关系图,以三个节点为例:
Redis 哈希槽映射图
这里还有一点需要强调下,Redis 客户端可以访问集群中任意一台实例,正常情况下这个实例包含这个数据
但如果槽被转移了,客户端还未来得及更新槽的信息,当前实例没有这个数据,则返回 MOVED 响应给客户端,将其重定向到对应的实例(因 Gossip 协议确保集群内每个节点都会保存集群的完整拓扑信息)。
Redis 集群中存储 key 示例
假设我们有一个 Redis 集群,包含三个主节点(Node1、Node2、Node3),它们分别负责以下哈希槽:
- Node1: 哈希槽 0-5460
- Node2: 哈希槽 5461-10922
- Node3: 哈希槽 10923-16383
现在要存储一个键为 user:1001 的数据。
计算哈希槽
- 使用 CRC16-CCITT 哈希算法计算
user:1001的 CRC16 值。 - 假设计算结果为 12345。
- 然后,计算该值对应的哈希槽:
- 哈希槽 = 12345 % 16384 = 12345。
确定目标节点
- 12345 落在 Node3 的负责范围(10923-16383),因此,
user:1001会被存储在 Node3 中。
Redis 集群中请求 key 示例(客户端直接连接的并不是对应 key 的节点)
如果客户端连接的是集群的 Node1,但需要访问存储在 Node3 的键 user:1001,查询过程如下:
查询过程
1)计算哈希槽:
- 客户端使用 CRC16-CCITT 算法计算
user:1001的哈希值(假设为 12345)。 - 计算哈希槽:12345 % 16384 = 12345。
2)查询请求:
- 因为客户端连接的是集群中的 Node1,所以客户端发送查询命令
GET user:1001到 Node1。
3)Node1 响应:
- Node1 检测到请求的键
user:1001属于 Node3,返回一个MOVED错误,指示客户端请求的键在另一个节点上。MOVED错误中会返回目标节点的信息(例如,Node3 的 IP 和端口)。
4)客户端处理:
- 现代 Redis 客户端会缓存此槽位映射信息,后续对该槽的请求会直接发送到正确的节点,避免重定向。
- 第一次收到 MOVED 错误时,客户端会连接到目标节点并更新槽位映射缓存。
5)发送查询请求到正确节点:
- 客户端向 Node3 发送
GET user:1001。
6)获取结果:
- Node3 查询到
user:1001的值(假设为{"name": "stormsha", "age": 16}),并返回结果。
为什么 Redis 哈希槽节点的数目是 16384 呢?
1)首先是消息大小的考虑。
正常的心跳包需要带上节点完整配置数据,心跳还是比较频繁的,所以需要考虑数据包的大小,如果使用 16384 数据包只要约 2KB,如果用了 65536 则需要约 8KB。
实际上槽位信息使用一个长度为 16384 位的位图(bitmap)来表示,节点拥有哪个槽位,就将对应位置的位设置为 1,否则为 0。
Redis 心跳消息(CLUSTERMSG)数据结构如下所示:
typedef struct {
char sig[4]; /* 信息标识 */
uint32_t totlen; /* 消息总长度 */
uint16_t ver; /* 协议版本 */
uint16_t type; /* 消息类型, 用于区分meet,ping,pong等消息 */
uint16_t count; /* 消息体包含的节点数量, 仅用于meet,ping,pong消息类型*/
uint64_t currentEpoch; /* 当前发送节点的配置纪元 */
uint64_t configEpoch; /* 主节点/从节点的主的配置纪元 */
char sender[CLUSTER_NAMELEN]; /* 发送节点的nodeId */
unsigned char myslots[CLUSTER_SLOTS/8]; /* 发送节点负责的槽信息 */
char slaveOf[CLUSTER_NAMELEN]; /* 如果是从节点,记录主节点的nodeId */
uint16_t port; /* 端口号 */
uint16_t flags; /* 发送节点标识,区分主从角色,是否下线等 */
unsigned char state; /* 发送节点的集群状态 */
unsigned char mflags[3]; /* 消息标识 */
union clusterMsgData data /* 消息正文 */;
} clusterMsg;
这里我们看到一个重点,即在消息头中最占空间的是 myslots[CLUSTER_SLOTS/8]:
- 当槽位为 65536 时,这部分大小: 65536÷8=8192 字节 ≈8KB
- 当槽位为 16384 时,这部分大小: 16384÷8=2048 字节 ≈2KB
如果槽位为 65536,这个心跳消息的头部就太大了,在高频率通信的集群环境中会显著增加网络负担。
2)集群规模的考虑。
根据 Redis 作者的说明,集群不太可能会扩展超过 1000 个节点,而每个主节点应该管理相当数量的哈希槽。如果使用 16384 个槽位:
- 100 个节点集群:平均每个节点管理约 164 个槽位
- 1000 个节点集群:平均每个节点管理约 16 个槽位
这个数量既能满足大多数集群规模需求,又不会因为槽位过少而影响数据分布均衡性。
3)内存占用的平衡
Redis 作为内存数据库,对内存使用的效率非常关注。16384 个槽位的设计在集群功能和资源消耗之间取得了很好的平衡:足够多的槽位保证良好的数据分布,同时槽位映射的内存占用和网络传输开销都保持在合理范围内。
好的,以下是测试题目与解析部分分开的版本:
✅ Redis 集群选择题(共 4 题)
1. Redis 集群采用什么机制来分配数据到不同的节点? ( )
A. 哈希槽机制
B. 主备机制
C. 哈希链机制
D. 分段机制
2. Redis 集群中有多少个哈希槽? ( )
A. 2048
B. 8192
C. 16384
D. 32768
3. Redis 集群中的节点之间使用什么协议进行状态同步和故障检测? ( )
A. TCP/IP 协议
B. HTTP 协议
C. UDP 协议
D. Gossip 协议
4. 在 Redis 集群中,当客户端请求的键值对不在连接的节点上时,返回的错误类型是什么? ( )
A. ERROR
B. MOVED
C. NOT_FOUND
D. FORBIDDEN
📘 答案与解析
1. 正确答案:A
解析:Redis 集群通过哈希槽机制进行数据分配,避免单点瓶颈,将键映射到 16384 个槽中,再分配到不同节点。
2. 正确答案:C
解析:Redis 集群采用固定的 16384 个哈希槽,这个值是 2¹⁴,设计用于在带宽与灵活性之间做出平衡。
3. 正确答案:D
解析:Redis 集群使用 Gossip 协议实现去中心化状态同步和故障检测,各节点定期交换信息。
4. 正确答案:B
解析:当客户端请求的 key 不在当前节点时,Redis 返回 MOVED 重定向错误,引导客户端访问正确节点。