一、预训练
对于一个具有少量数据的任务 A,首先通过一个现有的大量数据搭建一个 CNN 模型 A,由于 CNN的浅层学到的特征通用性特别强,因此在搭建一个 CNN 模型 B,其中模型 B 的浅层参数使用模型 A 的浅层参数,模型 B 的高层参数随机初始化,然后通过冻结或微调的方式利用任务 A 的数据训练模型 B,模型 B 就是对应任务 A 的模型。
预训练的思想:任务 A 对应的模型 A 的参数不再是随机初始化的,而是通过任务 B 进行预先训练得到模型 B,然后利用模型 B 的参数对模型 A 进行初始化,再通过任务 A 的数据对模型 A 进行训练。
注:模型 B 的参数是随机初始化的
二、语言模型
语言模型通俗点讲就是计算一个句子的概率。
给定一句由n个词组成的句子W = w1,w2,…,wn,计算该序列的概率,即P(w1,w2,…,wn),或者根据上下文计算下一个词的概率P(wn|w1,w2,…,wn-1)。
Eg.
- 假设给定两句话 “判断这个词的磁性” 和 “判断这个词的词性”,语言模型会认为后者更自然。转化成数学语言也就是:𝑃(判断,这个,词,的,词性)>𝑃(判断,这个,词,的,磁性)
- 假设给定一句话做填空 “判断这个词的____”,则问题就变成了给定前面的词,找出后面的一个词是什么,转化成数学语言就是:𝑃(词性|判断,这个,词,的)>𝑃(磁性|判断,这个,词,的)
语言模型的两个分支,统计语言模型和神经网络语言模型。
1.统计语言模型
基本思想是计算条件概率
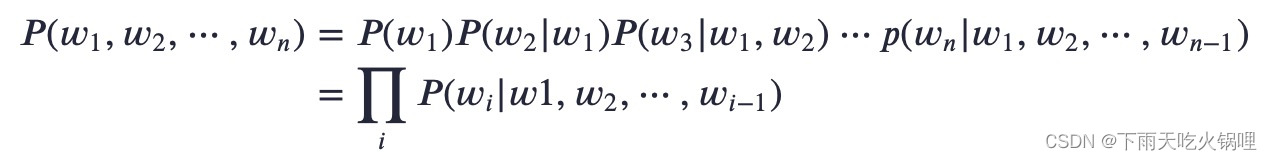
马尔科夫链:假设𝑤𝑛𝑒𝑥𝑡只和它之前的𝑘个词有相关性,𝑘=1时称作一个单元语言模型,𝑘=2时称为二元语言模型
2.神经网络语言模型
神经网络语言模型引入神经网络架构来估计单词的分布,并且通过词向量的距离衡量单词之间的相似度,因此,对于未登录单词,也可以通过相似词进行估计,进而避免出现数据稀疏问题。
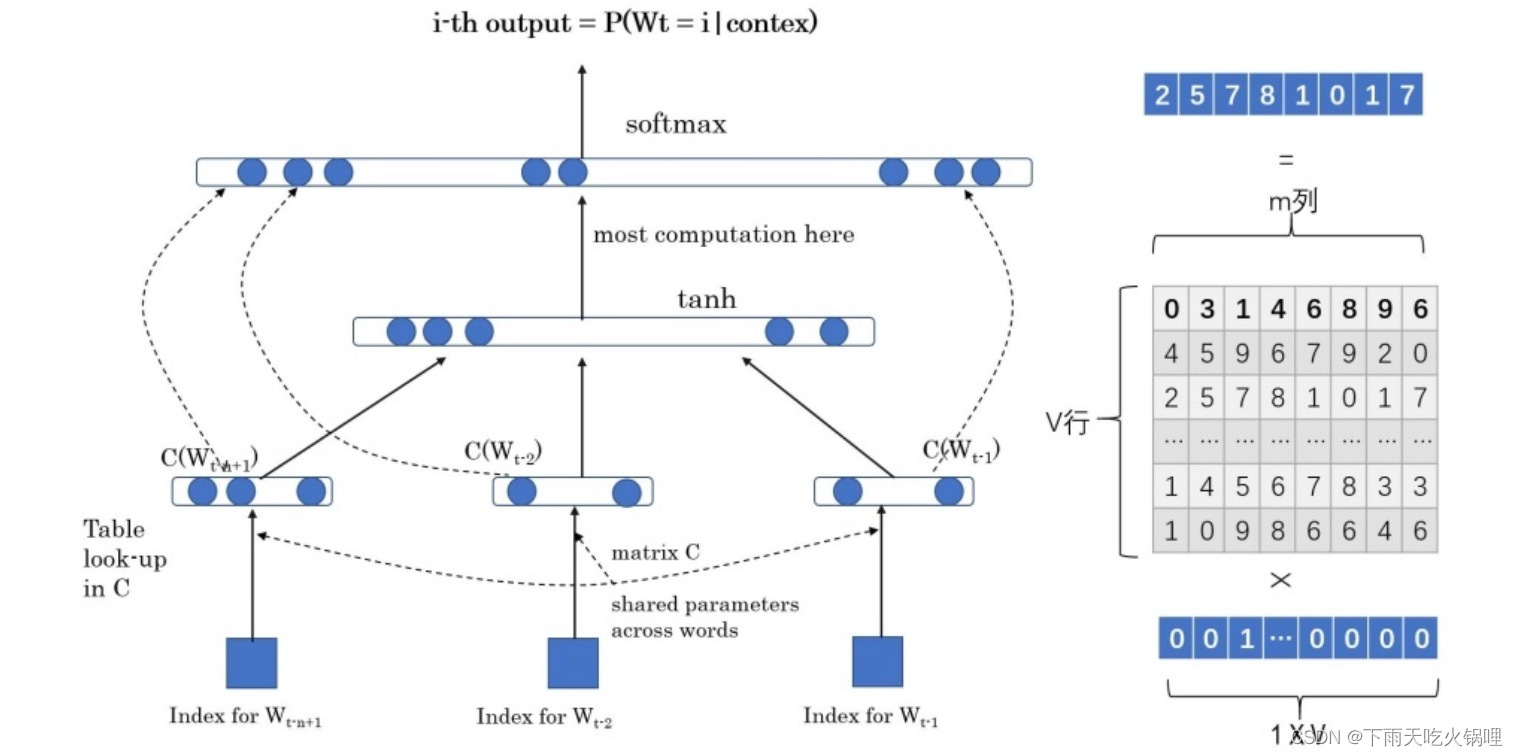
学习任务是输入某个句中单词𝑤𝑡=𝑏𝑒𝑟𝑡前的𝑡−1个单词,要求网络正确预测单词 “bert”,即最大化:
𝑃(𝑤𝑡=𝑏𝑒𝑟𝑡|𝑤1,𝑤2,⋯,𝑤𝑡−1;𝜃)
- 输入层:将前𝑛−1个单词用 Onehot 编码(例如:0001000)作为原始单词输入,乘以一个随机初始化的矩阵 Q 后获得词向量𝐶(𝑤𝑖),对这𝑛−1个词向量处理后得到输入𝑥,记作𝑥=(𝐶(𝑤1),𝐶(𝑤2),⋯,𝐶(𝑤𝑡−1))
- 隐层:包含ℎ个隐变量,𝐻代表权重矩阵,隐层的输出为𝐻𝑥+𝑑,𝑑为偏置项,在此之后使用𝑡𝑎𝑛ℎ作为激活函数
- 输出层:一共有|𝑉|个输出节点(字典大小),每个输出节点𝑦𝑖是词典中每一个单词概率值。
最终得到的计算公式为:𝑦=𝑠𝑜𝑓𝑡𝑚𝑎𝑥(𝑏+𝑊𝑥+𝑈tanh(𝑑+𝐻𝑥))
其中𝑊是直接从输入层到输出层的权重矩阵,𝑈是隐层到输出层的参数矩阵
三、词向量
1.独热(Onehot)编码
把单词用向量表示,是把深度神经网络语言模型引入自然语言处理领域的一个核心技术。
对于独热表示的向量,如果采用余弦相似度计算向量间的相似度,发现任意两者向量的相似度结果都为 0,即任意二者都不相关,也就是说独热表示无法解决词之间的相似性问题。
2.Word Embedding
词向量𝐶(𝑤𝑖),对的,这个𝐶(𝑤𝑖)其实就是单词对应的 Word Embedding 值
上图所示:𝑉×𝑚的矩阵𝑄,这个矩阵𝑄包含𝑉行,𝑉代表词典大小,每一行的内容代表对应单词的 Word Embedding 值,𝑄的内容也是网络参数,需要学习获得,训练刚开始用随机值初始化矩阵𝑄,当这个网络训练好之后,矩阵𝑄的内容被正确赋值,每一行代表一个单词对应的 Word embedding 值,可以一定程度上描述两个词之间的相似度(一个单词表达成 Word Embedding 后,很容易找出语义相近的其它词汇)
四、Word2Vec 模型
2013年语言模型做 Word Embedding 的工具是 Word2Vec 、Glove(两者类似,不再赘述)
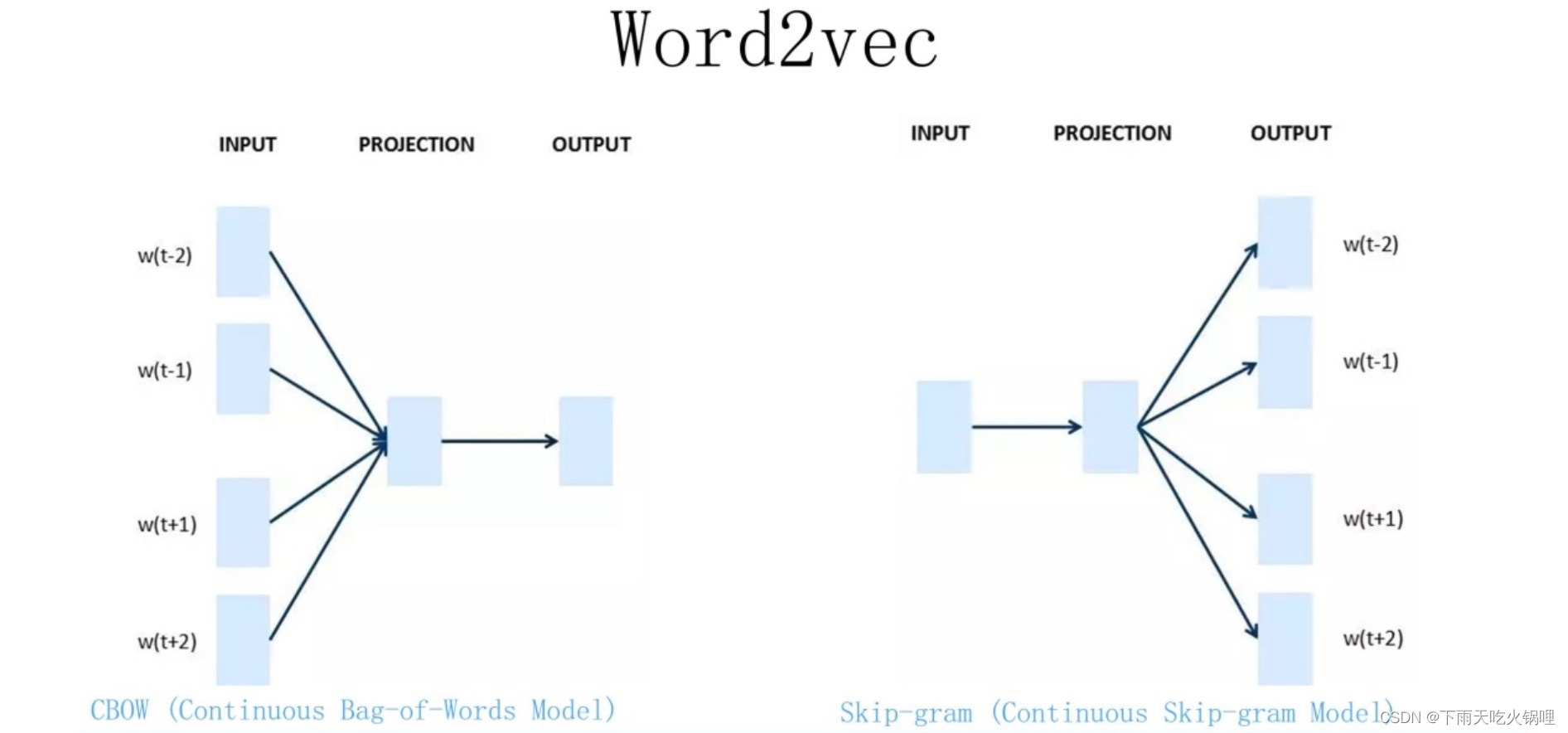
Word2Vec 有两种训练方法:
- CBOW,核心思想是从一个句子里面把一个词抠掉,用这个词的上文和下文去预测被抠掉的这个词;
- Skip-gram,和 CBOW 相反过来,输入某个单词,预测上下文单词。
五、自然语言处理的预训练模型
2018年之前典型预训练模式:
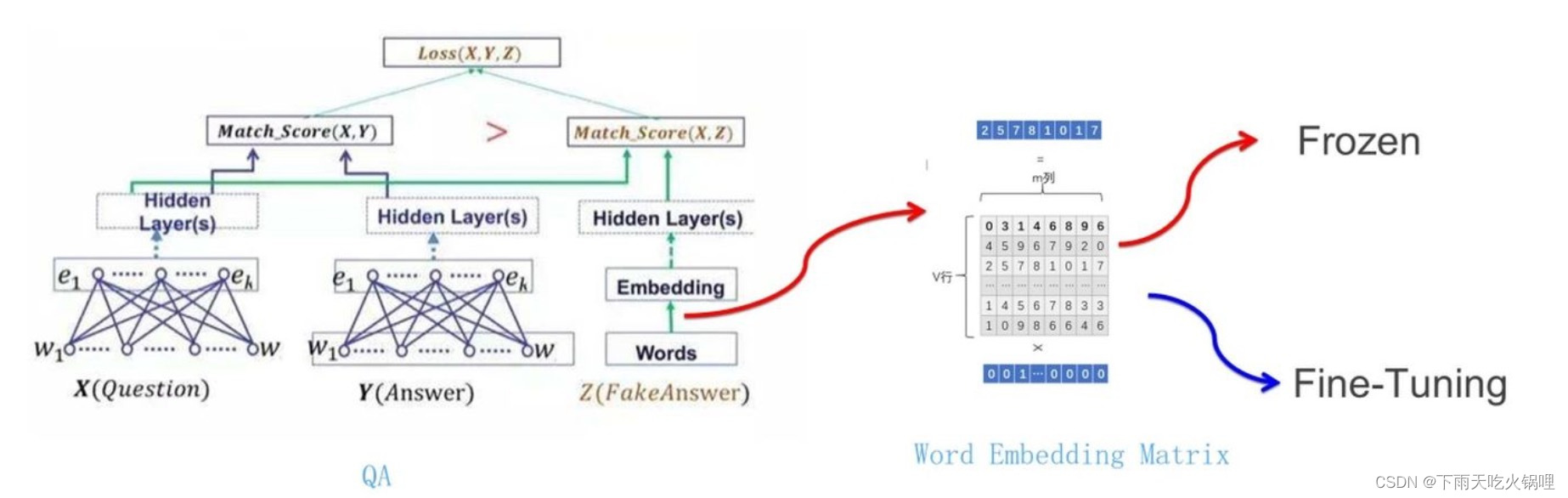
QA:给定一个问题 X,另外一个句子 Y,判断句子 Y 是否是问题 X 的正确答案
网络如何使用训练好的 Word Embedding :
句子中每个单词以 Onehot 形式作为输入,乘以学好的 Word Embedding 矩阵 Q,得到单词对应的 Word Embedding,Word Embedding矩阵Q其实就是网络 Onehot 层到 embedding 层映射的网络参数矩阵,用 Word Embedding 等价于把 Onehot 层到 embedding 层的网络用预训练好的参数矩阵 Q 初始化,与前面的图像领域的低层预训练过程一样, Word Embedding 只能初始化第一层网络参数。
六、RNN和LSTM
1.RNN
传统的神经网络无法获取时序信息,然而时序信息在自然语言处理任务中非常重要
RNN 的基本单元结构如下图所示:

左边部分称作 RNN 的一个 timestep,在𝑡时刻,输入变量𝑥𝑡,通过 RNN 的一个基础模块 A,输出变量ℎ𝑡,而𝑡时刻的信息,将会传递到下一个时刻𝑡+1。如果把模块按照时序展开,则会如上图右边部分所示,由此可以看到 RNN 为多个基础模块 A 的互连,每一个模块都会把当前信息传递给下一个模块。
RNN 解决了时序依赖问题(短距离)
- 短距离依赖:对于填空题 “我想看一场篮球____”,很容易就判断出 “篮球” 后面跟的是 “比赛”,这种短距离依赖问题非常适合 RNN。
- 长距离依赖:对于这个填空题 “我出生在中国的瓷都景德镇,小学和中学离家都很近,……,我的母语是____”,对于短距离依赖,“我的母语是” 后面可以紧跟着 “汉语”、“英语”、“法语”,但是如果我们想精确答案,则必须回到上文中很长距离之前的表述 “我出生在中国的瓷都景德镇”,进而判断答案为 “汉语”,而 RNN 是很难学习到这些信息。
注意:RNN和DNN梯度消失和梯度爆炸含义并不相同
RNN中权重在各时间步内共享,最终的梯度是各个时间步的梯度和,梯度和会越来越大。因此,RNN中总的梯度是不会消失的,即使梯度越传越弱,也只是远距离的梯度消失。RNN所谓梯度消失的真正含义是,梯度被近距离(𝑡+1趋向于𝑇)梯度主导,远距离(𝑡+1远离𝑇)梯度很小,导致模型难以学到远距离的信息。
2.LSTM
为了解决 RNN 缺乏的序列长距离依赖问题,LSTM 被提出:
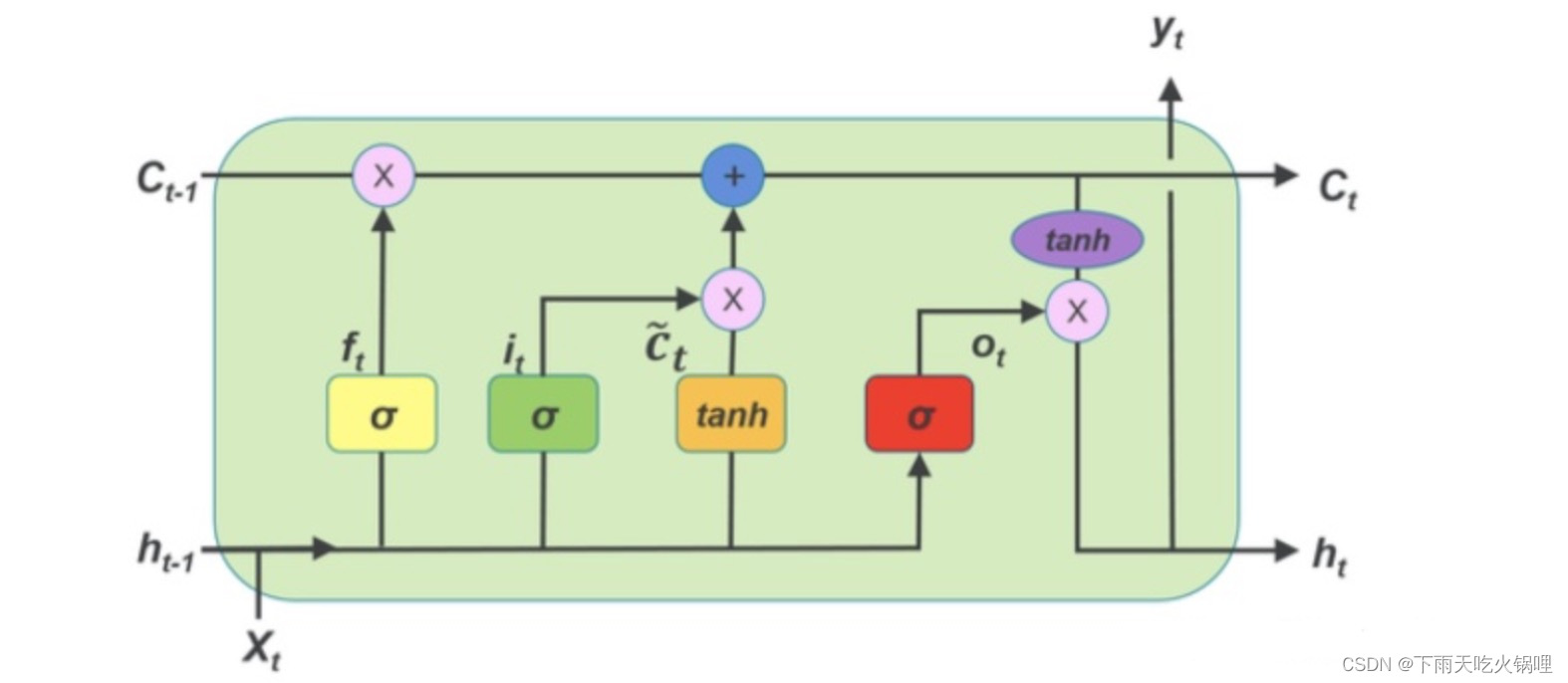
除了在结构上天然地克服了梯度消失的问题,更重要的是具有更多的参数来控制模型;通过四倍于RNN的参数量,可以更加精细地预测时间序列变量。
七、ELMo 模型
1.ELMo 的预训练
Word Embedding 表示方法本质上是静态的,每一个词都有一个唯一确定的词向量,不能根据句子的不同而改变,无法处理自然语言处理任务中的多义词问题。
ELMo 的本质思想是:先用语言模型学好一个单词的 Word Embedding,此时多义词无法区分,实际使用 Word Embedding 时,单词已经具备了特定的上下文,这个时候根据上下文单词的语义再去调整单词的 Word Embedding 表示,这样经过调整后的 Word Embedding 更能表达在这个上下文中的具体含义。
根据当前上下文对 Word Embedding 动态调整
ELMo 采用了典型的两阶段过程:
- 第一阶段是利用语言模型进行预训练;
- 第二阶段是在下游任务从预训练网络中提取对应单词的网络各层的 Word Embedding 作为新特征补充到下游任务中。
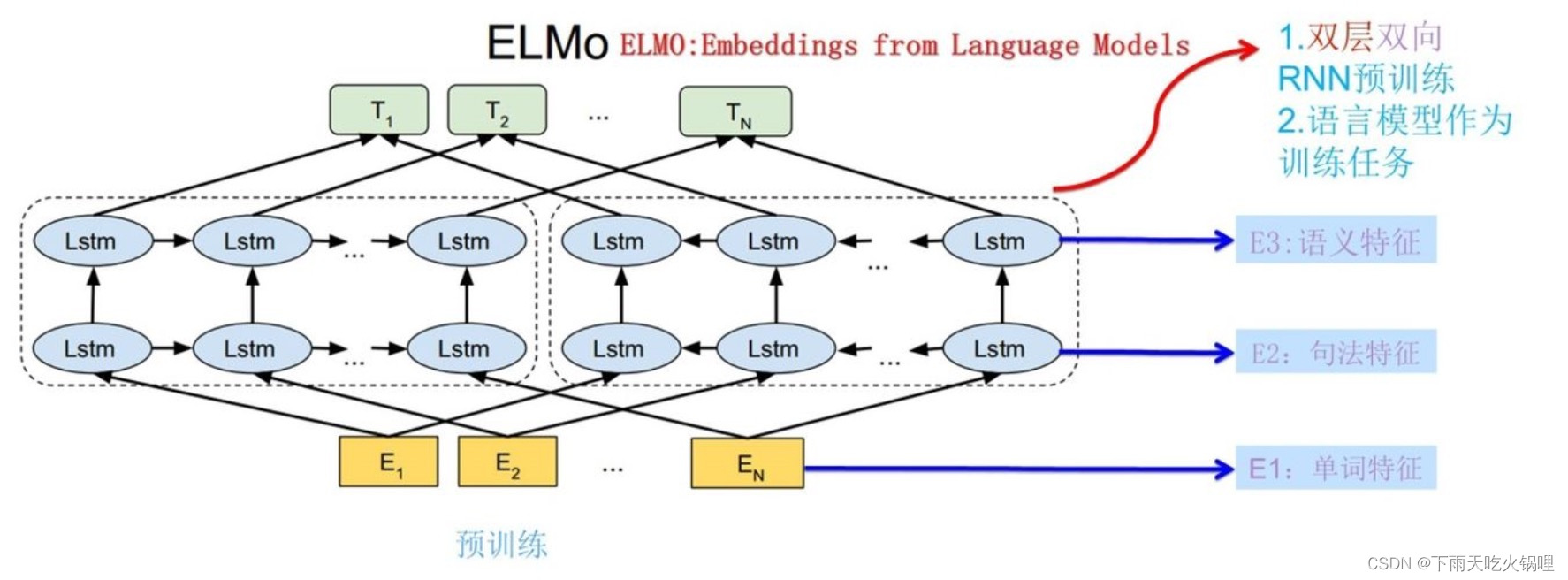
句子中每个单词都能得到对应的三个 Embedding:
- 最底层是单词 Word Embedding;
- 第一层双向 LSTM 中对应单词位置的 Embedding,这层编码单词的句法信息更多;
- 第二层 LSTM 中对应单词位置的 Embedding,这层编码单词的语义信息更多。
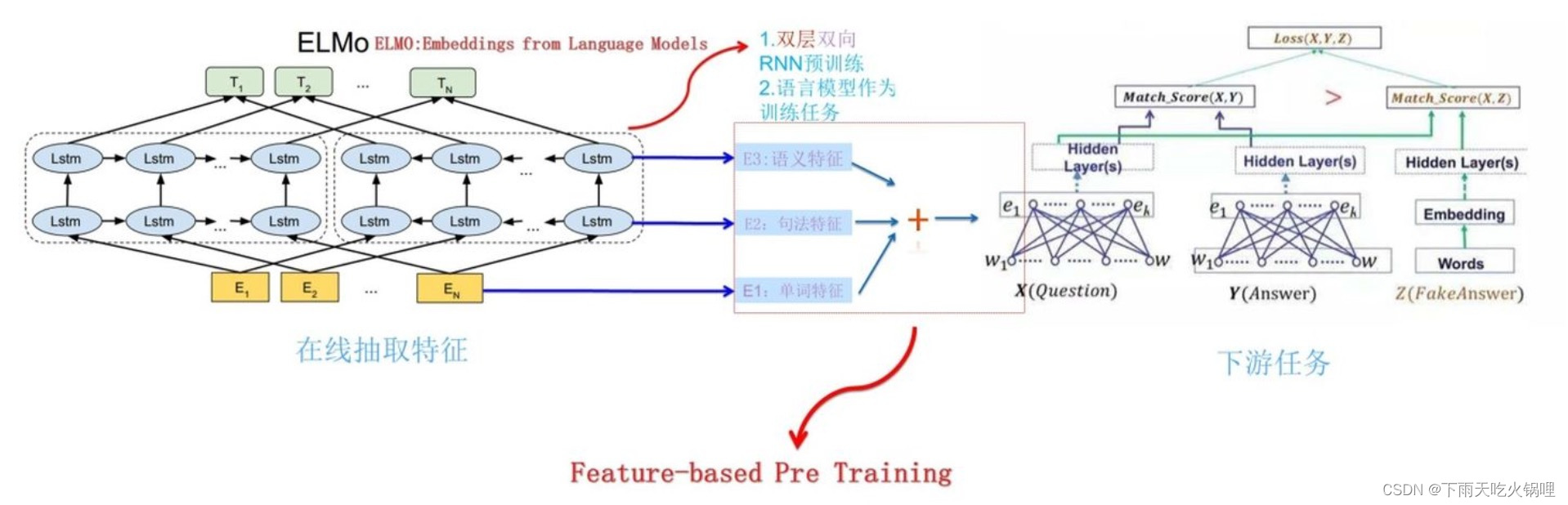
ELMo 给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为 “Feature-based Pre-Training”。
训练好 ELMo 后,特征提取时,每个单词在两层 LSTM 上都有对应节点,这两个节点编码单词的一些句法特征和语义特征,并且它们的 Embedding 编码是动态改变的,受上下文单词的影响,周围单词的上下文不同会强化某种语义,弱化其它语义,进而就解决了多义词的问题。
八、Attention
1.人类的视觉注意力
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
深度学习中的注意力机制核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
2.Attention 本质思想
从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略不重要的信息。
Attention 机制可以更加好的解决序列长距离依赖问题,并且具有并行计算能力。
注意力模型,有一个 Query 和一个 Values,通过 Query 这个信息从 Values 中筛选出重要信息,即计算 Query 和 Values 中每个信息的相关程度。
3.Self Attention
Self Attention 有三个输入 Q、K、V:对于 Self Attention,Q、K、V 来自句子 X 的词向量 x 的线性转化,即对于词向量 x,给定三个可学习的矩阵参数𝑊𝑄,𝑊𝑘,𝑊𝑣,x 分别右乘上述矩阵得到 Q、K、V。
- RNN、LSTM:
依次序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。
- Self Attention:
1)更容易捕获句子中长距离的相互依赖的特征,因为 Self Attention 在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征;
2)计算的并行性:Self Attention 对于一句话中的每个单词都可以单独的进行 Attention 值的计算
(Self-Attention解决了 RNN 模型的长序列依赖问题,但文本长度增加时,训练时间也将会呈指数增长)
4.Masked Self Attention
假设已经得到一个 attention map,而 mask 就是沿着对角线把灰色的区域用0覆盖掉,不给模型看到未来的信息。
5.Multi-head Self Attention
Multi-Head Attention 把 Self Attention 得到的注意力值𝑍切分成 n 个𝑍1,𝑍2,⋯,𝑍𝑛,通过全连接层获得新的𝑍′
multi-head attention 流程:
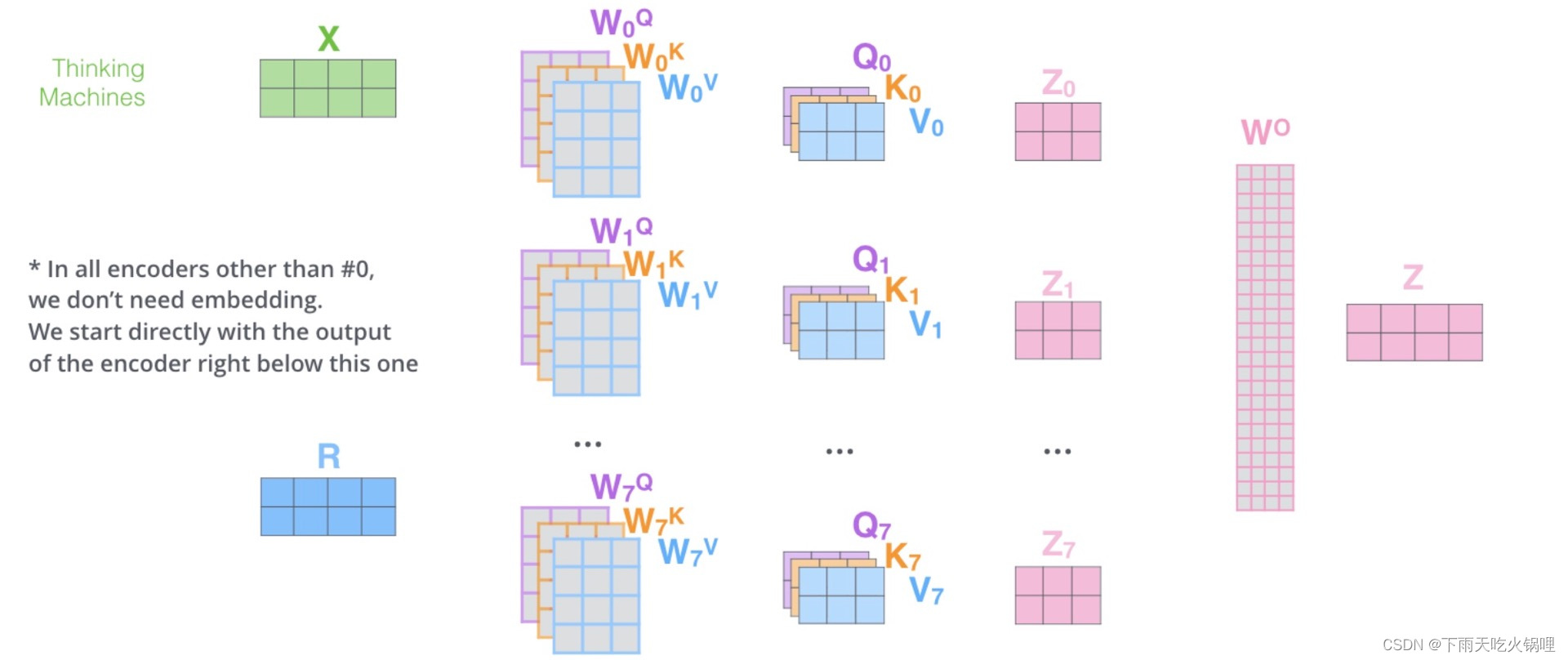
多头相当于把原始信息放入了多个子空间中,捕捉了多个信息,保证了 attention 可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。
九、Position Embedding
由于 Attention 值的计算最终会被加权求和,两者最终计算的 Attention 值都是一样,表明了 Attention 丢掉了𝑋1的序列顺序信息。为了解决 Attention 丢失的序列顺序信息,Transformer 的提出者提出了 Position Embedding,也就是对于输入𝑋进行 Attention 计算之前,在𝑋的词向量中加上位置信息,𝑋的词向量为𝑋𝑓𝑖𝑛𝑎𝑙_𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔=𝐸𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔+𝑃𝑜𝑠𝑖𝑡𝑖𝑜𝑛𝑎𝑙𝐸𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔。
十、Transformer
self-attention 模型的叠加
十一、GPT
GPT : “Generative Pre-Training” ,采用两阶段过程:
- 第一个阶段:利用语言模型进行预训练;
- 第二个阶段:通过 Fine-tuning 的模式解决下游任务。
单向的语言模型,采用 Context-before 这个单词的上文来进行预测,而抛开了下文。
十二、BERT
作为公认的里程碑式的模型,最大的优点不是创新,而是集大成者:参考了 ELMO 模型的双向编码思想、借鉴了 GPT 用 Transformer 作为特征提取器的思路、采用了 word2vec 所使用的 CBOW 方法。
BERT :从大量无标记数据集中训练得到的深度模型,可以显著提高各项自然语言处理任务的准确率。
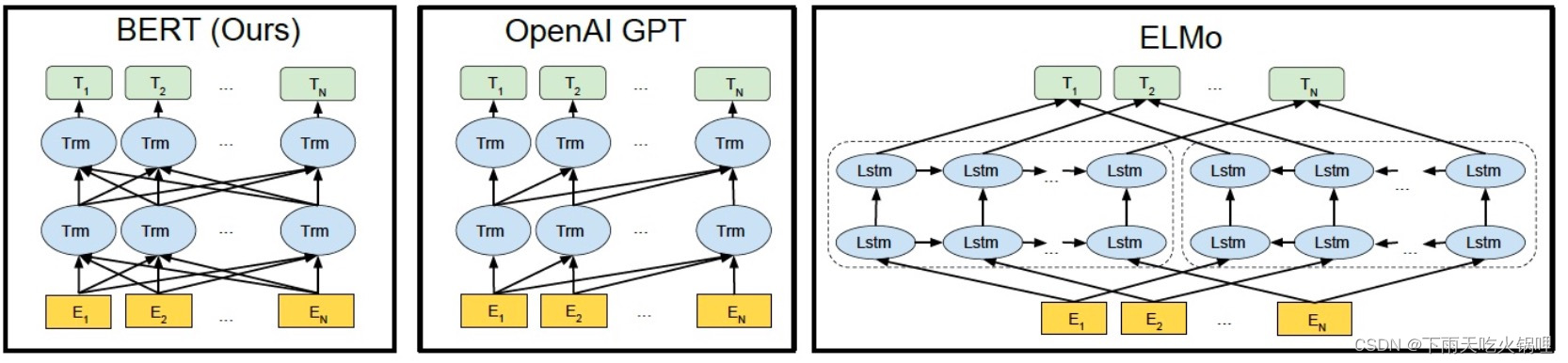
- ELMo 使用自左向右编码和自右向左编码的两个 LSTM 网络,以P(𝑤𝑖|𝑤1,⋯,𝑤𝑖−1)和𝑃(𝑤𝑖|𝑤𝑖+1,⋯,𝑤𝑛)为目标函数独立训练将训练得到的特征向量以拼接的形式实现双向编码,本质上还是单向编码,只不过是两个方向上的单向编码的拼接而成的双向编码。
- GPT 使用 Transformer Decoder 作为 Transformer Block,以𝑃(𝑤𝑖|𝑤1,⋯,𝑤𝑖−1)为目标函数用 Transformer Block 取代 LSTM 作为特征提取器,实现了单向编码,是一个标准的预训练语言模型,即使用 Fine-Tuning 模式解决下游任务。
- BERT 也是一个标准的预训练语言模型,它以𝑃(𝑤𝑖|𝑤1,…,𝑤𝑖−1,𝑤𝑖+1,…,𝑤𝑛)为目标函数进行训练,BERT 使用的编码器属于双向编码器。
和 GPT 一样,BERT 也采用二段式训练方法:
- 第一阶段:使用易获取的大规模无标签数据训练基础语言模型;
- 第二阶段:根据指定任务的少量带标签训练数据进行微调训练。
不同于 GPT 等标准语言模型使用𝑃(𝑤𝑖|𝑤1,…,𝑤𝑖−1)为目标函数进行训练,能看到全局信息的 BERT 使用𝑃(𝑤𝑖|𝑤1,…,𝑤𝑖−1,𝑤𝑖+1,…,𝑤𝑛)为目标函数进行训练。并且 BERT 用语言掩码模型(MLM)方法训练词的语义理解能力;用下句预测(NSP)方法训练句子之间的理解能力,从而更好地支持下游任务。
在模型微调训练阶段或模型推理(测试)阶段,输入的文本中将没有 [MASK],进而导致产生由训练和预测数据偏差导致的性能损失。
考虑到上述的弊端,BERT 并没有用 [MASK] 替换掩码词,而是按照一定比例选取替换词。
- 80% 练样本中:将选中的词用 [MASK] 来代替
- 10% 的训练样本中:选中的词不发生变化,该做法是为了缓解训练文本和预测文本的偏差带来的性能损失
- 10% 的训练样本中:将选中的词用任意的词来进行代替,该做法是为了让 BERT 学会根据上下文信息自动纠错