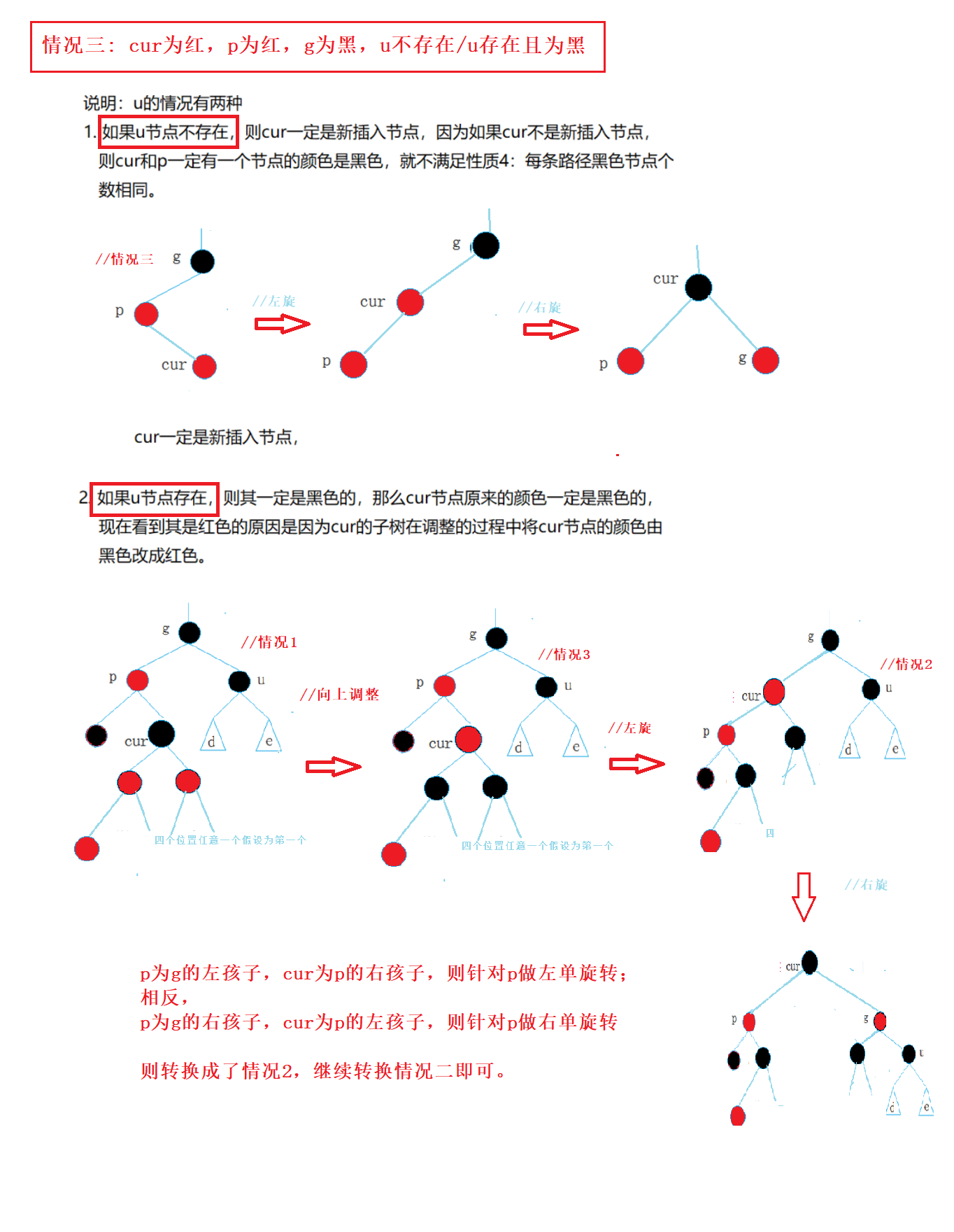
总结几个细节点:
1、置信度计算:
训练时:
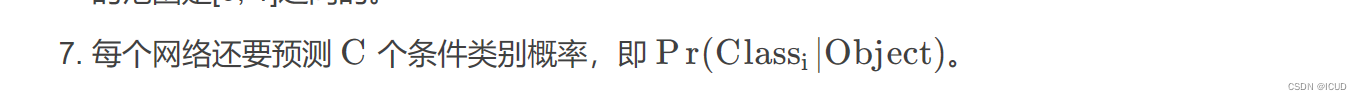
测试时置信度,这里网络输出仍然是

以上是各大博文讲解时列出的也是论文中提到的公式,但其实最清楚的是下面这段文字讲出的:

说白了:
网络输出三个东西:confidence、bbox信息、类别预测概率
(1)在训练阶段:网络中输出的confidence值指的是Pr(objectiveness)*IOU(pred、groundtruth),同时由于我们训练时有一个预先标注好的框groundtruth,所以这时候对于有物体的grid cell来说我们目标confidence肯定就是1,我们希望网络输出的confidence是1(Pr(objectiveness)=1且IOU=1),这样就说明网络能输出一个预测框(这个grid cell 里有物体),同时预测框和标注的框(groundtruth)重合了,这时网络太牛逼了!
(2)在训练阶段,其实没区别,只是说,我们已经训练出来一个觉得不错的网络了,这时候来预测,那预测得到的confidence其实还是说:我网络认为这个grid cell对应是否有一个物体,如果有,我网络预测得到的bbox信息你画出来,大概和真实物体的IOU也反映在我输出的confidence里。
比如给一张图片,训练好的网络,我直接预测,某一个grid cell输出了一个confidence值,比如说confidence=0.7。那就是说,网络告诉你,我认为这个grid cell有物体,且我给出了一个bbox位置信息,你画出来的话跟你图片实际的物体边框重合情况差不多是0.7那意思。
后续就是你自己判断,你觉得confidence>0.5就可以画出来,认可网络预测,那这个时候confidence=0.7了,我就画出来就行了。