概要
当我们想要在具有嵌入式数据库的本地环境中工作时,我们倾向于默认使用 SQLite。虽然大多数情况下这都很好,但这就像骑自行车去 100 公里之外:可能不是最好的选择。
这篇文章中将讨论以下要点:
-
• DuckDB 简介:它是什么、为什么要使用它以及何时使用它
-
• DuckDB 集成到 Python 中
什么是 DuckDB?
如果查看 DuckDB 的网站,在其主页上看到的第一件事就是:DuckDB 是一个进程内 SQL OLAP 数据库管理系统。
让我们尝试解读这句话,因为它包含相关信息。
-
• 进程内 SQL 意味着 DuckDB 的功能在应用程序中运行,而不是在应用程序连接的外部进程中运行。换句话说:没有客户端发送指令,也没有服务器读取和处理它们。与 SQLite 的工作方式相同,而 PostgreSQL、MySQL……则不然。
-
• OLAP 代表在线分析处理,微软将其定义为组织大型业务数据库并支持复杂分析的技术。它可用于执行复杂的分析查询,而不会对事务系统产生负面影响。OLAP 数据库管理系统的另一个示例是 Teradata。
所以基本上,如果寻找无服务器数据分析数据库管理系统,DuckDB 是一个不错的选择。强烈建议查看 Mark Raasveldt 博士和 Hannes Mühleisen 博士 (两位最重要的 DuckDB 开发人员)发表的精彩同行评审论文,以了解 DuckDB 试图填补的空白。
此外它还是一个支持 SQL 的关系数据库管理系统 (DBMS)。这就是为什么我们将它与具有相同特征的其他 DBMS(例如 SQLite 或 PostgreSQL)进行比较。
为什么选择 DuckDB?
知道了 DuckDB 在数据库行业中的作用。但是为什么要选择它而不是针对给定项目可能有的许多其他选项呢?
对于数据库管理系统而言,不存在一刀切的情况,DuckDB 也不例外。我们将介绍它的一些功能,以帮助决定何时使用它。
它是一个高性能工具。正如 GitHub 页面所示:“它的设计目标是快速、可靠且易于使用。”
-
• 它的创建是为了支持分析查询工作负载 (OLAP)。他们的方式是通过向量化查询执行(面向列),而前面提到的其他 DBMS(SQLite、PostgreSQL…)按顺序处理每一行。这就是其性能提高的原因。
-
• DuckDB 采用了 SQLite 的最佳特性:简单性。DuckDB 开发人员在看到 SQLite 的成功后,选择安装简单性和嵌入式进程内操作作为 DBMS。
-
• 此外 DuckDB 没有外部依赖项,也没有需要安装、更新或维护的服务器软件。如前所述,它是完全嵌入式的,这具有与数据库之间进行高速数据传输的额外优势。
-
• 熟练的开创者。他们是一个研究小组,创建它是为了创建一个稳定且成熟的数据库系统。这是通过密集和彻底的测试来完成的,测试套件目前包含数百万个查询,改编自 SQLite、PostgreSQL 和 MonetDB 的测试套件。
-
• 功能完备。支持 SQL 中的复杂查询,提供事务保证( ACID 属性),支持二级索引以加速查询……更重要的是深度集成到 Python 和 R 中,以实现高效的交互式数据分析。
-
• 还提供 C、C++、Java 的 API
-
• 免费和开源
这些都是官方的优势。
还有另外需要再强调一点:DuckDB 不一定是 Pandas 的替代品。它们可以携手合作,如果是 Pandas 粉丝,也可以使用 DuckDB 在 Pandas 上执行高效的 SQL。
什么时候使用DuckDB?
这确实取决于喜好,但让我们回到其联合创始人发布的论文。
他们解释说,显然需要嵌入式分析数据管理。SQLite 是嵌入式的,但如果我们想用它进行详尽的数据分析,它太慢了。他们坚持认为“这种需求来自两个主要来源:交互式数据分析和“边缘”计算。”
以下是 DuckDB 的前 2 个用例:
-
• 交互式数据分析。现在大多数数据专业人员在本地环境中使用 R 或 Python 库(例如 dplyr 或 Pandas)来处理从数据库检索的数据。DuckDB 为我们的本地开发提供了使用 SQL 效率的可能性,而不会影响性能。无需放弃最喜欢的编码语言即可获得这些好处(稍后会详细介绍)。
-
• 边缘计算。使用维基百科的定义“边缘计算是一种分布式计算范式,使计算和数据存储更接近数据源。” 使用嵌入式 DBMS,没有比这更接近的了
DuckDB 可以在不同的环境中安装和使用:Python、R、Java、node.js、Julia、C++…这里,我们将重点关注 Python,很快就会看到它是多么容易使用。
将 DuckDB 与 Python 结合使用(简介)
打开终端并导航到所需的目录,因为我们即将开始。创建一个新的虚拟环境(或不创建)并安装 DuckDB:
pip install duckdb==0.7.1
如果需要另一个版本,请删除或更新该版本。
为了让事情变得更有趣,我将使用我在 Kaggle 上找到的有关 Spotify 有史以来流媒体最多的歌曲的真实数据[6]。我将使用典型的 Jupyter Notebook。由于我们获得的数据是两个 CSV 文件(Features.csv 和 Streams.csv),因此我们需要创建一个新数据库并将它们加载到:
import duckdb
# Create DB (embedded DBMS)
conn = duckdb.connect('spotiStats.duckdb')
c = conn.cursor()
# Create tables by importing the content from the CSVs
c.execute(
"CREATE TABLE features AS SELECT * FROM read_csv_auto('Features.csv');"
)
c.execute(
"CREATE TABLE streams AS SELECT * FROM read_csv_auto('Streams.csv');"
)就像这样,我们创建了一个全新的数据库,添加了两个新表,并用所有数据填充了它们。所有这些都只有 4 行简单的代码(如果我们考虑导入,则为 5 行)。
让我们显示 Streams 表中的内容:
c.sql("SELECT * FROM streams")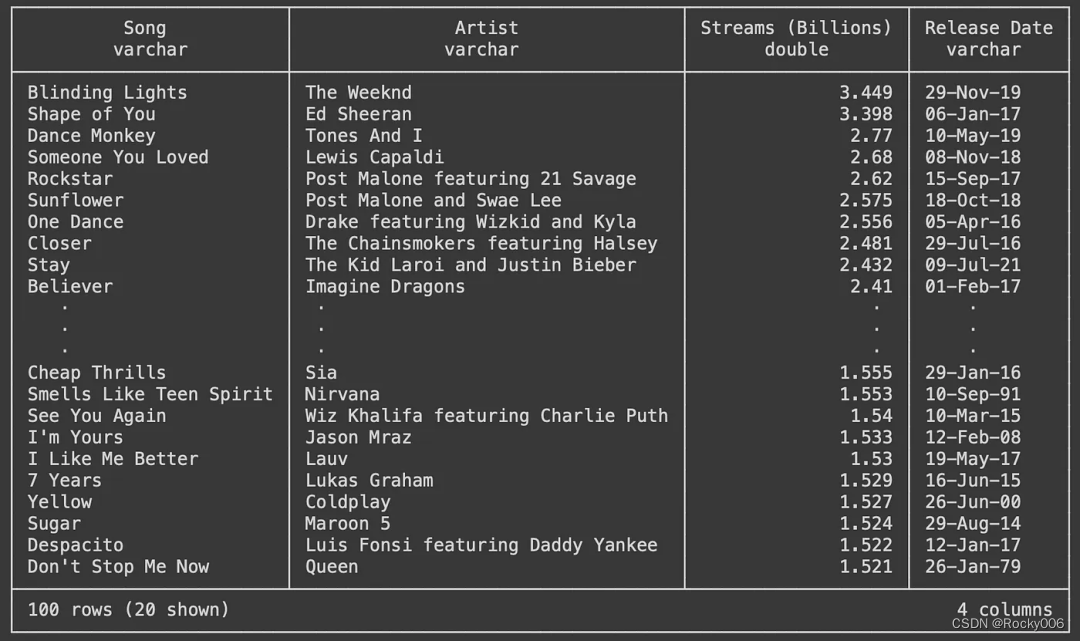
让我们开始做一些分析任务。例如想知道前 100 首中有多少首 2000 年之前的歌曲。这是一种方法:
c.sql('''
SELECT *
FROM streams
WHERE regexp_extract("Release Date", '\d{2}$') > '23'
''')
之前提到过同时使用 DuckDB 和 Pandas 很容易。这是一种使用 Pandas 执行相同操作的方法:
我所做的就是将初始查询转换为 DataFrame,然后以 Pandas 的方式应用过滤器。结果是一样的,但是他们的表现呢?
>>> %timeit df[df['Release Date'].apply(lambda x: x[-2:] > '23')]
434 µs ± 25.6 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
>>> %timeit c.sql('SELECT * FROM streams WHERE regexp_extract("Release Date", \'\d{2}$\') > \'23\'')
112 µs ± 25.3 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)操作相当简单:我们对 100 行表应用一个简单的过滤器。但如果我们将其与 DuckDB 实现进行比较,使用 Pandas 的执行时间几乎是其 4 倍。
如果我们尝试更详尽的分析操作,改进可能是巨大的。
我认为提供更多示例并没有多大意义,因为对 DuckDB 的介绍将转换为 SQL 介绍。这不是我想要的。
我们将最后的结果(2000 首之前的歌曲)导出为 parquet 文件 - 因为它们始终是传统 CSV 的更好替代品。同样这将非常简单:
c.execute('''
COPY (
SELECT
*
FROM
streams
WHERE
regexp_extract("Release Date", '\d{2}$') > '23'
)
TO 'old_songs.parquet' (FORMAT PARQUET);
''')我所做的就是将之前的查询放在括号内,DuckDB 只是将查询的结果复制到 old_songs.parquet 文件中。
结论
DuckDB 改变了进程内分析领域,这种影响还将继续。
今天的分享就到这里,欢迎点赞收藏转发,感谢🙏