1. 解决了什么问题?
密集目标检测器会预测出大量的候选检测框,如何准确地对它们进行排序是取得优异性能的关键。以前的方法通常会在 NMS 时根据类别得分对预测框做排序,但这可能损害模型表现,因为类别得分并不能体现边框定位的准确性,定位准确的边框可能会因为类别得分较低而被 NMS 错误地去除。
现有的一些方法会预测一个额外的 IoU 得分或 center-ness 得分,表示定位质量。然后在 NMS 排序时将它们乘上分类得分。这些方法能减轻目标定位准确率和分类得分不对齐的问题,但并不是最优的方案,因为一旦这两项预测值都不准确,那么排序也就会有问题。此外,增加一个分支来预测定位质量得分也不简洁,增加计算成本。
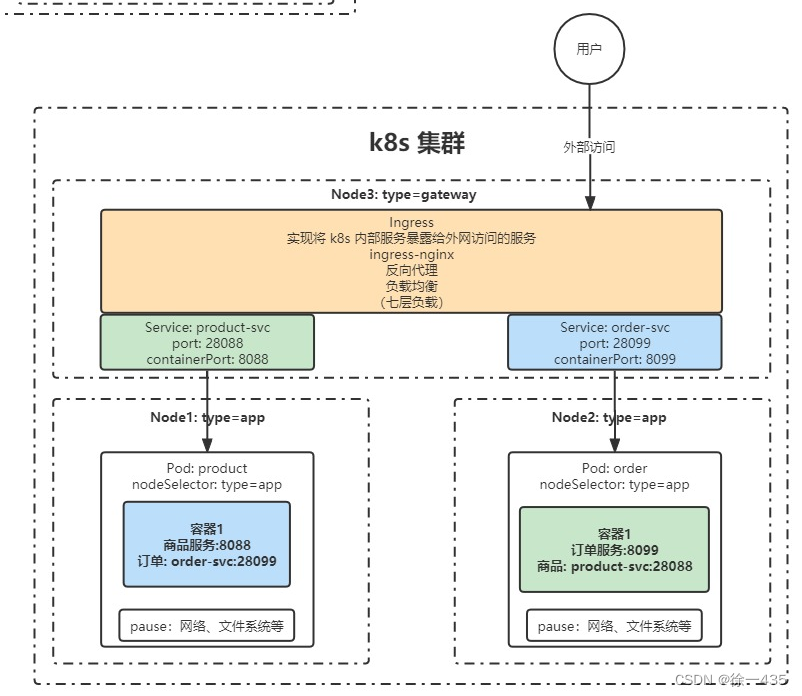
FCOS 的 neck 使用了 FPN,head 包含三个分支。一个分支预测特征图上每个点的分类得分,一个回归该点到边框四条边的距离,另一个则预测 center-ness 得分,在 NMS 排序时将 center-ness 得分与分类得分相乘。下图即 FCOS head 的输出。

作者对 FCOS+ATSS 做了消融实验,分析该算法性能的上界。在 NMS 前,将预测的前景点的分类得分、距离偏移量、center-ness 得分替换为相应的 ground-truth 值,然后在 COCO val2017 上评测其 AP 表现。对于分类得分向量,有两个选择,要么将 ground-truth 标签位置的值替换为 1.0,要么替换为预测框和 ground-truth 框的 IoU(gt_IoU)。
从下表可以看到,FCOS+ATSS 取得了 39.2 AP,推理时使用 ground-truth center-ness 得分(gt_ctr)只能提升 2.0 AP。将预测的 center-ness 得分替换为 gt_IoU(gt_ctr_iou) 也只取得了 43.5 AP。这表明对检测框排序时,分类得分无论是乘以预测的 center-ness 得分,还是乘以 IoU 得分都无法显著提升模型表现。
然而即便不使用 center-ness 得分,FCOS+ATSS 通过 ground-truth bbox(gt_bbox) 也能取得 56.1 AP。如果将 ground-truth 标签位置的分类得分替换为 1.0(gt_cls),用不用 center-ness 得分就变得关键了(43.1 AP vs. 58.1 AP),因为 center-ness 得分能够区分出边框是否准确。
将 ground-truth 类别的分类得分替换为 gt_IoU(gt_cls_iou) 结果最为惊艳。不加 center-ness 得分就能取得 74.7 AP。这说明在众多的候选目标里面,已经存在定位准确的边框。将 ground-truth 类的分类得分替换为 gt_IoU 效果最佳,这个分数向量就叫做 IACS。

2. 提出了什么方法?
- 提出了 IoU-aware 分类得分(IACS)作为某一目标类别存在的置信度和预测框定位质量的联合表征。
- 受 Focal Loss 启发,设计了 Varifocal Loss。它是一个动态缩放的二元交叉熵损失,采用非对称的训练样本加权方法,回归出连续的 IACS。它降低负样本的权重,以解决正负类别不均衡问题,同时增加高质量正样本的权重,以输出最佳的预测结果。
- 提出了一个 star-shaped 边框特征表征,用于 IACS 预测和边框优化。通过可变形卷积,它使用九个固定的采样点来表示一个边框,从而获取边框的几何信息及周围的语义信息。
2.1 IACS
IACS 是分类得分向量里的一个标量元素,ground-truth 类索引位置的值是预测框与目标框之间的 IoU,其它索引位置都为 0。
2.2 Varifocal Loss
作者设计了 Varifocal Loss 训练密集检测器,以预测 IACS。
Focal Loss 用于解决密集目标检测器训练过程中遇到的前背景类别不均衡问题。定义如下:
FL(p,y)
=
{
−
α
(
1
−
p
)
γ
log
(
p
)
,
if
y
=
1
−
(
1
−
α
)
p
γ
log
(
1
−
p
)
,
otherwise
\text{FL(p,y)}=\left\{ \begin{array}{ll} -\alpha (1-p)^\gamma \log(p), \quad \quad \text{if} \quad y=1 \\ -(1-\alpha)p^\gamma \log(1-p)\quad, \quad \text{otherwise} \end{array} \right.
FL(p,y)={−α(1−p)γlog(p),ify=1−(1−α)pγlog(1−p),otherwise
其中 y ∈ { ± 1 } y\in \left\{\pm1\right\} y∈{±1}表示 ground-truth 类别, p ∈ [ 0 , 1 ] p\in[0,1] p∈[0,1]是前景类的预测概率。如上式,前景类的调节系数 ( 1 − p ) γ (1-p)^\gamma (1−p)γ和背景类的 p γ p^\gamma pγ能降低容易样本的损失贡献,提高错误分类样本的重要性。Focal Loss 能防止容易负样本占据模型训练,更加关注于少量的难例样本。
作者借鉴了 Focal Loss 的加权思想,解决类别不均衡问题。它以非对称的方式解决正负样本不均衡问题。Varifocal Loss 基于二元交叉熵损失而来:
VFL(p,q)
=
{
−
q
[
q
⋅
log
(
p
)
+
(
1
−
q
)
⋅
log
(
1
−
p
)
]
,
q
>
0
−
α
⋅
p
γ
⋅
log
(
1
−
p
)
,
q
=
0
\text{VFL(p,q)}=\left\{ \begin{array}{ll} -q\left[q\cdot\log(p)+(1-q)\cdot\log(1-p)\right], \quad \quad q>0 \\ -\alpha\cdot p^\gamma\cdot \log(1-p), \quad \quad \quad \quad \quad \quad \quad \quad q=0 \end{array} \right.
VFL(p,q)={−q[q⋅log(p)+(1−q)⋅log(1−p)],q>0−α⋅pγ⋅log(1−p),q=0
p p p是预测的 IACS, q q q是目标得分。如下图所示,对于一个前景点,ground-truth 类的 q q q定义为预测框和目标框之间的 IoU,其余为 0,而背景点所有类别的目标 q q q则都是 0。
Varifocal Loss 通过
p
γ
p^\gamma
pγ调节损失大小,只降低负样本(
q
=
0
q=0
q=0)的损失贡献,不会降低正样本(
q
>
0
q>0
q>0)的贡献。这是因为正样本非常稀少,应当保留它们的学习信号。用训练目标
q
q
q对正样本做加权,如果一个正样本有较高的 gt_IoU,它对损失的贡献就相对要大一些。这样就更加关注于训练高质量正样本,它们对取得较高的 AP 更重要。为了平衡正负样本,作者在
q
=
0
q=0
q=0的损失项加入了一个可调节的缩放系数
α
\alpha
α。

2.3 Star-Shaped Box Feature Representation
为了预测 IACS,作者设计了一个星形的边框特征表征。通过可变形卷积,它用九个固定采样点(上图的黄圈)的特征来表示一个边框。该表征能获取边框的几何信息和邻近的语义信息。
给定图像平面的一个采样点 ( x , y ) (x,y) (x,y),首先用 3 × 3 3\times 3 3×3卷积回归出初始边框。它用一个 4D 向量 ( l ′ , t ′ , r ′ , b ′ ) (l',t',r',b') (l′,t′,r′,b′)表示 ( x , y ) (x,y) (x,y)到初始边框四条边的距离。然后就可以选择九个采样点: ( x , y ) (x,y) (x,y), ( x − l ′ , y ) (x-l',y) (x−l′,y), ( x , y − t ′ ) (x,y-t') (x,y−t′), ( x + r ′ , y ) (x+r',y) (x+r′,y), ( x , y + b ′ ) (x,y+b') (x,y+b′), ( x − l ′ , y − t ′ ) (x-l',y-t') (x−l′,y−t′), ( x + l ′ , y − t ′ ) (x+l',y-t') (x+l′,y−t′), ( x − l ′ , y + b ′ ) (x-l',y+b') (x−l′,y+b′), ( x + r ′ , y + b ′ ) . (x+r',y+b'). (x+r′,y+b′). 然后将它们映射到特征图上。它们到 ( x , y ) (x,y) (x,y)的映射点的相对偏移量作为可变形卷积的偏移量使用,用可变形卷积对这九个映射点的特征做卷积,以表示一个边框。
2.4 Bounding Box Refinement
通过边框优化步骤进一步提升目标检测的准确率。边框优化在目标检测中常用,但由于密集目标检测器缺乏一个高效的、判别性强的目标表征,就很少用于密集目标检测方法。现在有了星形表征,就可以在密集目标检测中使用它了。
将边框优化建模为一个残差学习问题。对于初始边框回归量 ( l ′ , t ′ , r ′ , b ′ ) (l',t',r',b') (l′,t′,r′,b′),首先提取其星形表征。然后基于该表征,学习四个距离缩放系数 ( Δ l , Δ t , Δ r , Δ b ) (\Delta l,\Delta t, \Delta r,\Delta b) (Δl,Δt,Δr,Δb)对初始距离向量做缩放,这样优化后的边框就更接近于 ground-truth,记为 ( l , t , r , b ) = ( Δ l × l ′ , Δ t × t ′ , Δ r × r ′ , Δ b × b ′ ) (l,t,r,b)=(\Delta l\times l',\Delta t \times t', \Delta r\times r',\Delta b\times b') (l,t,r,b)=(Δl×l′,Δt×t′,Δr×r′,Δb×b′)。
2.5 VarifocalNet
将上面三块改进加入到 FCOS,并去除原来的 center-ness 分支,就得到了 VarifocalNet。VFNet 的主干和 FPN 网络部分与 FCOS 一样,head 结构不同。
VFNet 的 head 有两个子网络。定位子网络完成边框回归及优化。其输入是 FPN 每一层的特征图,先经过三个 3 × 3 3\times 3 3×3卷积及 ReLU 激活。输出特征图有 256 个通道。定位子网络的一条分支对特征图做卷积,为每个空间位置都输出一个 4D 距离向量 ( l ′ , t ′ , r ′ , b ′ ) (l',t',r',b') (l′,t′,r′,b′)以表示初始边框。有了初始边框和特征图,另一分支对九个特征采样点使用星形的可变形卷积,输出距离缩放系数 ( Δ l , Δ t , Δ r , Δ b ) (\Delta l,\Delta t, \Delta r,\Delta b) (Δl,Δt,Δr,Δb),然后与初始距离向量相乘,得到优化后的边框 ( l , t , r , b ) (l,t,r,b) (l,t,r,b)。
另一子网络输出 IACS,该子网络与定位子网络的优化分支结构相似,除了它为每个空间位置都输出一个
C
C
C维向量,每个元素都代表着目标类别的概率及定位准确率。

2.6 损失函数及推理
Loss
=
1
N
p
o
s
∑
i
∑
c
VFL
(
p
c
,
i
,
q
c
,
i
)
+
λ
0
N
p
o
s
∑
i
q
c
∗
,
i
L
b
b
o
x
(
b
b
o
x
i
′
,
b
b
o
x
i
∗
)
+
λ
1
N
p
o
s
∑
i
q
c
∗
,
i
L
b
b
o
x
(
b
b
o
x
i
,
b
b
o
x
i
∗
)
\begin{align} \text{Loss}=&\frac{1}{N_{pos}}\sum_i \sum_c \text{VFL}(p_{c,i}, q_{c,i})\nonumber\\ +&\frac{\lambda_0}{N_{pos}}\sum_i q_{c^*,i}\text{L}_{bbox}(bbox_i', bbox_i^*)\nonumber\\ +&\frac{\lambda_1}{N_{pos}}\sum_i q_{c^*,i}\text{L}_{bbox}(bbox_i, bbox_i^*)\nonumber \end{align}
Loss=++Npos1i∑c∑VFL(pc,i,qc,i)Nposλ0i∑qc∗,iLbbox(bboxi′,bboxi∗)Nposλ1i∑qc∗,iLbbox(bboxi,bboxi∗)
p
c
,
i
p_{c,i}
pc,i和
q
c
,
i
q_{c,i}
qc,i表示 FPN 每层特征图位置
i
i
i处类别
c
c
c的预测 IACS 和真实 IACS。
L
b
b
o
x
L_{bbox}
Lbbox是
GIoU
\text{GIoU}
GIoU损失,
b
b
o
x
i
′
,
b
b
o
x
i
,
b
b
o
x
i
∗
bbox_i', bbox_i, bbox_i^*
bboxi′,bboxi,bboxi∗分别是初始边框、优化后边框和 ground-truth 边框。用训练目标
q
c
∗
,
i
q_{c^*,i}
qc∗,i对
L
b
b
o
x
L_{bbox}
Lbbox加权,对于前景点,
q
c
∗
,
i
q_{c^*,i}
qc∗,i是 gt_IoU;对于背景点,
q
c
∗
,
i
q_{c^*,i}
qc∗,i就是 0。
λ
0
,
λ
1
\lambda_0, \lambda_1
λ0,λ1用于平衡
L
b
b
o
x
L_{bbox}
Lbbox的权重,分别设为 1.5 和 2.0。
N
p
o
s
N_{pos}
Npos是前景点的个数,归一化总损失。
VFNet 的推理很直接,输入图像经过网络后用 NMS 后处理去除冗余的预测框。