URL编码
当 URL 路径或者查询参数中,带有中文或者特殊字符的时候,就需要对 URL 进行编码(采用十六进制编码格式)。URL 编码的原则是使用安全字符去表示那些不安全的字符。
安全字符,指的是没有特殊用途或者特殊意义的字符。
URL 是“统一资源定位符”(Uniform Resource Locator)的首字母缩写,中文译为“网址”,表示各种资源的互联网地址。下面就是一个典型的 URL。
组成部分:协议、主机、端口、路径、查询参数、锚点等。
示例如下
http://www.ccc.net/index?param=10路径和查询字符串之间使用问号?隔开。上述示例的域名为 www.ccc.net,路径为 index,查询字符串为 param=1。
URL 中规定了一些具有特殊意义的字符,常被用来分隔两个不同的 URL 组件,这些字符被称为保留字符。例如:
冒号:用于分隔协议和主机组件,斜杠用于分隔主机和路径
?:用于分隔路径和查询参数等。
=用于表示查询参数中的键值对。
&符号用于分隔查询多个键值对。
其余常用的保留字符有:/ . … # @ $ + ; %
URL 字符转义的方法是,在这些字符的十六进制 ASCII 码前面加上百分号(%)。下面是这18个字符及其转义形式。
-
!:%21 -
#:%23 -
$:%24 -
&:%26 -
':%27 -
(:%28 -
):%29 -
*:%2A -
+:%2B -
,:%2C -
/:%2F -
::%3A -
;:%3B -
=:%3D -
?:%3F -
@:%40 -
[:%5B -
]:%5D
Unicode编码
Unicode 是容纳世界所有文字符号的国际标准编码,使用四个字节为每个字符编码。
UTF 是英文 Unicode Transformation Format 的缩写,意为把 Unicode 字符转换为某种格式。UTF 系列编码方案(UTF-8、UTF-16、UTF-32)均是由 Unicode 编码方案衍变而来,以适应不同的数据存储或传递,它们都可以完全表示 Unicode 标准中的所有字符。目前,这些衍变方案中 UTF-8 被广泛使用,而 UTF-16 和 UTF-32 则很少被使用。
UTF-8 使用一至四个字节为每个字符编码,其中大部分汉字采用三个字节编码,少量不常用汉字采用四个字节编码。因为 UTF-8 是可变长度的编码方式,相对于 Unicode 编码可以减少存储占用的空间,所以被广泛使用。
UTF-16 使用二或四个字节为每个字符编码,其中大部分汉字采用两个字节编码,少量不常用汉字采用四个字节编码。UTF-16 编码有大尾序和小尾序之别,即 UTF-16BE 和 UTF-16LE,在编码前会放置一个 U+FEFF 或 U+FFFE(UTF-16BE 以 FEFF 代表,UTF-16LE 以 FFFE 代表),其中 U+FEFF 字符在 Unicode 中代表的意义是 ZERO WIDTH NO-BREAK SPACE,顾名思义,它是个没有宽度也没有断字的空白。

ASCII码
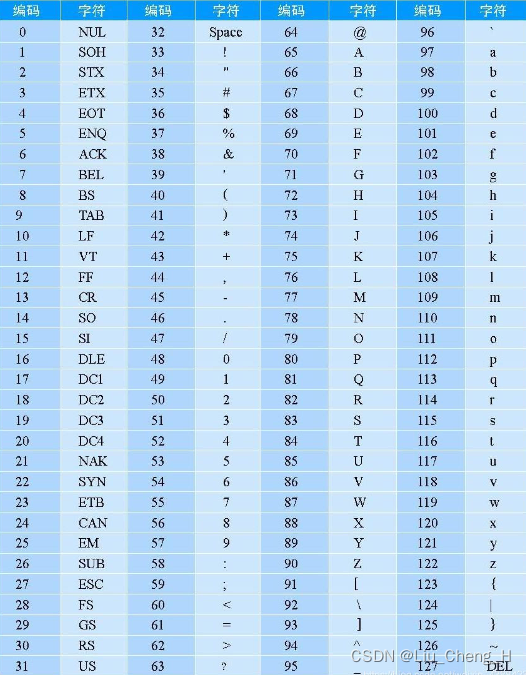
标准ASCII 码也叫基础ASCII码,使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号,以及在美式英语中使用的特殊控制字符 。
其中:
0~31及127(共33个)是控制字符或通信专用字符(其余为可显示字符),如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(响铃)等;通信专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等;ASCII值为8、9、10 和13 分别转换为退格、制表、换行和回车字符。它们并没有特定的图形显示,但会依不同的应用程序,而对文本显示有不同的影响 。
32~126(共95个)是字符(32是空格),
其中:
48~57为0到9十个阿拉伯数字。
65~90为26个大写英文字母,
97~122为26个小写英文字母,
其余为一些标点符号、运算符号等。
ASCII码表
![[RabbitMQ] RabbitMQ简单概述,用法和交换机模型](https://img-blog.csdnimg.cn/6a9a8f99962c454dbad8e7b136a0cb1e.png#pic_center)