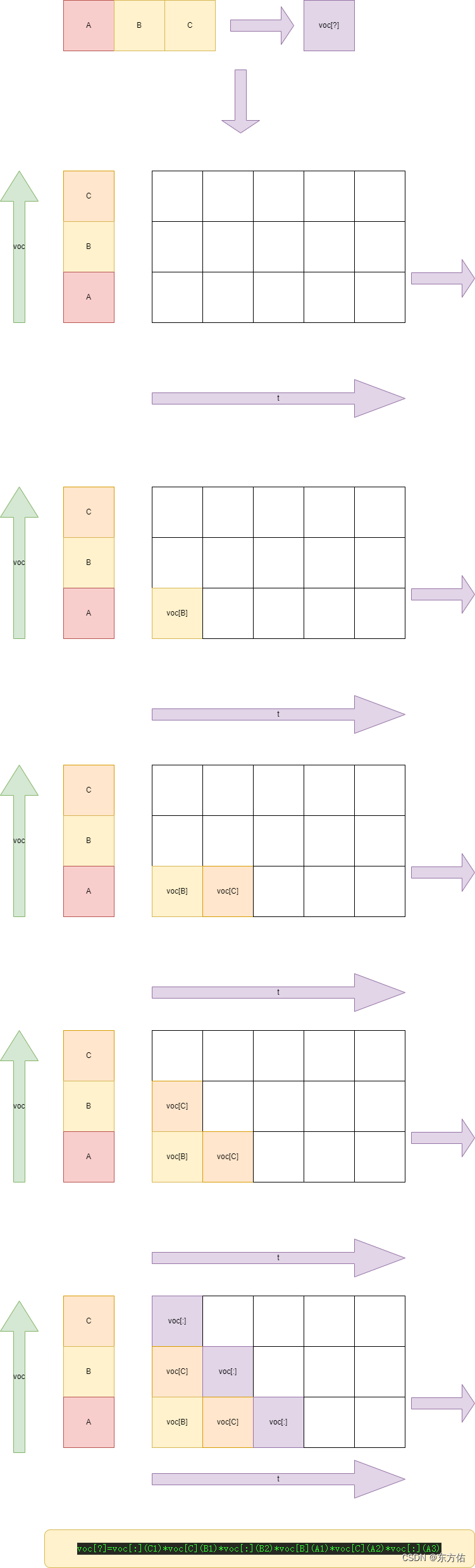
例如 ABCD
生成A01B B01C A02C A03D。。。。。。。。。
from multiprocessing import Process, Manager, freeze_support
def gen_data(i,d,d_list,data):
for j,dj in enumerate(data[i+1:]):
# print(d,str(j+1).zfill(15),dj)
d_list.append([d,str(j+1),dj])
if __name__ == '__main__':
freeze_support()
with open("3.txt", "r", encoding="utf-8") as f:
data = f.read()
data = list("".join(data.replace("\n", "").split()))
with open("5.txt", "r", encoding="utf-8") as f:
data1 = f.read()
data1 = list("".join(data1.replace("\n", "").split()))
data += data1
d_list = Manager().list()
p_list=[]
for i, d in enumerate(data[:-1]):
print(i)
p=Process(target=gen_data, args=(i,d,d_list,data))
p_list.append(p)
# 达到cpu 核心数开启
if len(p_list)>=8:
for p in p_list:
p.start()
for p in p_list:
p.join()
p_list=[]
加速版
from multiprocessing import Process, Manager, freeze_support
import pandas as pd
from tqdm import tqdm
def gen_data(d_list,data):
pdf = pd.DataFrame({"voc": list(data.strip())})
pdf["voc_id"] = pdf.index.values
for i in tqdm(range(0, pdf.shape[0] - 1)):
first_str = pdf.loc[(pdf["voc_id"] - i) == 0, "voc"].tolist()[0]
second_str = pdf.loc[(pdf["voc_id"] - i) > 0, "voc_id"].tolist()
thrift_str = pdf.loc[(pdf["voc_id"] - i) > 0, "voc"].tolist()
new_df = pd.DataFrame({"voc": [first_str] * len(second_str), "voc_id": second_str, "label": thrift_str})
new_df["voc_id"] = new_df["voc_id"].astype("str").str.zfill(3)
res = (new_df["voc"] + new_df["voc_id"].astype("str") + new_df["label"]).values.tolist()
d_list += res
if __name__ == '__main__':
freeze_support()
with open("poetrySong.txt", "r", encoding="utf-8") as f:
total_data = f.readlines()
d_list = Manager().list()
p_list = []
for data in tqdm(total_data):
p=Process(target=gen_data, args=(d_list,data))
p_list.append(p)
# 达到cpu 核心数开启
if len(p_list)>=8:
for p in p_list:
p.start()
for p in p_list:
p.join()
p_list=[]
pd.to_pickle({"data":list(d_list)},"data_set")
该代码使用了多进程(multiprocessing)库来并行处理文本数据。代码中使用了Process类创建进程,并使用Manager类的list()方法创建了一个可以在多个进程间共享的列表d_list。然后,通过调用gen_data函数并传入d_list和data参数来生成数据。gen_data函数中首先将传入的data字符串转换为DataFrame对象。然后,使用一个for循环遍历DataFrame中的每个元素,将元素拼接成一个新的字符串,并将其添加到d_list中。最后,将生成的数据集保存到data_set.pkl文件中。
在主程序中,首先使用open函数打开名为poetrySong.txt的文本文件,并读取其中的所有行,保存到total_data列表中。然后,创建一个空的进程列表p_list,并使用一个for循环遍历total_data中的每个元素。在每次迭代中,创建一个新的进程并将其添加到p_list中。当p_list中的进程数量达到8时,使用两个嵌套的for循环分别启动和等待p_list中的每个进程,并将p_list重置为空列表。例如,如果total_data具有1000个元素,则将创建1000个进程来生成数据。
最后,将生成的数据集保存为data_set.pkl文件,以便后续使用。
推理
import pandas as pd
from tqdm import tqdm
import numpy as np
one = pd.read_pickle("data_set")
one = pd.DataFrame(one)
one_data = one.groupby("data")["data"].count()
new_table = pd.DataFrame({"voc_t_voc": one_data.index.values, "count": one_data.values})
print()
#
inp_list = []
inp = "人言性"
# 由于是比较大小前面已经确定的概率且在大小维度上是确定的故而不会对大小产生影响
# for i,p in enumerate(inp):
# for j in range(i+1,len(inp)+1):
# if j >len(inp)-1:
# idp = p + "{}".format(j).zfill(3)
# inp_list.append(new_table[new_table["voc_t_voc"].str.contains(idp)])
# else:
#
# idp=p+"{}".format(j).zfill(3)+inp[j]
# inp_list.append(new_table[new_table["voc_t_voc"] == idp])
# print()
for _ in range(22):
for i, p in enumerate(inp):
idp = p + "{}".format(len(inp)).zfill(3)
inp_list.append(new_table[new_table["voc_t_voc"].str.contains(idp)])
res_dict = pd.concat(inp_list)
res_dict["res"] = res_dict["voc_t_voc"].str[1:]
res = res_dict.groupby("res", as_index=False)["count"].count()
# 最大法
# res=res.loc[res["count"]==res["count"].max(),"res"].values.tolist()[0][-1:]
# 随机top法
res = np.random.choice(res.loc[res["count"] > res["count"].max() - 2, "res"].str[-1:].tolist())
inp += res
print(inp)
等长统计
from multiprocessing import Process, Manager, freeze_support
import pandas as pd
from tqdm import tqdm
def gen_data(d_list,data):
pdf = pd.DataFrame({"voc": list(data.strip())})
pdf["voc_id"] = pdf.index.values
for i in range(0, pdf.shape[0] - 1):
first_str = pdf.loc[(pdf["voc_id"] - i) == 0, "voc"].tolist()[0]
second_str = pdf.loc[(pdf["voc_id"] - i) > 0, "voc_id"].tolist()
thrift_str = pdf.loc[(pdf["voc_id"] - i) > 0, "voc"].tolist()
new_df = pd.DataFrame({"voc": [first_str] * len(second_str), "voc_id": second_str, "label": thrift_str})
new_df["voc_id"] = new_df["voc_id"].astype("str").str.zfill(3)
res = (new_df["voc"] + new_df["voc_id"].astype("str") + new_df["label"]).values.tolist()
d_list += res
if __name__ == '__main__':
freeze_support()
# with open("poetrySong.txt", "r", encoding="utf-8") as f:
# total_data = f.readlines()
# total_data=[i for i in total_data if len(i) < 30]
with open("poetrySong.txt", "r", encoding="utf-8") as f:
data1 = f.readlines()
# c=[len(i.strip().split("::")[-1]) for i in data1]
# x={j: c.count(j) for j in
# set(c)}
total_data= [i.strip().split("::")[-1] for i in data1 if len(i.strip().split("::")[-1]) == 24]
d_list = Manager().list()
p_list = []
for data in tqdm(total_data):
p=Process(target=gen_data, args=(d_list,data))
p_list.append(p)
# 达到cpu 核心数开启
if len(p_list)>=8:
for p in p_list:
p.start()
for p in p_list:
p.join()
p_list=[]
pd.to_pickle({"data":list(d_list)},"data_set")