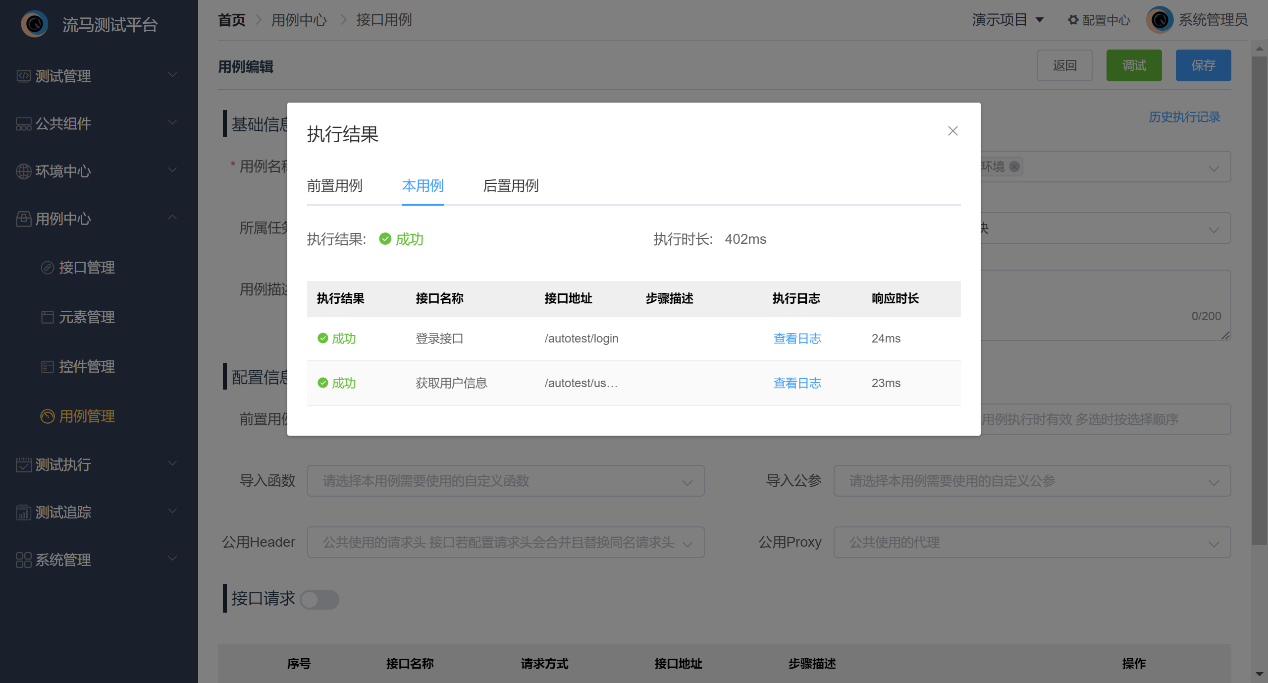
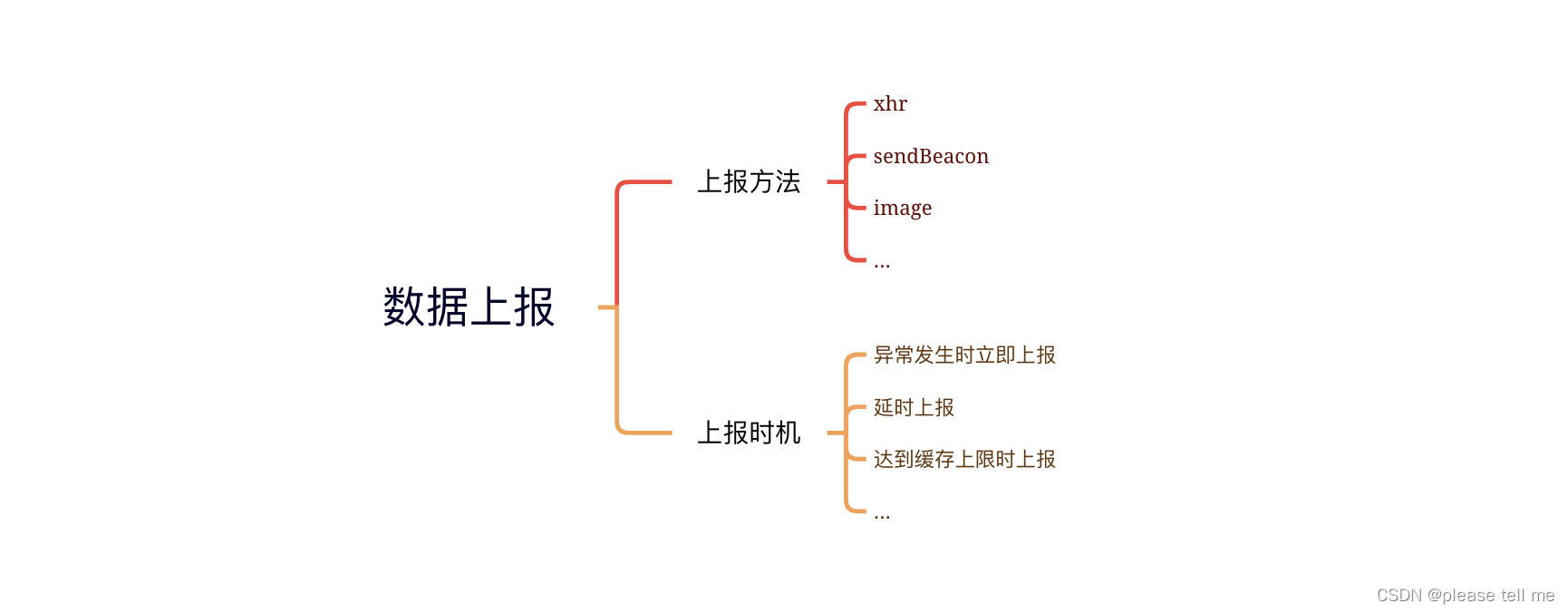
html实体编码
HTML实体编码,格式 以&符号开头,以;分号结尾的
HTML 中的预留字符必须被替换为字符实体
在 HTML 中不能使用小于号(<)和大于号(>),这是因为浏览器会误认为它们是标签。(<:< >:>)
HTML 中的常用字符实体是不间断空格( )。浏览器总是会截短 HTML 页面中的空格。如果您在文本中写 10 个空格,在显示该页面之前,浏览器会删除它们中的 9 个。如需在页面中增加空格的数量,则需要使用 字符实体。
unicode编码,UTF-8
UTF-8 编码是 Unicode 字符集的一种表达方式。每个字符有一个 Unicode 号码,称为码点。如果知道码点,就能查到这是什么字符。字符的码点表示法是&#N;(十进制,N代表码点)或者&#xN;(十六进制,N代表码点),比如,字符a可以写成a(十进制)或者a(十六进制),字符中可以写成中(十进制)或者中(十六进制),浏览器会自动转换它们。
Unicode字符编码,格式: 以符号&#开头,分号;结尾
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码

跟据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
url字符
URL 编码将字符转换为可通过因特网传输的格式。
URL 只能使用 ASCII 字符集 通过因特网进行发送。
26个英文字母(大小写),10个阿拉伯数字,连词号(-),句点(.),下划线(_)
由于 URL 通常包含 ASCII 集之外的字符,因此必须将 URL 转换为有效的 ASCII 格式。
URL 字符转义的方法是,在这些字符的十六进制 ASCII 码前面加上百分号(%)。
URL 不能包含空格。URL 编码通常使用加号(+)或 %20 替代空格。
php中get与post区别
1. get是从服务器上获取数据,post是向服务器传送数据。
2. get是把参数数据队列加到提交表单的ACTION属性所指的URL中,值和表单内各个字段一一对应,在URL中可以看到。post是通过HTTP post机制,将表单内各个字段与其内容放置在HTML HEADER内一起传送到ACTION属性所指的URL地址。用户看不到这个过程。
3. 对于get方式,服务器端用Request.QueryString获取变量的值,对于post方式,服务器端用Request.Form获取提交的数据。
4. get传送的数据量较小,不能大于2KB。post传送的数据量较大,一般被默认为不受限制。但理论上,IIS4中最大量为80KB,IIS5中为100KB。
5. get安全性非常低,post安全性较高。但是执行效率却比Post方法好。