才识是岁月的冠冕,正如思念是我们共同的时光。
- 【Neo4j × Python】基于知识图谱的电影问答系统(含问题记录与解决)附:源代码(含Bug解决)
- 【Neo4j × 知识图谱】图形化数据库基本操作: 创建节点与关系、添加属性、查询节点 | 附:可视化 构建四大名著 知识图谱(含源代码)| word2vec实战: 构造斗罗大陆人物关系

🎯作者主页: 追光者♂🔥
🌸个人简介:
💖[1] 计算机专业硕士研究生💖
🌟[2] 2022年度博客之星人工智能领域TOP4🌟
🏅[3] 阿里云社区特邀专家博主🏅
🏆[4] CSDN-人工智能领域优质创作者🏆
📝[5] 预期2023年10月份 · 准CSDN博客专家📝
- 无限进步,一起追光!!!
🍎感谢大家 点赞👍 收藏⭐ 留言📝!!!
附:
- Python内置函数系统学习(1)——数据转换与计算(详细语法参考 + 参数说明 + 具体示例)
🌿本篇,继续分享Python中的内置函数,我们将详细学习max的使用:具体在列表、元组、字典中的使用以及详细案例。这属于基础内容,但是对于机器学习来说,在理解后续复杂计算以及相关函数的操作至关重要,所以,一起学习吧!
👀目录
- 🍄一、在列表中使用max
- 🍑1.1 示例1:赛车车手 积分比较
- 🍑1.2 示例2:汽车销量
- 🍑1.3 NBA球员
- 🍑1.4 学生考试成绩列表
- 🍄二、在元组中使用max
- 🍑2.1 示例1:求 数字元组 最大值
- 🍑2.2 示例2:月份、星期元组
- 🍑2.3 示例3:NBA球队成绩元组
- 🍑2.4 示例4:电影上映时间元组
- 🍑2.5 示例5:元组 & 元组
- 🍄三、在字典中使用max
- 🍑3.1 示例1:会员信息字典 字典 max操作
- 🍑3.2 示例2:列表 & 字典(按照条件取最大值)
- 🍑3.3 示例3:字典 姓名&年份 按条件取最大值
- 🍑3.4 示例4:zip()函数的使用
- 🍄四、应用场景
- 🍑4.1 场景一:歌咏比赛歌手分数计算程序
- 🍑4.2 场景二:根据输入参数输出该参数最大值的产品信息
- 🍑4.3 场景三:获得当前内存的使用最大值
注:目录一 续16个必会的Python内置函数(2)——数据转换与计算(详细语法参考 + 参数说明 + 具体示例)中的“在列表中使用max”:
🍄一、在列表中使用max
🍑1.1 示例1:赛车车手 积分比较
# 创建F1赛车 车手 积分列表,积分在后,练习对列表中 数据不同位置元素求最大值
listch1 = ['来棵妮 347', '寒迷而吨 469', '未太贰 305', '位嘶答翻 327', '播他嘶 339']
# 创建F1赛车 车手积分列表,积分在前
listch2 = ['347 来棵妮', '469 寒迷而吨', '305 未太贰', '327 位嘶答翻', '339 播他嘶']
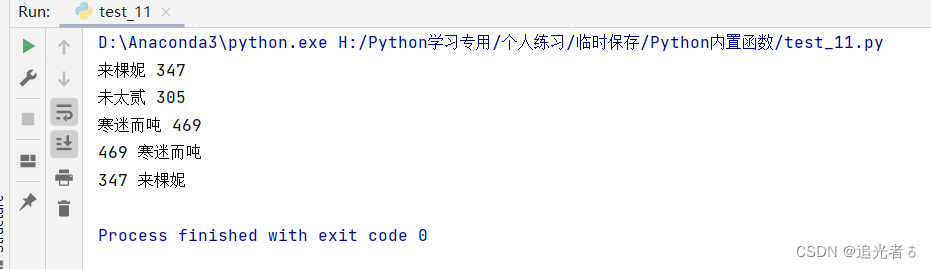
print(max(listch1)) # 来棵妮 347
print(max(listch1[-3:-1])) # 未太贰 305 在倒数第三个列表和倒数第二个列表查找最大值
print(max(listch1, key=lambda x: x[-3:])) # 寒迷而吨 469 获取每个列表的倒数3个元素的最大值,即比较积分
print(max(listch2)) # 469 寒迷而吨
# 取每个列表的第4项到最后一项的数据 比较 获得最大值,即获取姓名的最大值
print(max(listch2,key=lambda x:(x[4:]))) # 347 来棵妮
🍑1.2 示例2:汽车销量
# 注:均为虚拟,模拟使用,非真实~
# 创建汽车销量2维列表,内层列表中包含汽车销量和汽车名称
listcar = [[123, '奥迪'], [45658, '特斯拉'], [78956, '比亚迪'], [546325, '奔驰'], [256325, '宝马'], [25698, '上海大众']]
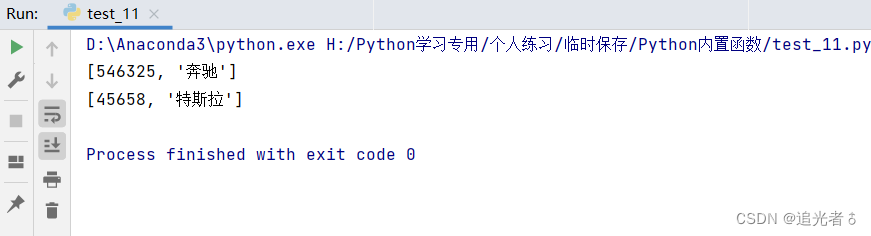
print(max(listcar)) # [546325, '奔驰'] 输出列表listcar的最大值
# 按照列表listcar的第2项(车名)进行迭代取最大值
print(max(listcar, key=lambda x: x[1])) # [45658, '特斯拉']
此外,还有类似示例,与上面近似。
🍑1.3 NBA球员
# 创建NBA球员数据嵌套列表,嵌套列表中包含球员名称、出场场次、出场时间和平均得分
listnba = [['哈登', 78, 36.8, 36.1], ['乔治', 77, 36.9, 28.0], ['阿德托昆博', 72, 32.8, 27.7], ['恩比德', 64, 33.7, 27.5],
['詹姆斯', 55, 35.2, 27.4], ['库里', 69, 33.8, 27.3]]
print(max(listnba)) # 输出列表listnba的最大值
print(max(listnba, key=lambda x: x[3])) # 按照列表的第4项,即球员的场平均分迭代取最大值
print(max(listnba, key=lambda x: (x[2], x[1], x[3]))) # 按照第3项出场时间迭代取最大值
print(max(listnba, key=lambda x: x[3] * x[1])) # 按球员平均得分和比赛场次的乘积(即总得分)迭代求最大值
print(max(listnba, key=lambda x: (str(x[3]))[1:])) # 按平均分的后3位迭代求最大值
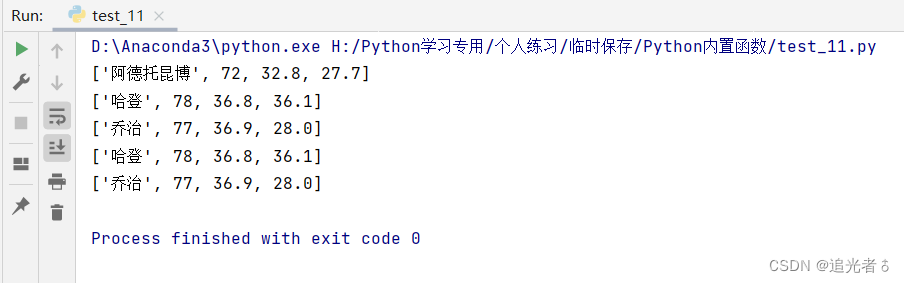
🍑1.4 学生考试成绩列表
# 创建学生考试成绩嵌套列表,嵌套列表包含考试名次、语文成绩、数学成绩、理综成绩、英语成绩。
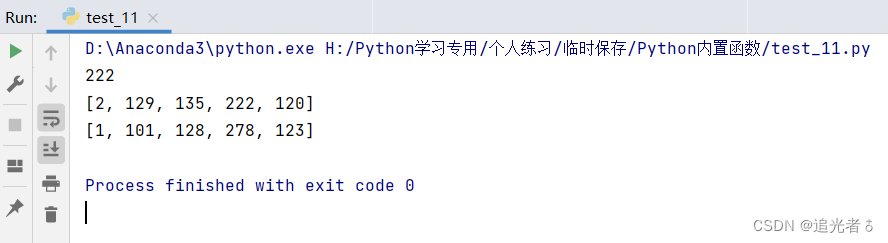
liststud = [[1, 101, 128, 278, 123], [2, 129, 135, 222, 120], [3, 127, 138, 227, 107], [4, 98, 135, 217, 108],
[5, 123, 101, 201, 101], [6, 89, 125, 197, 90]]
print(max(liststud[1])) # 输出为:222 取第2个列表中元素的最大值
print(max(liststud, key=lambda x: x[1])) # 输出为:[2, 129, 135, 222, 120] 按照每个列表第2项迭代
print(max(liststud, key=lambda x: x[1] + x[2] + x[3] + x[4])) # 按每个列表元素的第2项到第5项的和迭代取最大值
🍄二、在元组中使用max
在元组中获取元素的最大值和列表相似,常用应用代码归纳如下:
🍑2.1 示例1:求 数字元组 最大值
# 在元组中使用max
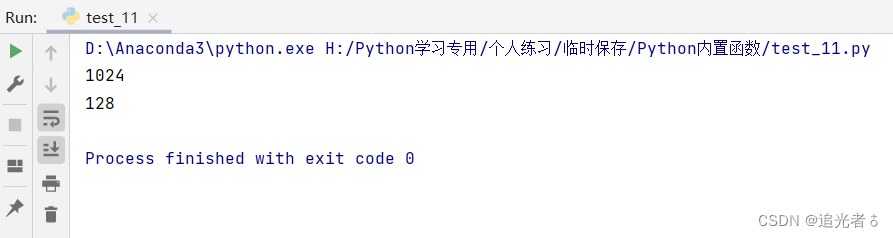
tuple_1 = (1, 3, 5, 7, 9, 17, 33, 62, 128, 256, 512, 1024) # 数字元组
print(max(tuple_1)) # 1024 输出元组中的最大值
print(max(tuple_1[3:9])) # 128 输出数字元组中第4个 到第9个 数值的 最大值
复盘一下之前的基础内容:还是以上面的元组为例
输出的内容放在注释中啦!
print(tuple_1[3:9]) # (7, 9, 17, 33, 62, 128)
print(tuple_1[-1:]) # (1024,)
print(tuple_1[-1]) # 1024
print(tuple_1[1]) # 3
print(tuple_1[0]) # 1
tuple_1 = (1, 3, 5, 7, 9, 17, 33, 62, 128, 256, 512, 1024) # 数字元组
注意一下下:
print(tuple_1[-2:]) # (512, 1024)
print(tuple_1[-3]) # 256
print(tuple_1[-4:]) # (128, 256, 512, 1024)
print(tuple_1[-7:]) # (17, 33, 62, 128, 256, 512, 1024)
print(tuple_1[-7:-2:2]) # (17, 62, 256)

🍑2.2 示例2:月份、星期元组
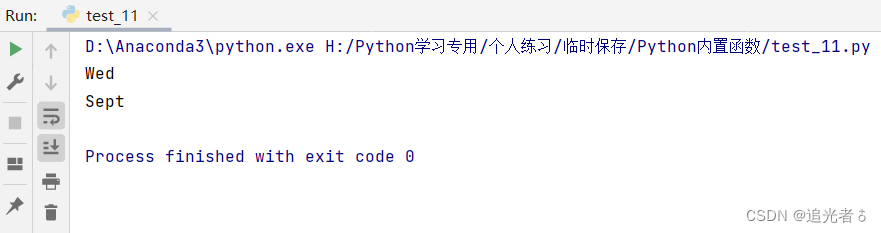
tuple2 = (
'Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sept', 'Oct', 'Nov', 'Dec', 'Mon', 'Tues', 'Wed', 'Thur',
'Fri') # 月份、星期简写元祖
print(max(tuple2)) # 输出tuple2的最大值(先比较元组的第1个元素,如果相同,再比较第2个元素…)
print(max(tuple2, key=lambda x: len(x))) # 输出元组中长度最大(即字符最多)的元组
print(len(tuple2)) # 17
print(tuple2[-2]) # Thur
print(tuple2[-2:-1]) # ('Thur',)
print(tuple2[-3:-1]) # ('Wed', 'Thur')
print(tuple2[-1:]) # ('Fri',)
print(tuple2[-2:]) # ('Thur', 'Fri')
print(tuple2[-5:-1]) # ('Mon', 'Tues', 'Wed', 'Thur')
🍑2.3 示例3:NBA球队成绩元组
# NBA球队成绩元组
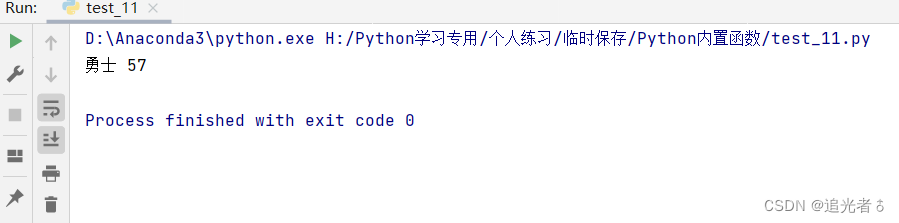
tuple3 = ('勇士 57', '掘金 54', '开推者 53', '火箭 53', '爵士 50', '雷霆 49', '马刺 48', '快船 48')
print(max(tuple3, key=lambda x: x[-2:])) # 获取元组后两项数据的最大值,即获胜场次取最大值
🍑2.4 示例4:电影上映时间元组
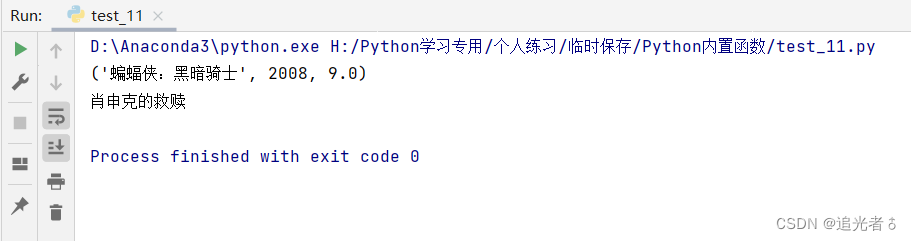
tuple4 = (
('肖申克的救赎', 1994, 9.3), ('教父', 1972, 9.2), ('教父2', 1974, 9.1), ('蝙蝠侠:黑暗骑士', 2008, 9.0), ('低俗小说', 1994, 8.9)) # 电影信息元祖
print(max(tuple4, key=lambda x: x[1])) # 按每个元组的第2项取最大值,即出品年份
print(max(tuple4, key=lambda x: x[2])[0]) # 按元组的第3项(打分)取最大值,只输出最大值的第一个元素
🍑2.5 示例5:元组 & 元组
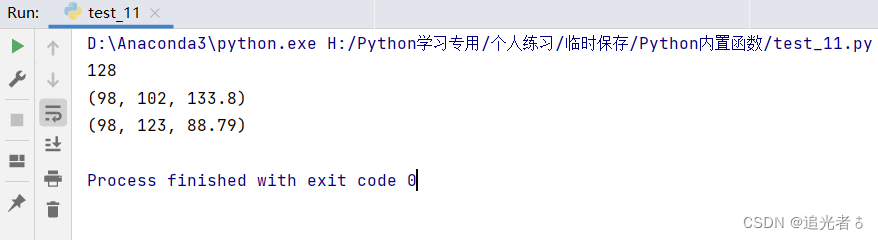
tuple5 = ((90, 128, 87.103), (78, 99, 134.106), (98, 102, 133.80), (66, 78, 97, 56), (98, 123, 88.79))
print(max(max(tuple5, key=lambda x: x[1]))) # 按照tuple5的第2项取最大值,然后在最大值中再取最大值
print(max(tuple5, key=lambda x: (x[0] + x[1] + x[2]))) # 按照元组的3项之和获取最大值
print(max(tuple5, key=lambda x: (x[0], x[1]))) # 按元组第1项和第2项取最大值,第一项相同,比较第2项
🍄三、在字典中使用max
🍑3.1 示例1:会员信息字典 字典 max操作
使用max函数,默认情况下,字典迭代的是key(键值)。如果要迭代value,可以用可以直接指定,也可以通过
for value in d.values()进行指定,还可以通过zip函数变换键与值位置进行指定。在利用字典求最大值时,经常要用到匿名函数key=ladmbo,需要注意的是:不论匿名函数怎么处理参数,返回的不是处理后的结果,而是结果对应的参数本身。Max在字典中的常用应用如下:
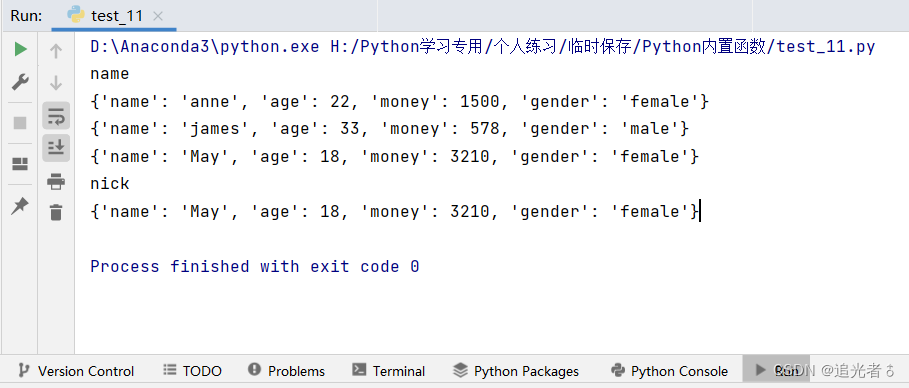
dict1 = {'name': 'john', 'age': 23, 'money': 1200, 'gender': 'male'} # 创建会员信息字典,name为会员姓名
dict2 = {'name': 'anne', 'age': 22, 'money': 1500, 'gender': 'female'} # 创建会员信息字典,age为会员年龄
dict3 = {'name': 'james', 'age': 33, 'money': 578, 'gender': 'male'} # 创建会员信息字典,money为会员账户积分
# 创建会员信息字典,gender为会员性别,male为男性,female为女性
dict4 = {'name': 'nick', 'age': 46, 'money': 158, 'gender': 'male'}
dict5 = {'name': 'May', 'age': 18, 'money': 3210, 'gender': 'female'} # 创建会员信息字典
lsitdc = [dict1, dict2, dict3, dict4, dict5] # 创建2维会员信息字典
print(max(dict1)) # 默认获取键的最大值,即'name'、'age'、'money'和'gender'的最大值
# 将性别为女性的年纪最大的会员输出出来,一定要先限制性别,再按年纪取最大值,否则将按年纪排名,不区分性别。
print(max(list(filter(lambda item: item['gender'] == 'female', lsitdc)), key=lambda item: item['age']))
# 输出积分超过500,年龄最大的的会员
print(max(list(filter(lambda item: item['money'] > 500, lsitdc)), key=lambda item: item['age']))
print(max(lsitdc, key=lambda x: x['money'])) # 按积分输出最大者
print(max(lsitdc, key=lambda x: x['age']).get('name')) # 输出年龄最大会员,只输出名字
def dic_key(dic): # 编写函数dic_key,设置max函数的获取最大值的键
return dic['money'] # 设置'money'为max函数获取最大值的键
print(max(lsitdc, key=dic_key)) # 调用dic_key函数,获取字典中积分最高的会员
上述,可以注意一下:
# 将性别为女性的年纪最大的会员输出出来,一定要先限制性别,再按年纪取最大值,否则将按年纪排名,不区分性别。
print(max(list(filter(lambda item: item['gender'] == 'female', lsitdc)), key=lambda item: item['age']))
实现了同时满足两个条件的输出。
下述也是类似的。
# 输出积分超过500,年龄最大的的会员
print(max(list(filter(lambda item: item['money'] > 500, lsitdc)), key=lambda item: item['age']))
🍑3.2 示例2:列表 & 字典(按照条件取最大值)
dictcar = [{'名称': '卡罗拉', '销量': 1181445}, {'名称': '福特F系', '销量': 1080757}, {'名称': 'RAV4', '销量': 837624},
{'名称': '思域', '销量': 823169}, {'名称': '途观', '销量': 791275}]
print(max(dictcar, key=lambda x: x['名称'])) # 按照名称取最大值,即'卡罗拉'、'福特F系'等中取最大值
print(max(dictcar, key=lambda x: x['销量'])) # 按照销量取最大值,即1181445、1080757…等中取最大值
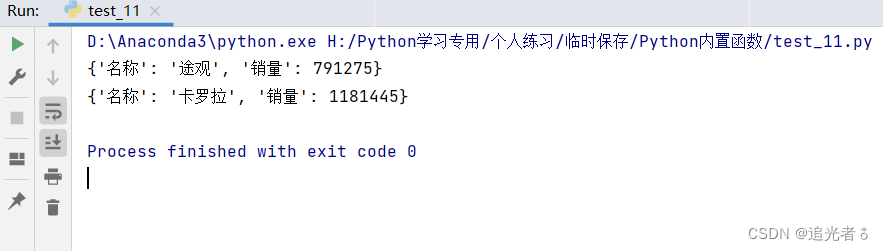
🍑3.3 示例3:字典 姓名&年份 按条件取最大值
dictage = {'李冰冰': '1996', '张步韵': '1999', '赵构': '1903', '邱子丹': '2008', '杨百风': '2012'}
print(max(dictage)) # 默认获取键的最大值,即'李冰冰'、'张步韵'…'杨百风'等的最大值
print(max(dictage.values())) # 希望用value取最大值,需要设定值(values)为迭代项
print(list(dictage.keys())[list(dictage.values()).index(max(dictage.values()))]) # 最大值对应的键
print(max(dictage.values())[-2:]) # 获取value最大值项的后两个字符
print(max([x for x in dictage.keys()])) # 在字典中获取键(key)最大的项
print(max([x for x in dictage.values()])) # 在字典中获取值(value)最大的项
print(max(zip(dictage.values(), dictage.keys()))) # 用zip函数将字典的键和值调换位置,然后获取最大值
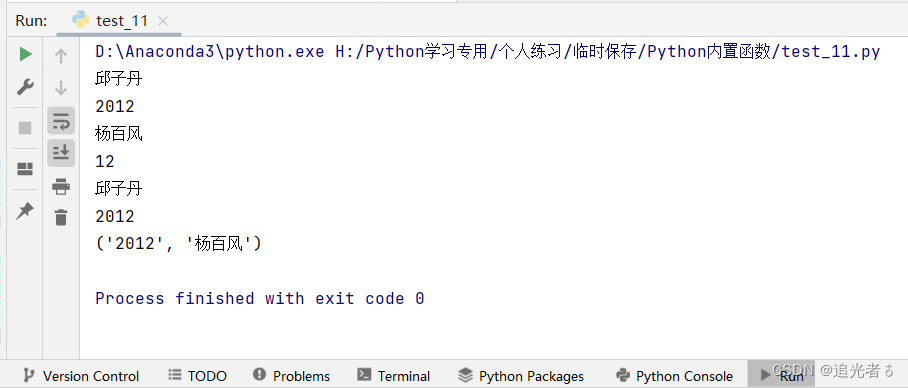
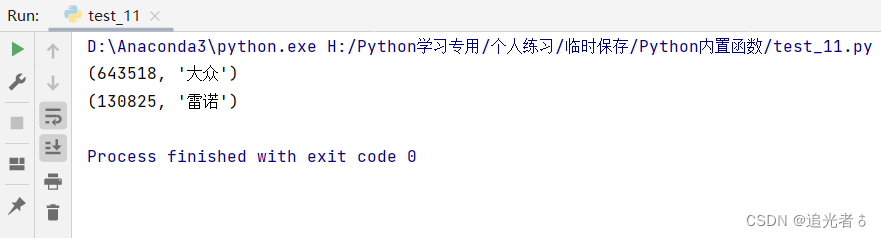
🍑3.4 示例4:zip()函数的使用
dictall = {'大众': 643518, '奔驰': 319163, '宝马': 265051, '福特': 252323, '雪铁龙': 227967, '雷诺': 130825, '现代': 114878,
'奥迪': 255300}
newdict = zip(dictall.values(), dictall.keys()) # 用zip函数将字典的键和值调换位置
print(max(newdict)) # 获取新生成字典的最大值
print(max(zip(dictall.values(), dictall.keys()), key=lambda x: x[1])) # 按位置置换后字典value取最大值
🍄四、应用场景
🍑4.1 场景一:歌咏比赛歌手分数计算程序
计算歌咏比赛歌手的得分。在歌咏比赛中,为确保比赛的公正、公平、公开,通常会采用统计学的方法计算歌手比赛得分,即
将歌手得分中最高分、最低分去掉,计算剩余分数的和再除以有效评委数(去掉最高分和最低分的评委)的得分。下面是某一次歌咏比赛的比赛情况,比赛中共有7名评委,满分为10分,按照统计学的方法计算歌手的最后得分并降序输出歌手得分排名,代码如下:
# 昵 称:XieXu & CSDN@追光者♂
# 时 间: 2023/4/5/0005 21:22
# 列表存储歌手比赛评委打分
songer1 = ['杨晨', 8.2, 9.1, 7.8, 8.7, 9, 8.4, 8.9]
songer2 = ['邓紫', 9.5, 9.2, 8.6, 8.9, 9.5, 9.4, 9.1]
songer3 = ['阿妹', 7.9, 8.1, 8.3, 9.3, 8, 7.9, 8.2]
songer4 = ['陈粒', 8.6, 8.8, 5.4, 8.8, 8, 8.7, 9.5]
songer5 = ['卓玛', 6.8, 7.1, 6.8, 6.7, 7.3, 8.4, 8.8]
songer = [songer1, songer2, songer3, songer4, songer5] # 创建歌手分数列表
sortsong = [] # 创建歌手得分空列表,用于保存之后计算的歌手得分
for item1 in songer: # 循环计算歌手分数
item1.remove(max(item1[1:])) # 去掉一个最高分
item1.remove(min(item1[1:])) # 去掉一个最低分
# 歌手得分:去掉最高分、最低分,剩余分数相加和除以有效评委人数(去掉高分和低分的评委)
avg = float('%.2f' % ((item1[1] + item1[2] + item1[3] + item1[4] + item1[5]) / (len(item1) - 1)))
sortsong.append([item1[0], avg]) # 将歌手姓名和得分添加到歌手得分列表
sortsong.sort(key=lambda x: x[1], reverse=True) # 歌手最后得分降序排序
for item1 in sortsong: # 输出歌手得分降序排序结果
print(item1[0], item1[1])
说明:本例主要
利用max函数在歌手列表中获得最高分的项,然后删除最高分。因为列表中第1项是姓名,之后的各项是评委打分,所以max是从第2项到最后一项(即item1[1:])获取评委的最高评分。
运行后,结果为:
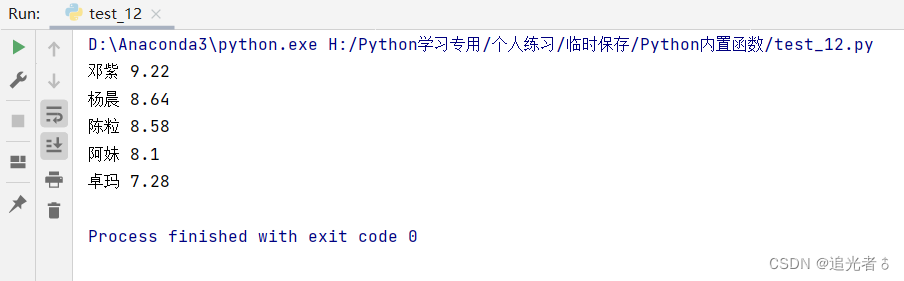
可以说,本例的处理是比较巧妙的。一是巧妙地借用max()函数,二是巧妙地使用for循环进行循环迭代。
🍑4.2 场景二:根据输入参数输出该参数最大值的产品信息
下面是用字典保存的苹果手机的相关产品信息,编写一个程序,实现
用户输入相关产品参数(字典的键)后,可以获得该产品参数对应最大值的产品信息,输出要求用中文显示对应英文参数的中文对应名称。如输入“price”,则会将该参数最大值的产品查找出来,输出时将翻译“price”为中文“价格”输出,同时用中文名称“价格”代替英文参数“price”作为提示输出产品信息。代码如下:
# 昵 称:XieXu & CSDN@追光者♂
# 时 间: 2023/4/5/0005 21:24
# 定义函数searchMax(),实现按参数名获得该参数最高的一个产品型号
def searchMax(item):
pro1 = {'product': 'iPhone xs', 'screen': 5.8, 'price': 8699, 'weight': '177克', 'depth': 7.7}
pro2 = {'product': 'iPhone xs Max', 'screen': 6.5, 'price': 9599, 'weight': '208克', 'depth': 7.7}
pro3 = {'product': 'iPhone xr', 'screen': 6.1, 'price': 6499, 'weight': '194克', 'depth': 8.3}
proList = [pro1, pro2, pro3] # 定义列表存储产品各项参数值
maxsel = max(proList, key=lambda x: x[item]) # 在列表中按参数获得该参数的最大值
return maxsel # 返回参数最大值对应的产品信息
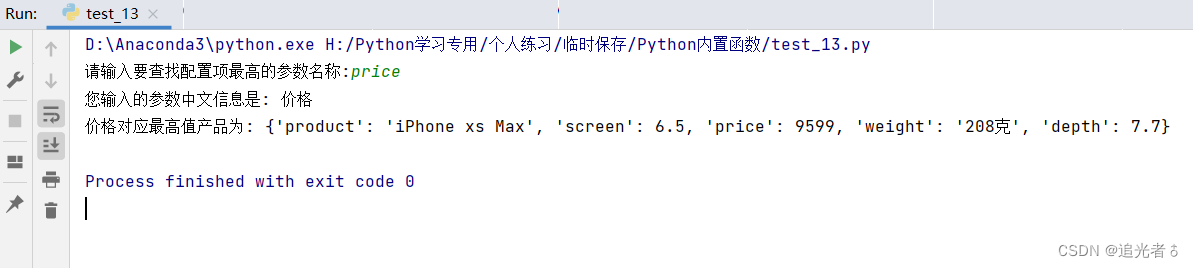
itemName = input('请输入要查找配置项最高的参数名称:') # 通过接收用户输入的参数名,来获取相关产品
# 产品参数中文对照字典
msg = {'product': '产品名称', 'screen': '屏幕尺寸', 'price': '价格', 'weight': '重量', 'depth': '厚度'}
print('您输入的参数中文信息是:', msg[itemName]) # 输出用户输入的产品中文信息
print(msg[itemName] + '对应最高值产品为:', searchMax(itemName))
将各个字典,作为元素放在列表中,是一个常见的操作。
在上面的示例中,将用户的输入,巧妙地与字典中的“键”组合到一起,此外还能将用户的输入巧妙地作为函数的参数。
🍑4.3 场景三:获得当前内存的使用最大值
Psutil是第三方模块,可以
很方便实现对系统信息的获取。编写一个程序,实现对计算机内存使用情况的监控,要求输出当前内存使用情况和当前内存使用列表中内存使用最大值。代码如下:
# 昵 称:XieXu & CSDN@追光者♂
# 时 间: 2023/4/5/0005 21:25
import psutil
import os
# 输出当前内存使用列表中内存使用最大的值
def memory_use():
processnow = psutil.Process(os.getpid()) # 获得当前进程ID
memory = processnow.memory_info()[1] / (1024.0 * 1024.0) # 计算当前内存使用的情况
return memory # 返回当前内存使用情况
print(memory_use()) # 输出当前内存使用情况
# 创建一个当前内存使用列表,在列表中找出内存使用的最大值
msq = max([memory_use() for i in range(10000)])
print(msq)
说明:运行本程序需要安装psutil模块,安装该模块可以使用以下命令安装。
pip install psutil
执行上述程序后,在本机的测试结果为:

🍒 热门专栏推荐:
- 🥇Python&AI专栏:【Python从入门到人工智能】
- 🥈前端专栏:【前端之梦~代码之美(H5+CSS3+JS.】
- 🥉文献精读&项目专栏:【小小的项目 (实战+案例)】
- 🍎C语言/C++专栏:【C语言、C++ 百宝书】(实例+解析)
- 🍏Java系列(Java基础/进阶/Spring系列/Java软件设计模式等)
- 🌞问题解决专栏:【工具、技巧、解决办法】
- 📝 加入Community 一起追光:追光者♂社区
持续创作优质好文ing…✍✍✍
记得一键三连哦!!!
求关注!求点赞!求个收藏啦!