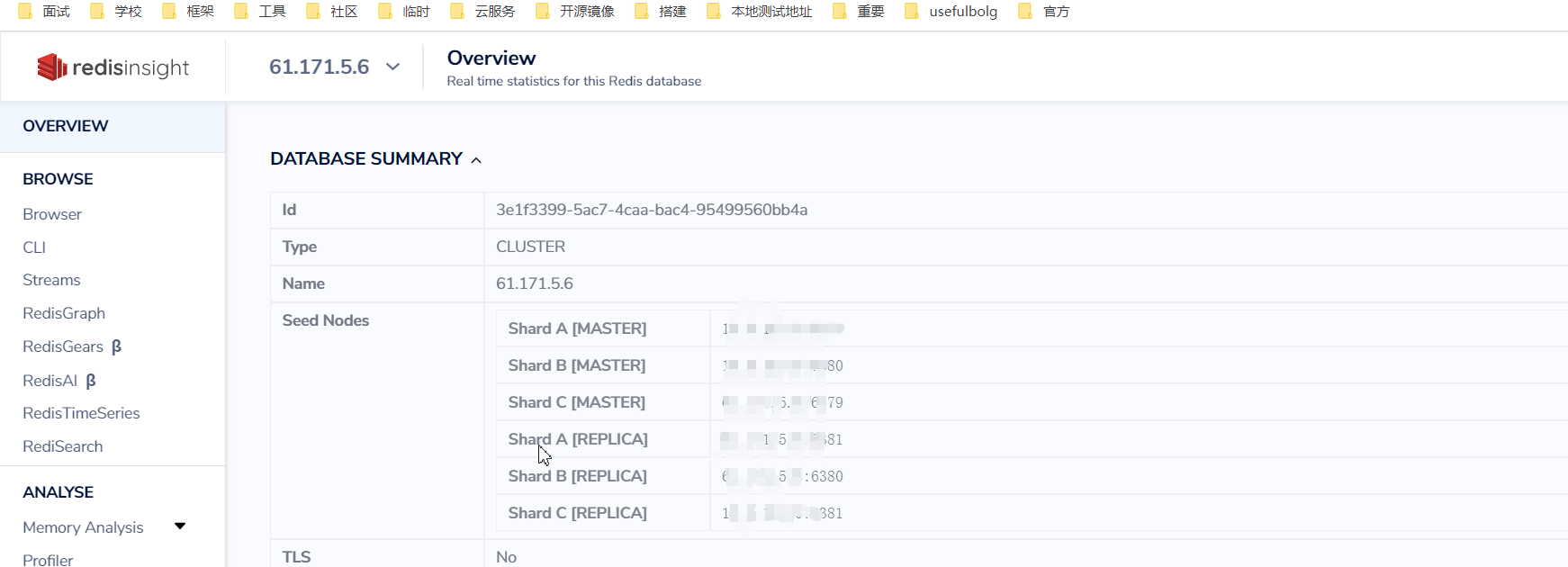
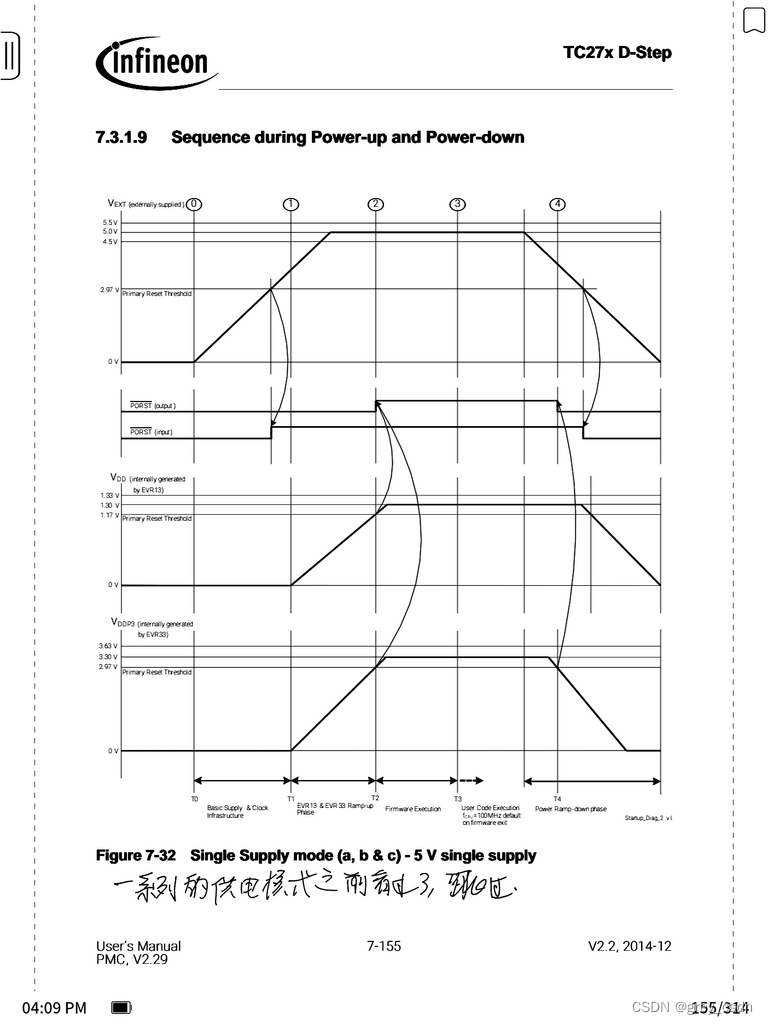
什么是具身智能?
目前人工智能的进展,在诸多数据源和数据集(Youtube、Flickr、Facebook)、机器计算能力(CPU、GPU、TPU)的加持下,已经在CV、NLP上取得了许多任务(如目标检测、语义分割等)的重大进展。
但目前大部分深度学习模型训练时使用的数据来自于互联网(Internet AI),而并非来自现实世界的第一人称人类视角,这样训练得到的模型是旁观型的,它只能学习到数据中的固定模式并将其映射到标签层,并不能在真实世界中直接进行学习,也不能对真实世界作出直接影响。
而在自然界中,动物为了适应环境会不断地进化以更好的生存和生活。对于人类来说,从婴儿开始就扎根于真实世界,通过观察、移动、互动和与他人交谈来学习,因此人脑中的很多认知都依赖于主体物理身体特征与世界的连续型交互,而不是从混乱和随机的经验中学习,这才是人类感知世界的方式!智能体是在主体与环境的相互作用中出现的,并且是感觉活动的结果。
因此为了满足AI机器人能够像人类一样在真实世界中实践型学习,具身智能(Embodied AI)逐渐成为一个热门的讨论点,或许它就是通往通用人工智能的关键钥匙。具身的含义不是身体本身,而是与环境交互以及在环境中做事的整体需求和功能,这意味着机器人应该像人类一样通过观察、移动、说话和与世界互动来学习。
Internet AI和Embodied AI的区别?
旁观型标签学习方式 v.s. 实践性概念学习方法
- Internet AI从互联网收集到的图像、视频或文本数据集中学习,这些数据集往往制作精良,其与真实世界脱节、难以泛化和迁移。1)数据到标签的映射。2)无法在真实世界进行体验学习。3)无法在真实世界做出影响。
- Embodied AI通过与环境的互动,虽然以第一视角得到的数据不够稳定,但这种类似于人类的自我中心感知中学习,从而从视觉、语言和推理到一个人工具象( artificial embodiment),可以帮助解决更多真实问题。
Embodied AI的挑战
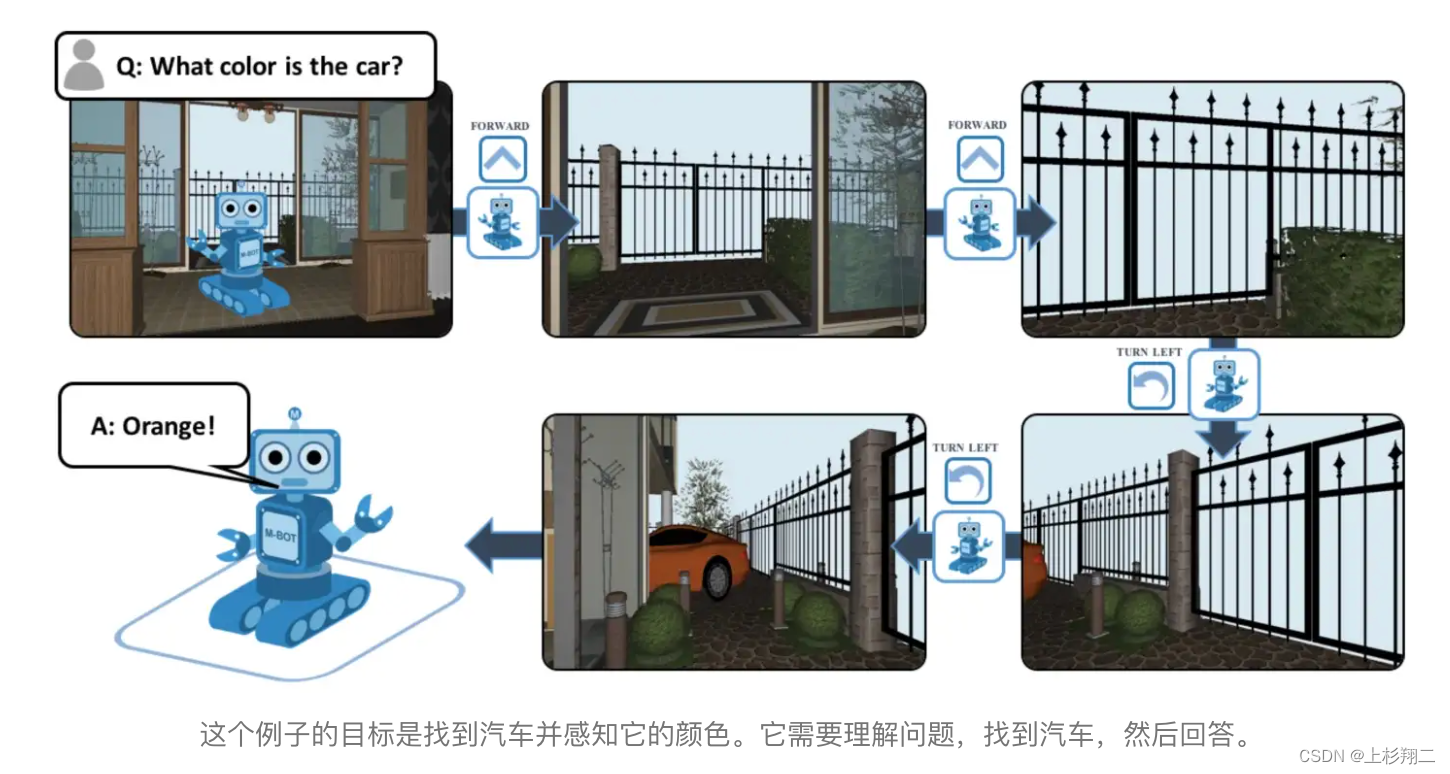
一个Embodied AI中的经典任务如上图所示,智能体必须先理解问题“汽车的颜色是什么”,然后找到汽车,再回答问题是“橙色”。因此智能体必须根据其对世界的感知、潜在的物理约束以及对问题的理解,学习将其视觉输入映射到正确的动作。
- 主动感知。智能体收集的数据是在环境中采取的行动的结果,因此某种程度上它可以控制它想看到的像素。这与Internet AI中的静态数据集不同。
- 稀疏奖励。与监督学习不同,智能体会为每个动作收集即时奖励,但它们通常是稀疏的,大多数情况下,仅当它完成目标(例如“步行到汽车”)时才会提供正向奖励,但这会导致奖励稀疏。
Embodied AI的所需能力
一般需要测量、定位、导航、理解、实施、回答。主要有以下子任务:
- Visual Odometry。使用视觉来传感器测量来智能体(比如无人机)的特定自由度下的姿态、速度等物理量,一般作为 GPS、惯性导航系统 (INS)、轮式里程计等的补充,它已被广泛应用于各种机器人。
- Global Localization。给定环境地图和环境观察的情况下进行定位。
- Visual Navigation。在三维环境中导航是在物理世界中运行的机器人的基本能力之一。
- Grounded Language Learning。人类语言是这种交流最引人注目的方式,因此机器人必须要能够将语言、世界和行动联系起来。
- Instruction Guided Visual Navigation。向机器人发出口头指令,然后希望它会执行和指令语义相关的任务,这也是多模态领域一个很重要的方向,视觉和语言导航 (VLN)。
- Embodied Question Answering。即上图所示的例子,为了回答汽车的颜色是“橙色!”,它必须首先智能导航以探索环境,通过第一人称视觉收集信息,然后回答问题。因此它需要先主动感知、语言理解、目标驱动的导航、常识推理(如汽车通常位于房子的什么位置?),以及将语言转化为动作的基础(如将文本中的实体与相应的图像像素或动作序列相关联)。
数据集和虚拟环境
虚拟环境模拟器将承担以前由监督数据集扮演的角色。数据集一般由房屋、实验室、房间或外部世界的 3D 场景组成,然后模拟器允许具身agent与环境进行物理交互,如观察、移动并与环境交互等等,甚至可以与其他agent或人类交谈。为了使虚拟环境更贴近现实,其一般需要构建以下特征,
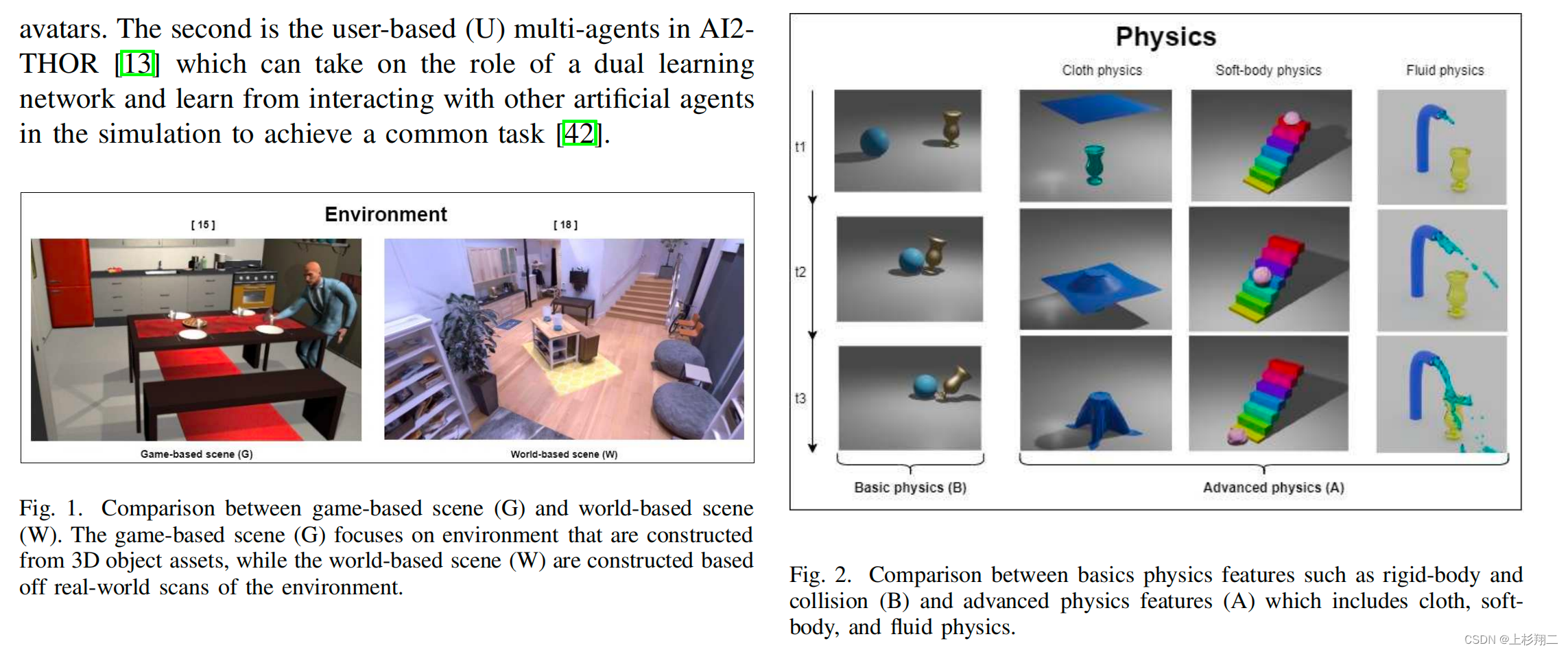
- Environment。构建具体化的人工智能模拟器环境的方法主要有两种:基于游戏的场景构建(G)和基于世界的场景构建(W)。如下图左侧为游戏的画面场景和世界的房间场景。
- Physics。模拟真实的物理属性,分为基本物理特征(B,如碰撞、刚体动力学和重力建模)和高级物理特征(A,如流体和软体物理学)。如下图右侧。
- Object Type。用于创建模拟器的对象有两个主要源:数据集驱动的环境和资产驱动的环境。
- Object Property。具有基本交互性的对象如碰撞、状态更改(如苹果被切成苹果片),因此可分为:可交互对象(I)和多个状态对象(M)。
- Controller。用户和模拟器之间存在不同类型的控制器接口。如下图的python接口、机器人接口或VR接口。

- Action。通过虚拟现实界面进行人机操作,分为机器人操作三层:导航(N)、原子动作(A)和人机交互(H)。
- Multi-Agent。多代理拥有更广泛的实用价值,但目前涉及多代理强化学习的研究很少。
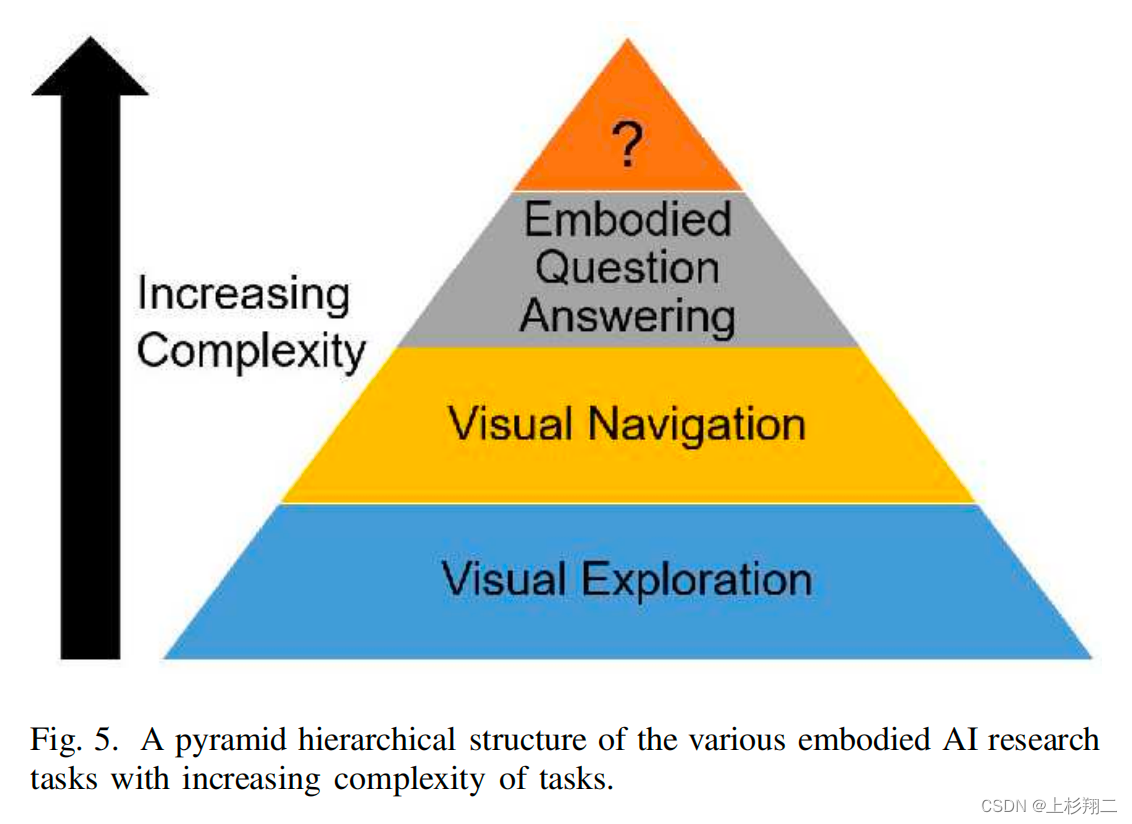
Embodied AI主要任务
如上图所示,具身智能研究任务主要类型分别是视觉探索、视觉导航和具身QA。
- Visual Exploration:收集关于3D环境的信息,通常通过运动和感知,以更新其内部环境模型。
- Visual Navigation:在有无外部先验或自然语言指令的情况下,将三维环境导航到目标。可以分为Point Navigation、Object Navigation、Navigation with Priors、Vision-and-Language Navigation。
- Embodied QA:最重要的任务,需要拥有广泛的人工智能能力,如视觉识别、语言理解、问题回答、常识推理、任务规划和行动驱动导航。Multi-target embodied QA、Interactive Question Answering。
Reference
Embodied Intelligence via Learning and Evolution
A Survey of Embodied AI: From Simulators to Research Tasks
接下来补一些2篇和大模型结合的论文,不太全,欢迎留言补充。
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
如题是Grounding Language任务,即按照人类口头指令执行任务。和语言模型结合的motivation在于,大语言模型可以编码关于世界的丰富语义知识,这些知识对于机器人能够执行高水平的指令可能非常有用。然而,语言模型的一个显著弱点是它们缺乏现实世界的经验,这使得很难利用它们来进行具象决策。
如下图所示,对于“我把饮料洒了出来,你能帮忙吗?” ,缺乏现实经验的语言模型可能会给出不现实的建议,如如果现场没有吸尘器等物品,机器人是无法帮忙清除饮料的。因此,相结合之下,机器人可以作为语言模型的“手和眼睛”,而语言模型则提供关于任务的高级语义知识,从而将低级别技能与大型语言模型结合起来。
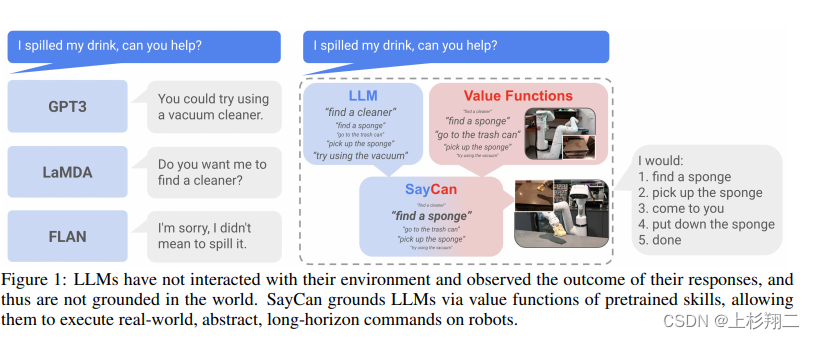
本文主要提出了一种将语言模型转化为机器指令的方法,如上图右侧,大规模语言模型的能力可以帮助分解语义从而得到足够的可能,然后通过强化学习训练一个价值函数来判断可能的价值,最终指导机器人去找到海绵、拿起海绵、找到你、放下海绵、结束。具体的模型结构如下图所示,
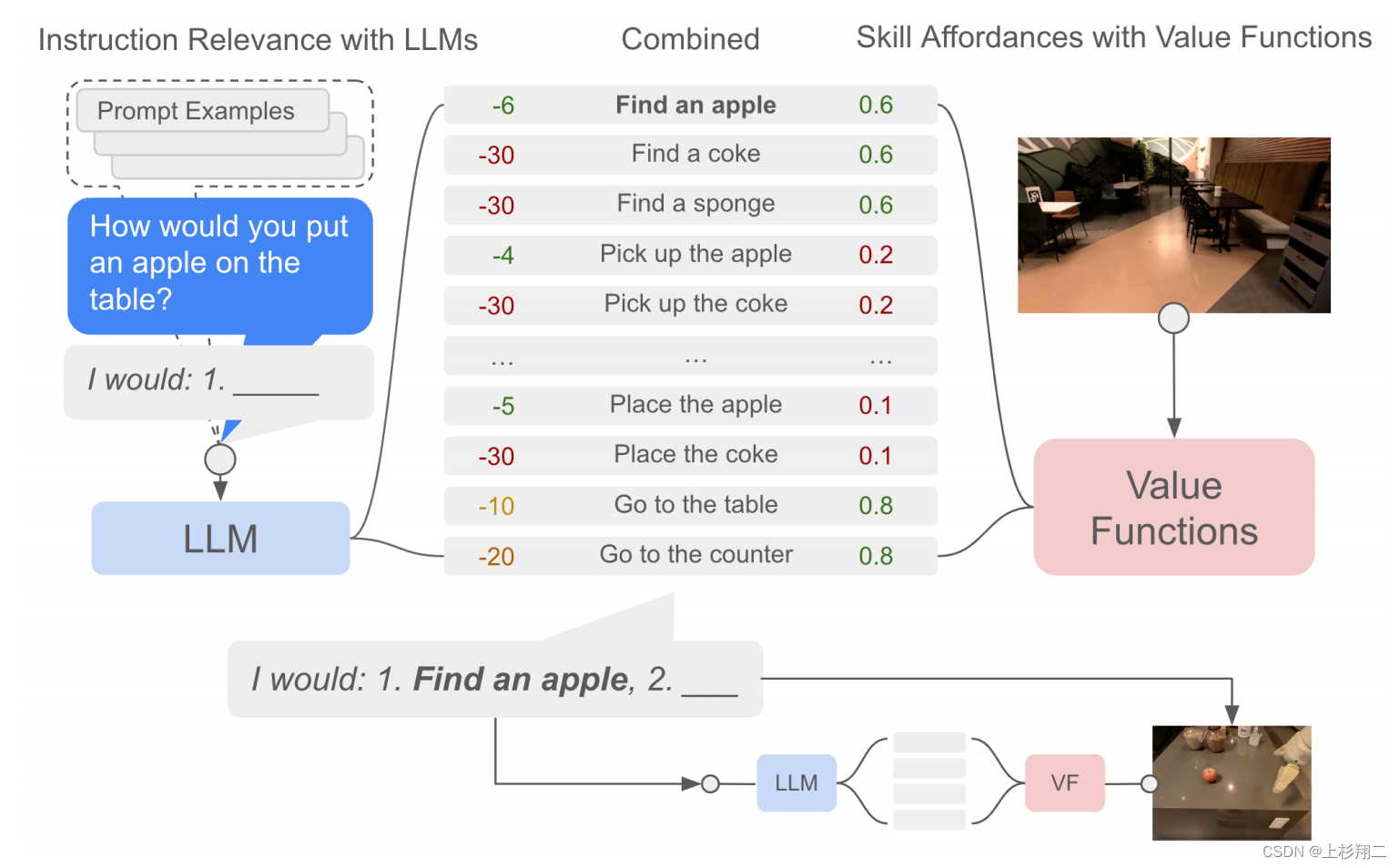
给定一个高级指令,SayCan结合了来自LLM的概率(一个技能对指令有用的概率)和来自一个值函数的概率(为的概率 成功地执行上述技能)来选择要执行的技能。
- LLM。先把指令变成Prompt形式,再利用LLM把指令分解成多个动作,如拿起或放下苹果。
- VF。通过训练好的价值函数,联合LLM给出动作的概率分布,并使机器人执行概率最大的动作,如找到苹果。
- 重复。执行完第一个动作之后,再拼接成新的prompt以生成第二个动作。
code:https://github.com/google-research/google-research/tree/master/saycan
paper:https://arxiv.org/pdf/2204.01691
demo:https://sites.research.google/palm-saycan
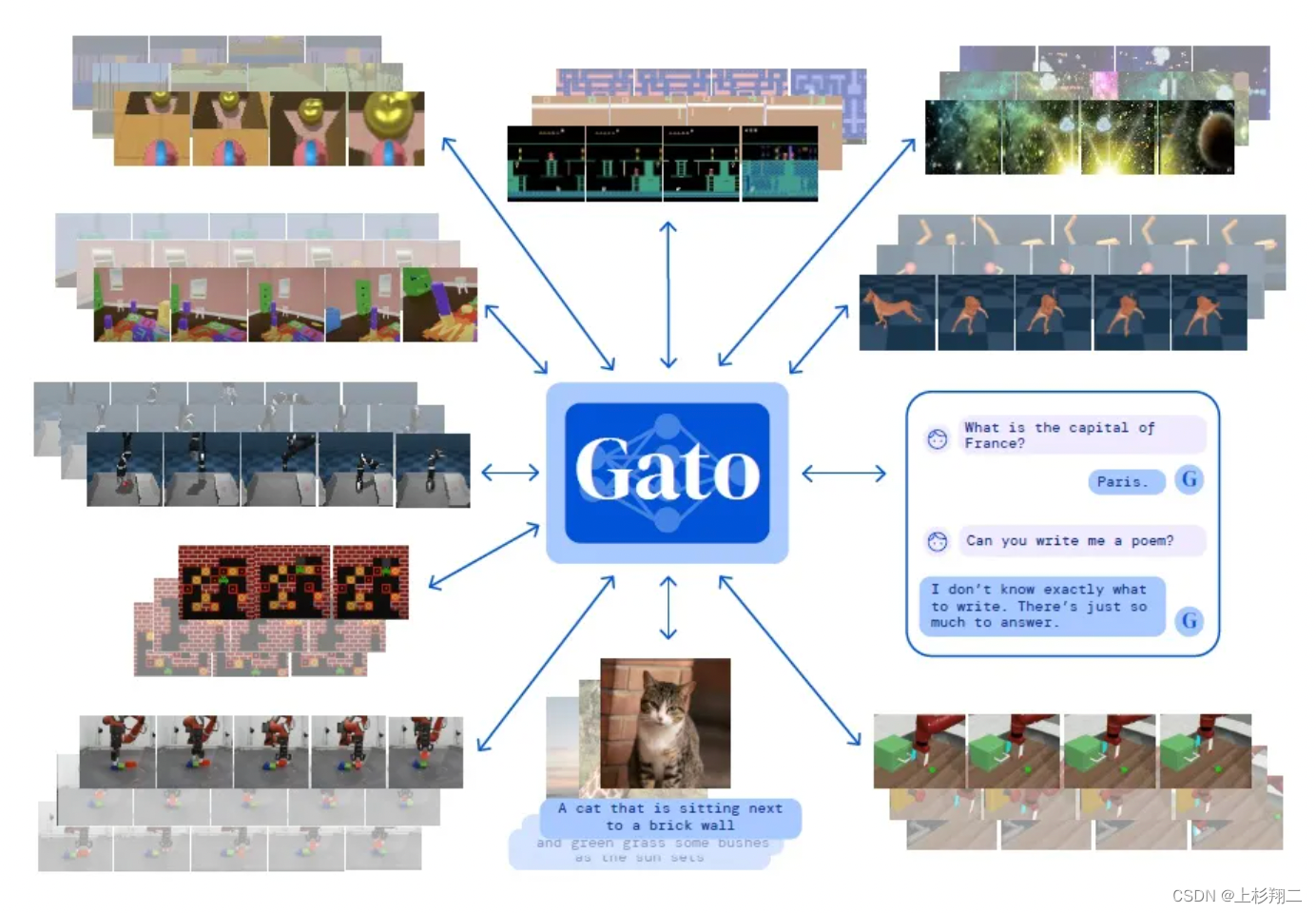
A Generalist Agent
同样受大规模语言建模的启发,Deepmind提出的Gato模型的关键词是通用智能体、多模态、多任务。如上图所示,同一个网络可以玩游戏、生成caption、控制机器人等等,参数量为12亿。模型结构如下,各个模态的数据被分别编码,如图像用ViT等,然后输入Gato.
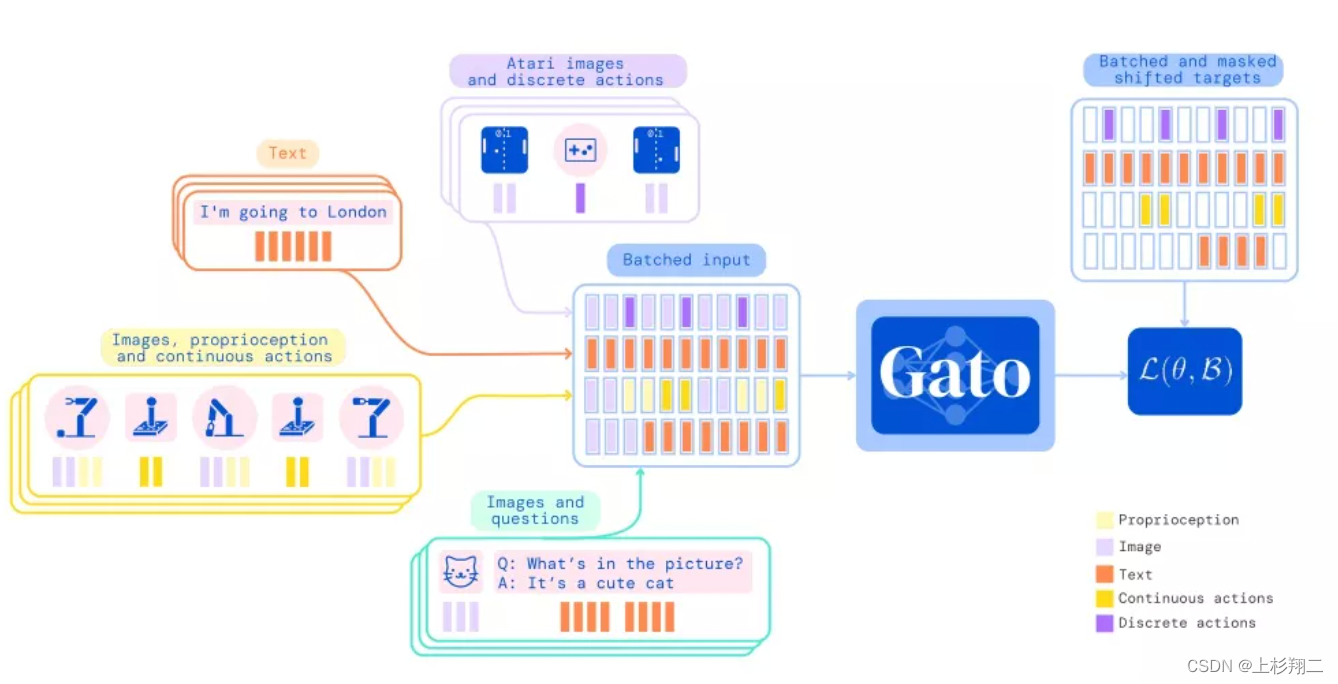
Gato的主框架是一个24层decoder-only transformer,基于自回归生成(用前t时间步去预测t+1的表征)后再和环境进行交互。
L
(
θ
,
B
)
=
−
∑
h
=
1
∣
B
∣
∑
l
=
1
L
m
(
b
,
t
)
l
o
g
p
θ
(
s
l
(
b
)
∣
s
1
(
b
)
,
…
,
s
l
−
1
(
b
)
)
L(\theta,B)=-\sum^{|B|}_{h=1}\sum^L_{l=1} m(b,t)log p_{\theta}(s^{(b)}_l|s^{(b)}_1,…,s^{(b)}_{l-1})
L(θ,B)=−h=1∑∣B∣l=1∑Lm(b,t)logpθ(sl(b)∣s1(b),…,sl−1(b))
paper