在本系列文章的第4篇《Go语言开发者的Apache Arrow使用指南:数据操作》[1]中我们遇到了大麻烦:Go的Arrow实现居然不支持像max、min、sum这样的简单聚合计算函数:(,分组聚合(grouped aggregation)就更是“遥不可期”。要想对从CSV读取的数据[2]进行聚合操作和分析,我们只能“自己动手,丰衣足食” - 扩展Arrow Go实现中的compute包了。
不过,Arrow的Go实现还是蛮复杂的,如果对其结构没有一个初步的认知,很难实现这类扩展。在这篇文章中,我们就来了解一下compute包的结构,并尝试为compute包添加几个简单的、仅能处理单一类型的聚合函数,先来完成一些从0到1的工作。
为了深入了解Go Arrow实现,我又翻阅了一下Arrow官方的文档,显然Arrow C++的文档[3]是最丰富的。我快读了一下C++的Arrow文档,对Arrow的结构有了更深刻的认知,基于这些资料,我们先来做一下Arrow结构的回顾。
0. 回顾Arrow的各个layer
Arrow的C++文档使用layer来介绍各种Arrow的概念,我们挑几个重要的看一下:
物理层(The physical layer)
物理层针对的是内存的分配管理,包括内存分配的方法(堆分配器、内存文件映射、静态内存区)等。这一层的一个最重要的概念就是我们之前在数据类型[4]一文中提到的Buffer抽象,它代表了内存中的一块连续的数据存储区域。
一维表示层(The one-dimensional layer)
除了物理层,后续的层都是逻辑层。一维表示层是一个逻辑表示层,它定义了Arrow的最基本数据类型:array。数据类型决定了物理层内存数据的解释方法[5],逻辑数据类型array在物理层投影为一个和多个内存buffer。
我们在“高级数据结构”[6]提到的chunked array也在这一层,chunked array由多个同构类型的array组成,Arrow将其理解为一个同构的(相同类型的)、逻辑上值连续的、更大的array,是array基础类型的一个更泛化的表示。
二维表示层(The two-dimensional layer)
“高级数据结构”[7]一文中除chunked array之外的概念,都在这一层,包括schema、table、record batch。
schema是用于描述一维数据(一列数据,即一个逻辑array)的元数据,包括列名、类型与其他元信息。
Table是schema+与schema元信息对应的多个chunked array,它是Arrow中数据集抽象能力最强的逻辑结构。
Record Batch则是schema+与schema元信息对应的多个array。还记得“高级数据结构”[8]一文中的那副直观给出table与record batch差异的图么:
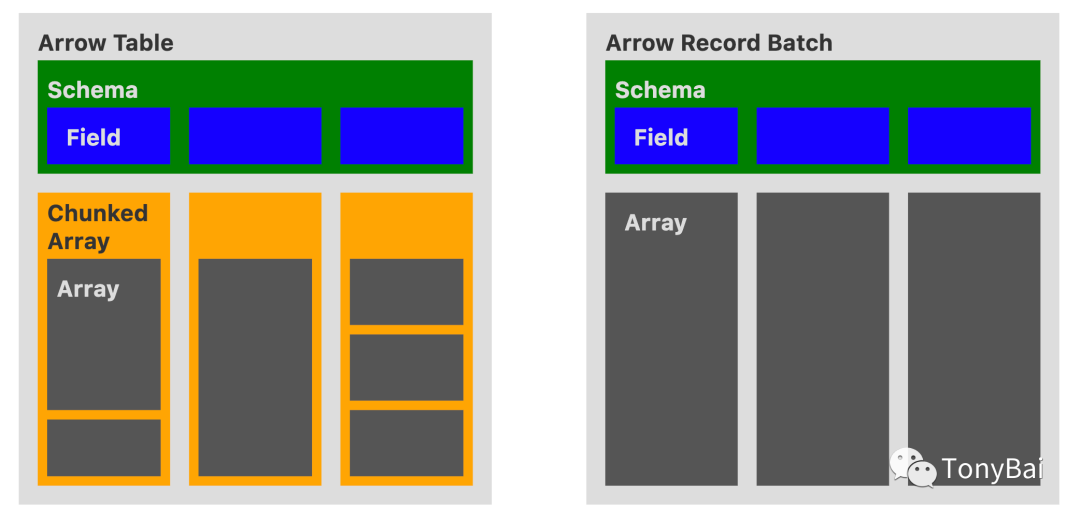
计算层(The compute layer)
计算层一个重要的抽象是Datum,这是一个灵活的抽象,用于统一表示参与计算的各类输入参数和返回值。
计算层真正执行计算的函数被统一放在kernel这个“层次”中,这个层次的函数对Datum类型的输入参数进行计算并返回Datam类型的结果或以Datum类型的输出参数承载计算结果。
IPC层(The Inter-Process Communication (IPC) layer)
这是我们尚未接触过的一层,通过这一层,复合Arrow columnar format的数据可以在进程间(同一主机或不同主机)交互,并且这种交换可以保证尽可能少的内存copy。
文件格式层(The file formats layer)
这一层负责读写文件,在之前的“数据操作”一篇中,我们接触过将CSV文件中的数据读到内存中并组织为Arrow列式存储格式,在后续篇章中,我们还将陆续介绍Arrow与CSV(写入)、Parquet文件的数据交互。
C++有关Arrow的介绍中还有设备层(the devices layer)、文件系统层(the file system layer)等,后续可能不会涉及,这里就不说了。
通过上述回顾,再对照本系列第一篇文章“数据类型”[9]的内容,你对Arrow的理解是不是更深刻一点点了呢:)。
接下来,我们重点看看计算层(the compute layer)。
1. 计算层(the compute layer)的结构
Go语言的计算层在compute目录下。Go语言借鉴了C++计算层的设计,将计算层分为compute和kernel,这个从代码布局上也可以明显看出来:
$tree -F -L 2 compute|grep -v go
compute --- compute层
├── exprs/
├── internal/
│ ├── exec/
│ └── kernels/ --- compute的kernel层compute包采用了registry模式,初始化时将底层的kernel function包装成上层的Function并注册到registry中。用户调用某个function时,该function会在registry中查找对应的注册函数并调用。
下面我们通过Uniq这个array-wise函数作为例子来探索一下kernel function的注册与调用过程。下面是“数据操作”[10]一文中的示例,这里再次借用一下:
// arrow/manipulation/unary_arraywise_function.go
func main() {
data := []int32{5, 10, 0, 25, 2, 10, 2, 25}
bldr := array.NewInt32Builder(memory.DefaultAllocator)
defer bldr.Release()
bldr.AppendValues(data, nil)
arr := bldr.NewArray()
defer arr.Release()
dat, err := compute.Unique(context.Background(), compute.NewDatum(arr))
if err != nil {
fmt.Println(err)
return
}
arr1, ok := dat.(*compute.ArrayDatum)
if !ok {
fmt.Println("type assert fail")
return
}
fmt.Println(arr1.MakeArray()) // [5 10 0 25 2]
}下面是Unique函数的注册和调用过程示意图:
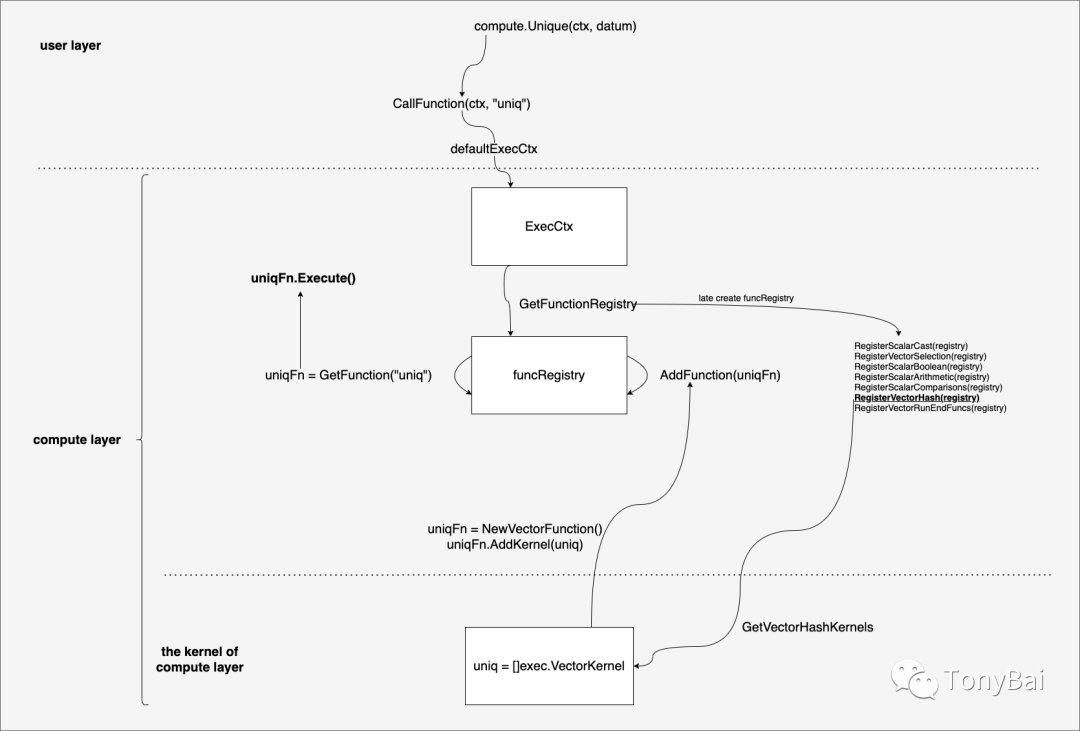
很显然,整个过程包括两个明显的阶段:
包装并向Registry注册kernel函数(AddFunction)
在Registry中查找函数并调用(GetFunction)
当我们在用户层调用compute.Unique函数时,一个统一的CallFunction会被调用,其第二个参数"uniq"表明我们要调用registry中的名为"uniq"的包装函数。在这个过程中GetFunctionRegistry被调用以获取registry实例,在这个过程中,如果registry实例尚没有创建,GetFunctionRegistry会在sync.Once的保护下创建registry并进行初始注册工作(RegisterXXX)。"uniq"对应的包装函数是在RegisterVectorHash中被注册到registry中的。
RegisterVectorHash会通过kernel层提供的GetVectorHashKernels获取kernel层的"uniq"实现,并将其通过NewVectorFunction和AddKernel包装为uniqFn这一用户层的Function,该uniqFn Function最终会被AddFunction加入到registry中。
而CallFunction(ctx, "uniq")也会从registry中将uniqFn查找出来并执行其Execute方法,该Execute方法实际上执行的是kernel层的"uniq"实现。
我们看到:通过示意图展示的Unique函数的注册与调用过程还是相对清晰的(但如果要阅读对应的代码,还是比较繁琐的)。
到这里我们也大致了解了compute包的结构以及与kernel层的关系,接下来我们就来尝试给compute包添加一些scalar aggregate函数,所谓scalar aggregate函数就是输入是array,输出是一个scalar值的函数,比如:max、min、sum等。
3. 添加Max、Min、Sum、Avg等Scalar Aggregate函数
在上一篇“数据操作”[11]时提过,聚合函数分为Scalar聚合和grouped聚合,显然Scalar聚合函数要简单一些,这里我们就来向compute层添加scalar aggregate函数,以Max为例,我们希望用户层这样使用Max聚合函数:
// max_aggregate_function.go
func main() {
data := []int64{5, 10, 0, 25, 2, 35, 7, 15}
bldr := array.NewInt64Builder(memory.DefaultAllocator)
defer bldr.Release()
bldr.AppendValues(data, nil)
arr := bldr.NewArray()
defer arr.Release()
dat, err := compute.Max(context.Background(), compute.NewDatum(arr))
if err != nil {
fmt.Println(err)
return
}
ad, ok := dat.(*compute.ArrayDatum)
if !ok {
fmt.Println("type assert fail")
return
}
arr1 := ad.MakeArray()
fmt.Println(arr1) // [35]
}注:这里有一个问题,那就是Max返回的Datum是一个ArrayDatum,而不是期望的ScalarDatum。
通过上面的compute layer的结构,我们知道,如果要添加Max、Min、Sum、Avg等Scalar Aggregate函数,我们需要在kernel层和compute层协作实现。下面是实现的具体步骤。
3.1 向kernel层添加scalar聚合函数实现
compute层要支持scalar聚合,需要kernel层线支持scalar聚合,这里我们先向compute/internal/kernels目录添加一个scalar_agg.go,用于在kernel层实现scalar聚合,以Max为例:
// compute/internal/kernels/scalar_agg.go
package kernels
import (
"fmt"
"github.com/apache/arrow/go/v13/arrow"
"github.com/apache/arrow/go/v13/arrow/compute/internal/exec"
"github.com/apache/arrow/go/v13/arrow/scalar"
)
func ScalarAggKernels(op ScalarAggOperator) (aggs []exec.ScalarKernel) {
switch op {
case AggMax:
maxAggs := maxAggKernels()
aggs = append(aggs, maxAggs...)
case AggMin:
minAggs := minAggKernels()
aggs = append(aggs, minAggs...)
case AggAvg:
avgAggs := avgAggKernels()
aggs = append(aggs, avgAggs...)
case AggSum:
sumAggs := sumAggKernels()
aggs = append(aggs, sumAggs...)
}
return
}
func aggMax(ctx *exec.KernelCtx, batch *exec.ExecSpan, out *exec.ExecResult) error {
var max int64
for _, v := range batch.Values {
if !v.IsArray() {
return fmt.Errorf("%w: input datum is not array", arrow.ErrInvalid)
}
if v.Array.Type != arrow.PrimitiveTypes.Int64 {
return fmt.Errorf("%w: array type is not int64", arrow.ErrInvalid)
}
// for int64 array:
// first buffer is meta buffer
// second buffer is what we want
int64s := exec.GetSpanValues[int64](&v.Array, 1 "int64")
for _, v64 := range int64s {
if v64 > max {
max = v64
}
}
}
out.FillFromScalar(scalar.NewInt64Scalar(max))
return nil
}
func maxAggKernels() (aggs []exec.ScalarKernel) {
outType := exec.NewOutputType(arrow.PrimitiveTypes.Int64)
in := exec.NewExactInput(arrow.PrimitiveTypes.Int64)
aggs = append(aggs, exec.NewScalarKernel([]exec.InputType{in}, outType,
aggMax, nil))
return
}
... ...上面的ScalarAggKernels函数就像上图中的GetVectorHashKernels一样,为compute层提供kernel层scalar agg函数的获取“渠道”。aggMax函数是实现聚合逻辑的那个函数,它针对输入的array进行操作,计算array中所有元素中的最大值,并将这个值包装成Datum作为out参数输出。
在compute/internal/kernels/types.go中,我们定义了如下枚举常量,用于compute层传入要选择的scalar聚合函数。
// compute/internal/kernels/types.go
//go:generate stringer -type=ScalarAggOperator -linecomment
type ScalarAggOperator int8
const (
AggMax ScalarAggOperator = iota // max
AggMin // min
AggAvg // avg
AggSum // sum
)3.2 在compute层提供对kernel层聚合函数的包装
在compute层,我们也提供一个scalar_agg.go文件,用于对kernel层的聚合函数进行包装:
// compute/scalar_agg.go
package compute
import (
"context"
"github.com/apache/arrow/go/v13/arrow/compute/internal/kernels"
)
type aggFunction struct {
ScalarFunction
}
func Max(ctx context.Context, values Datum) (Datum, error) {
return CallFunction(ctx, "max", nil, values)
}
func Min(ctx context.Context, values Datum) (Datum, error) {
return CallFunction(ctx, "min", nil, values)
}
func Avg(ctx context.Context, values Datum) (Datum, error) {
return CallFunction(ctx, "avg", nil, values)
}
func Sum(ctx context.Context, values Datum) (Datum, error) {
return CallFunction(ctx, "sum", nil, values)
}
func RegisterScalarAggs(reg FunctionRegistry) {
maxFn := &aggFunction{*NewScalarFunction("max", Unary(), EmptyFuncDoc)}
for _, k := range kernels.ScalarAggKernels(kernels.AggMax) {
if err := maxFn.AddKernel(k); err != nil {
panic(err)
}
}
reg.AddFunction(maxFn, false)
minFn := &aggFunction{*NewScalarFunction("min", Unary(), EmptyFuncDoc)}
for _, k := range kernels.ScalarAggKernels(kernels.AggMin) {
if err := minFn.AddKernel(k); err != nil {
panic(err)
}
}
reg.AddFunction(minFn, false)
avgFn := &aggFunction{*NewScalarFunction("avg", Unary(), EmptyFuncDoc)}
for _, k := range kernels.ScalarAggKernels(kernels.AggAvg) {
if err := avgFn.AddKernel(k); err != nil {
panic(err)
}
}
reg.AddFunction(avgFn, false)
sumFn := &aggFunction{*NewScalarFunction("sum", Unary(), EmptyFuncDoc)}
for _, k := range kernels.ScalarAggKernels(kernels.AggSum) {
if err := sumFn.AddKernel(k); err != nil {
panic(err)
}
}
reg.AddFunction(sumFn, false)
}我们看到在这个源文件中,我们提供了供最终用户调用的Max等函数,这些函数是对kernel层scalar聚合函数的包装,通过CallFunction在registry中找到注册的kernel函数并执行它。
RegisterScalarAggs是用于向registry注册scalar聚合函数的函数。
3.3 在compute层将包装后的聚合函数注册到Registry中
我们修改一下compute/registry.go,在GetFunctionRegistry函数中增加对RegisterScalarAggs的调用,以实现对scalar聚合函数的注册:
// compute/registry.go
func GetFunctionRegistry() FunctionRegistry {
once.Do(func() {
registry = NewRegistry()
RegisterScalarCast(registry)
RegisterVectorSelection(registry)
RegisterScalarBoolean(registry)
RegisterScalarArithmetic(registry)
RegisterScalarComparisons(registry)
RegisterVectorHash(registry)
RegisterVectorRunEndFuncs(registry)
RegisterScalarAggs(registry)
})
return registry
}3.4 运行示例
最初运行arrow/compute-extension/max_aggregate_function.go示例的结果并非我们预期,而是一个全0的数组:
$go run max_aggregate_function.go
[0 0 0 0 0 0 0 0]经过print调试大法后,我发现compute/executor.go中的executeSpans的实现似乎有一个问题,我在arrow项目提了一个issue[12],并对executor.go做了如下修改:
diff --git a/go/arrow/compute/executor.go b/go/arrow/compute/executor.go
index d3f1a1fd4..e9bda7137 100644
--- a/go/arrow/compute/executor.go
+++ b/go/arrow/compute/executor.go
@@ -604,7 +604,7 @@ func (s *scalarExecutor) executeSpans(data chan<- Datum) (err error) {
return
}
- return s.emitResult(prealloc, data)
+ return s.emitResult(&output, data)
}
// fully preallocating, but not contiguously
(END)修改后,再运行arrow/compute-extension/max_aggregate_function.go示例就得到了正确的结果:
$go run max_aggregate_function.go
[35]3.5 To Be Done
到这里,我们从0到1的为arrow go实现的compute层添加了int64类型的scalar聚合函数的支持(以max为例),但这仅仅是验证了思路的可行性,上述对compute的修改可能是不合理的。此外,上述的改动不是production ready的,存在一些问题,比如:
Max返回的是array datam,而不是我们想要的scalar Datam;
仅支持int64,不支持其他类型的max聚合,比如float64、string等;
性能没有优化;
对chunked array类型的scalar datam尚未给出验证示例。
... ...
4. 小结
在本文中我们基于C++的资料,回顾了Arrow的一些基础抽象概念,从而对Arrow有了更为深刻的认知。之后,也是我们的重点,就是给出了compute层的结构以及基于该结构为compute层增加scalar聚合函数的一种思路和示例代码。
不过这种思路只是为了理解arrow的一种试验性方法,存在其不合理的地方,随着arrow演进,这种方法也许将不适用。同时,后续arrow官方可能会为go增加aggregate function的支持,那时请大家以官方实现为准。
C++版本Arrow实现完全支持各种聚合函数,考虑到Go arrow的实现参考了C++版本的思路,如果要为go arrow正式增加聚合函数支持,阅读c++源码并考虑迁移到Go才是正道。
本文示例代码可以在这里[13]下载,同时增加了scalar function的arrow的fork版本可以在我的github项目arrow-extend-compute1[14]下找到。
5. 参考资料
计算层 - https://arrow.apache.org/docs/cpp/compute.html
计算层教程 - https://arrow.apache.org/docs/cpp/tutorials/compute_tutorial.html
Arrow C++参考 - https://arrow.apache.org/docs/cpp/overview.html
Go unique kernel函数PR - https://github.com/apache/arrow/pull/34172
“Gopher部落”知识星球[15]旨在打造一个精品Go学习和进阶社群!高品质首发Go技术文章,“三天”首发阅读权,每年两期Go语言发展现状分析,每天提前1小时阅读到新鲜的Gopher日报,网课、技术专栏、图书内容前瞻,六小时内必答保证等满足你关于Go语言生态的所有需求!2023年,Gopher部落将进一步聚焦于如何编写雅、地道、可读、可测试的Go代码,关注代码质量并深入理解Go核心技术,并继续加强与星友的互动。欢迎大家加入!




著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址[16]:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
Gopher Daily(Gopher每日新闻)归档仓库 - https://github.com/bigwhite/gopherdaily
我的联系方式:
微博(暂不可用):https://weibo.com/bigwhite20xx
微博2:https://weibo.com/u/6484441286
博客:tonybai.com
github: https://github.com/bigwhite

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。
参考资料
[1]
《Go语言开发者的Apache Arrow使用指南:数据操作》: https://tonybai.com/2023/07/13/a-guide-of-using-apache-arrow-for-gopher-part4/
[2]从CSV读取的数据: https://tonybai.com/2023/07/13/a-guide-of-using-apache-arrow-for-gopher-part4/
[3]Arrow C++的文档: https://arrow.apache.org/docs/cpp/overview.html
[4]数据类型: https://tonybai.com/2023/06/25/a-guide-of-using-apache-arrow-for-gopher-part1
[5]数据类型决定了物理层内存数据的解释方法: https://tonybai.com/2022/12/18/go-type-system
[6]“高级数据结构”: https://tonybai.com/2023/07/08/a-guide-of-using-apache-arrow-for-gopher-part3/
[7]“高级数据结构”: https://tonybai.com/2023/07/08/a-guide-of-using-apache-arrow-for-gopher-part3/
[8]“高级数据结构”: https://tonybai.com/2023/07/08/a-guide-of-using-apache-arrow-for-gopher-part3/
[9]“数据类型”: https://tonybai.com/2023/06/25/a-guide-of-using-apache-arrow-for-gopher-part1
[10]“数据操作”: https://tonybai.com/2023/07/13/a-guide-of-using-apache-arrow-for-gopher-part4/
[11]“数据操作”: https://tonybai.com/2023/07/13/a-guide-of-using-apache-arrow-for-gopher-part4/
[12]arrow项目提了一个issue: https://github.com/apache/arrow/issues/36592
[13]这里: https://github.com/bigwhite/experiments/blob/master/arrow/compute-extension
[14]arrow-extend-compute1: https://github.com/bigwhite/arrow-extend-compute1
[15]“Gopher部落”知识星球: https://wx.zsxq.com/dweb2/index/group/51284458844544
[16]链接地址: https://m.do.co/c/bff6eed92687