对于仍在使用Kafka 2.8之前版本的团队来说,需要特别注意其强依赖外部ZooKeeper的特性。本文将完整演示传统架构下的安装流程,并对比新旧版本差异。
1 版本特性差异说明
1.1 2.8+ vs 2.8-核心区别
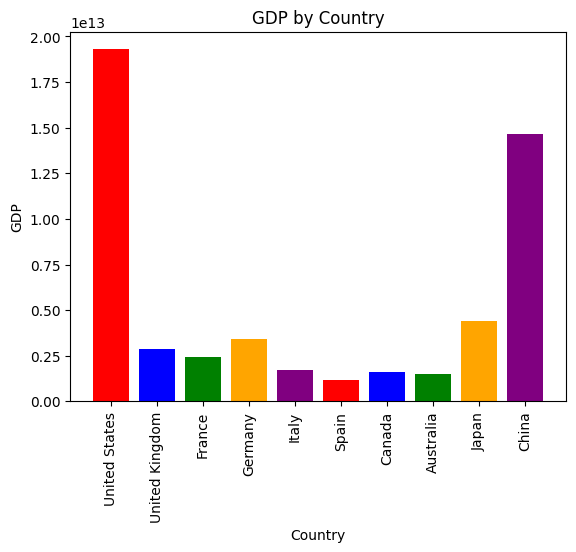
| 特性 | 2.8+版本 | 2.8-版本 |
| 协调服务 | 可选内置KRaft模式 | 强制依赖外部ZooKeeper集群 |
| 部署复杂度 | 单进程即可运行 | 需独立维护ZK集群 |
| 元数据性能 | 吞吐提升20%+ | 受ZK性能制约 |
| 推荐生产版本 | ≥3.0 | ≤2.7.x |
2 安装准备(以2.7.1为例)
2.1 组件下载
Kafka下载地址:Index of /dist/kafka/2.7.1
Zookeeper下载地址:Index of /dist/zookeeper
2.2. 解压安装包以及目录结构
# 解压kafka安装包
tar -zxvf kafka_2.13-2.7.1.tgz -C kafka_zk/
# 解压zk安装包
tar -zxvf apache-zookeeper-3.6.3-bin.tar.gz -C kafka_zk/
# 目录结构
[root@node5 kafka_zk]# tree -L 2
.
├── apache-zookeeper-3.6.3-bin
│ ├── bin
│ ├── conf
│ ├── data
│ ├── docs
│ ├── lib
│ ├── LICENSE.txt
│ ├── logs
│ ├── NOTICE.txt
│ ├── README.md
│ └── README_packaging.md
└── kafka_2.13-2.7.1
├── bin
├── config
├── libs
├── LICENSE
├── licenses
├── logs
├── NOTICE
└── site-docs
14 directories, 6 files
[root@node5 kafka_zk]#
# 各个目录用途解释
.
├── apache-zookeeper-3.6.3-bin # ZooKeeper 安装目录
│ ├── bin # ZooKeeper 可执行脚本(启动/停止/运维)
│ ├── conf # ZooKeeper 配置文件(zoo.cfg 等)
│ ├── data # ZooKeeper 数据存储目录(手动创建)
│ ├── docs # ZooKeeper 官方文档
│ ├── lib # ZooKeeper 运行时依赖库(JAR 文件)
│ ├── LICENSE.txt # Apache 2.0 许可证文件
│ ├── logs # ZooKeeper 运行日志(自动生成)
│ ├── NOTICE.txt # 第三方组件版权声明
│ ├── README.md # 项目说明文件
│ └── README_packaging.md # 打包说明文件
└── kafka_2.13-2.7.1 # Kafka 安装目录
├── bin # Kafka 管理脚本(启动/主题操作等)
├── config # Kafka 配置文件(server.properties 等)
├── libs # Kafka 依赖库(核心 JAR 文件)
├── LICENSE # Apache 2.0 许可证文件
├── licenses # 第三方依赖的许可证文件
├── logs # Kafka 运行日志(需手动创建或自动生成)
├── NOTICE # 项目版权声明
└── site-docs # Kafka 离线文档(HTML 格式)3 ZooKeeper独立部署
3.1 编辑配置文件
# 编辑conf/zoo.cfg:备份conf/zoo.cfg文件并添加如下内容
cp conf/zoo.cfg conf/zoo.cfg_bak
cat >conf/zoo.cfg<<EOF
# ZooKeeper 基础配置
tickTime=2000
initLimit=10
syncLimit=5
# 数据存储目录(需提前创建并赋予权限)
dataDir=/export/home/kafka_zk/apache-zookeeper-3.6.3-bin/data
dataLogDir=/export/home/kafka_zk/apache-zookeeper-3.6.3-bin/logs
# 客户端连接端口
clientPort=2181
# 单机模式无需集群配置
# server.1=ip:port:port (集群模式下需配置)
# 高级优化(可选)
maxClientCnxns=60
autopurge.snapRetainCount=3
autopurge.purgeInterval=24
admin.serverPort=8080
maxClientCnxns=60
EOF3.2 启动与验证
# 启动ZK(后台模式)
bin/zkServer.sh start conf/zoo.cfg
# 验证状态
echo srvr | nc 192.168.10.34 2181
[root@node5 apache-zookeeper-3.6.3-bin]# echo srvr | nc 192.168.10.34 2181
Zookeeper version: 3.6.3--6401e4ad2087061bc6b9f80dec2d69f2e3c8660a, built on 04/08/2021 16:35 GMT
Latency min/avg/max: 0/0.0/0
Received: 3
Sent: 2
Connections: 1
Outstanding: 0
Zxid: 0x0
Mode: standalone
Node count: 5
[root@node5 apache-zookeeper-3.6.3-bin]# 4 Kafka服务配置
4.1 编辑配置文件
# 编辑config/server.properties文件:备份文件并添加如下内容
cp config/server.properties config/server.properties_bak
cat >config/server.properties<<EOF
############################ 基础配置 #############################
# Broker唯一标识(单机保持默认)
broker.id=0
# 监听地址(必须配置为实际IP或主机名,不能用0.0.0.0)
listeners=PLAINTEXT://192.168.10.34:9092
advertised.listeners=PLAINTEXT://192.168.10.34:9092
# 日志存储目录(需提前创建并赋权)
log.dirs=/export/home/kafka_zk/kafka_2.13-2.7.1/logs
# ZooKeeper连接地址(单机模式)
zookeeper.connect=192.168.10.34:2181
############################# 单机特殊配置 #############################
# 强制内部Topic副本数为1(单机必须配置!)
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
# 禁用自动创建Topic(生产环境建议)
auto.create.topics.enable=false
############################# 性能优化 #############################
# 网络线程数(建议CPU核数)
num.network.threads=2
# IO线程数(建议2*CPU核数)
num.io.threads=4
# 日志保留策略
log.retention.hours=168 # 保留7天
log.segment.bytes=1073741824 # 单个日志段1GB
log.retention.check.interval.ms=300000 # 检查间隔5分钟
# 消息持久化
flush.messages=10000 # 每10000条消息刷盘
flush.ms=1000 # 每秒刷盘一次
############################# 高级调优 #############################
# Socket缓冲区大小
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
# 副本同步设置(单机可忽略)
default.replication.factor=1
min.insync.replicas=1
# 控制器配置
controller.socket.timeout.ms=30000
EOF4.2 编写启动脚本
# 创建bin/start-kafka.sh避免内存不足
#!/bin/bash
export KAFKA_HEAP_OPTS="-Xms1G -Xmx1G"
export JMX_PORT=9999
/export/home/kafka_zk/kafka_2.13-2.7.1/bin/kafka-server-start.sh /export/home/kafka_zk/kafka_2.13-2.7.1/config/server.propertieschmod +x bin/start-kafka.sh4.3 启动服务并验证
# 启动
/export/home/kafka_zk/kafka_2.13-2.7.1/bin/start-kafka.sh# 创建topic并查看详情
# 创建名为test的Topic,1分区1副本
/export/home/kafka_zk/kafka_2.13-2.7.1/bin/kafka-topics.sh --create \
--bootstrap-server 192.168.10.34:9092 \
--replication-factor 1 \
--partitions 1 \
--topic test
[root@node5 ~]# /export/home/kafka_zk/kafka_2.13-2.7.1/bin/kafka-topics.sh --create \
> --bootstrap-server 192.168.10.34:9092 \
> --replication-factor 1 \
> --partitions 1 \
> --topic test
Created topic test.
[root@node5 ~]#
# 查看Topic详情
/export/home/kafka_zk/kafka_2.13-2.7.1/bin/kafka-topics.sh --describe --topic test --bootstrap-server 192.168.10.34:9092
[root@node5 ~]# /export/home/kafka_zk/kafka_2.13-2.7.1/bin/kafka-topics.sh --describe --topic test --bootstrap-server 192.168.10.34:9092
Topic: test PartitionCount: 1 ReplicationFactor: 1 Configs: min.insync.replicas=1,segment.bytes=1073741824
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
[root@node5 ~]# 5 版本特定问题解决
5.1 ZooKeeper连接超时
现象:Session expired错误
# 增加server.properties参数
zookeeper.session.timeout.ms=18000
zookeeper.connection.timeout.ms=150005.2. 磁盘写性能低下
# 禁用完全刷盘(牺牲部分可靠性)
log.flush.interval.messages=10000
log.flush.interval.ms=10005.3 监控指标缺失
# 启用JMX导出
KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9999"
/export/home/kafka_zk/kafka_2.13-2.7.1/bin/kafka-server-start.sh /export/home/kafka_zk/kafka_2.13-2.7.1/bin/server.properties