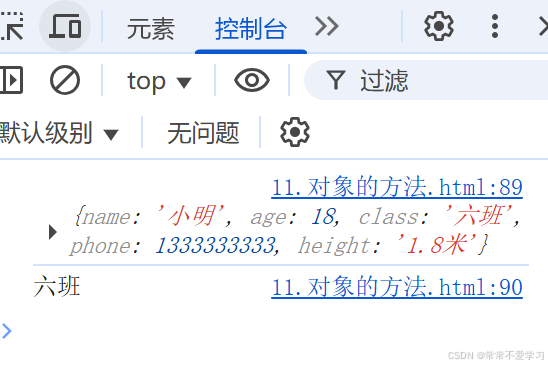
4月初,DeepSeek 提交到 arXiv 上的最新论文正在 AI 社区逐渐升温。

论文核心内容理解
DeepSeek与清华大学联合发布的论文《奖励模型的推理时Scaling方法及其在大规模语言模型中的应用》,核心在于提出一种新的推理时Scaling方法,即通过动态调整奖励机制,而非改变模型参数,来提升大规模语言模型(LLM)的推理能力。这种方法突破了传统依赖强化学习(RL)在训练阶段优化模型性能的局限,为LLM推理能力的提升提供了全新方法论。
Scaling 的具体对象
论文中的"Scaling"主要指推理计算资源的扩展,而非模型大小(参数量)或数据规模的扩展。具体来说,是在推理过程中通过增加计算资源,如多次采样、并行采样等,来提升模型的推理性能。
推理时的 Scaling 策略
论文提出了多种推理时Scaling策略:
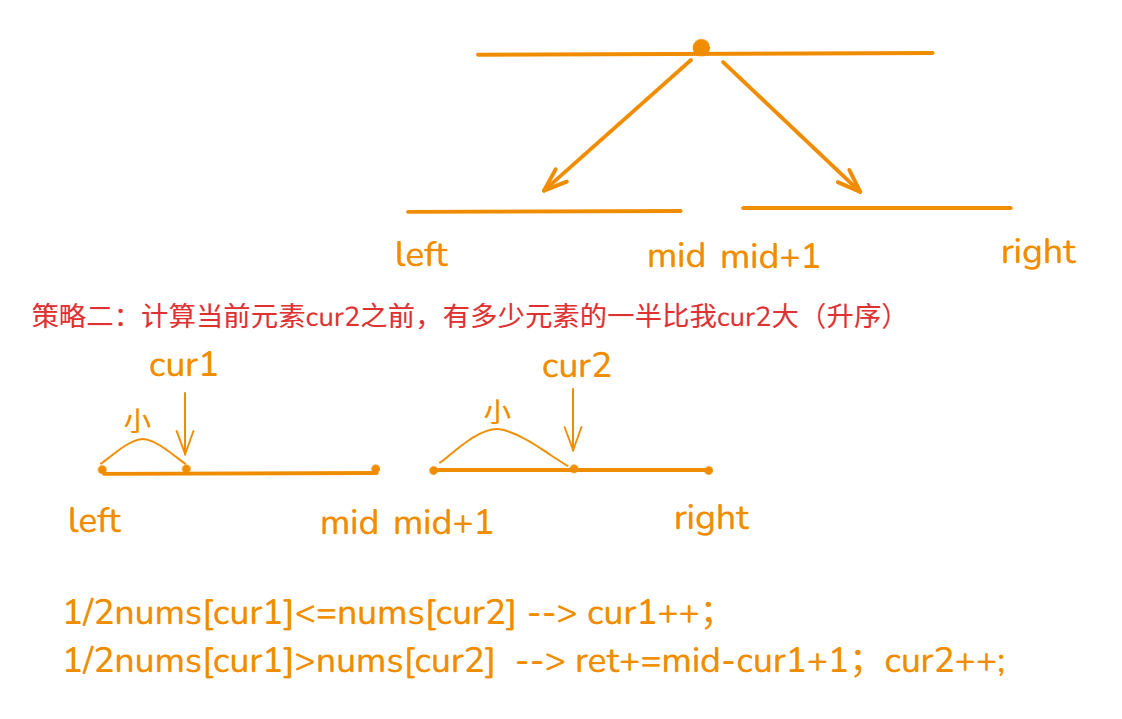
- 多次采样与并行采样:通过多次采样生成不同的原则集和相应的批评,然后投票选出最终的奖励。更大规模的采样可以更准确地判断具有更高多样性的原则,并以更细的粒度输出奖励。
- 自我原则批评调整(SPCT):包含拒绝式微调(作为冷启动阶段)和基于规则的在线强化学习,通过不断优化生成的准则和评论,增强泛化型奖励生成能力,促使奖励模型在推理阶段展现良好扩展能力。
- 元奖励模型(Meta Reward Model):引入多层级奖励评估体系,统一处理单响应、多响应及对比评分的多样化场景,进一步提升推理效果。
目标优化
推理时进行Scaling的主要目标是提升模型在推理阶段的性能,具体包括:
- 提高模型输出的逻辑一致性和事实准确性。
- 增强模型在复杂多变任务中的适应性和稳定性,如数学推理、代码生成等任务。
- 在不增加模型参数的情况下,通过动态调整奖励机制,使模型能够更好地处理不同类型的输入和任务。
适用场景
论文提出的Scaling策略主要适用于以下场景:
- 模型类型:主要适用于大规模语言模型(LLM),尤其是基于奖励模型(RM)的LLM。
- 任务类型:适用于需要复杂推理的任务,如数学推理、代码生成等,这些任务需要模型在推理过程中进行多步思考和逻辑判断。
- 应用场景:既可用于在线服务,也可用于离线推理。对于在线服务,能够实时提升模型的推理性能;对于离线推理,可以通过增加计算资源来获得更准确的结果。
理论分析
论文从多个角度对Scaling策略进行了理论分析:
- 奖励机制的优化:通过SPCT方法,模型能够自适应生成高质量的评判原则和批评内容,从而优化奖励机制。这种优化基于在线强化学习,能够不断提升模型的泛化能力和适应性。
- 计算资源的利用:通过多次采样和并行采样,模型能够在推理阶段充分利用计算资源,提高推理的准确性和效率。这种策略在计算复杂度上具有一定的优势,能够在有限的资源内获得更好的性能。
- 模型性能的提升:论文通过理论分析证明,推理阶段的Scaling策略能够显著提升模型的性能,甚至超过通过增加模型规模所带来的训练效果提升。
实验验证
论文进行了充分的实验验证,实验结果支持论文的结论:
- 实验设置:研究者们构建了DeepSeek-GRM-27B模型,并将其与多个现有方法和模型进行比较。实验涵盖了多个综合RM基准测试,包括数学推理和代码生成等任务。
- 实验结果:SPCT方法显著提高了GRM的质量和可扩展性,在多个基准测试中优于现有方法和模型。例如,在GSM8K数学推理测试中,准确率提升了12%;在代码生成任务中,执行成功率提高了19%。
- 与大规模模型的比较:研究者们还将DeepSeek-GRM-27B的推理时间扩展性能与多达671B参数的较大模型进行了比较,发现它在模型大小上可以获得比训练时间扩展更好的性能。
创新性
论文的创新点主要体现在以下几个方面:
- 提出新的Scaling方法:首次提出“推理时Scaling”这一概念,强调通过动态调整奖励机制来提升模型的推理能力,而非传统的通过增加模型参数或训练数据。
- SPCT方法:提出了一种新的学习方法——自我原则批评调整(SPCT),用于提升通用奖励模型在推理阶段的可扩展性。该方法通过拒绝式微调和基于规则的在线强化学习,显著提高了模型的性能。
- 元奖励模型:引入了元奖励模型(Meta Reward Model),进一步优化了推理过程中的奖励机制,提升了模型在复杂任务中的表现。
- 实验验证:通过在多个基准测试中的实验验证,证明了所提出方法的有效性和优越性,为LLM推理能力的提升提供了有力的证据。