其实应该先写个influxdb初探的,但是当时没有时间·····时间都用来养龟养鱼了··还有摸鱼了。
本篇先讲我是如何将influxdb数据转移到clickhouse的,再记录influxdb的一些常用命令
1、influxdb数据转移到clickhouse
influxdb不管是查询还是导出的数据格式都很麻烦,说一下我一波三折的经历。
- 起初我是在java中先查询influxdb,再转换并组成sql,导入tdengine,后来调研发现tdengine也很烦,没有很好的社区环境,都是加群,然后几乎不理你,可能它们太忙了,毕竟我也没交钱不是?,代码写的我都看不下去,因为组sql的时候太难受了,最后虽然写成了,但是查询influxdb也特别慢,后来就搁置了
- 后来调研了clickhouse,感觉非常不错,但是想到组sql就怵,再次搁置
- 再后来有一次,想把生产的influxdb数据转到测试环境,了解到influxdb可以导出数据成line protocol的格式,灵感来了,我可以写程序,一天一天导出成文件,然后读取,转换,再以文件形式导入CH,这样就避免了组sql,也避免了很多数据格式的转换(比如string转int,float转int之类的)。
总之,思路就是写脚本一天一天的导出influxdb的数据,用python读取,pivot转换成关系数据库的csv的格式文件,导入CH即可。
1)导出
导出的命令:
官网链接:https://docs.influxdata.com/influxdb/v2.1/migrate-data/migrate-oss/
influxd inspect export-lp \
--bucket-id fffffffffffff\
--engine-path /data/db/influxdb/engine \
--output-path influxdb_export-${str}.gz \
--measurement battery \
--start 2023-07-01T00:00:00Z \
--end 2023-07-01T23:59:59Z \
--compress
导出的数据是gzip压缩后的数据,格式是 line protocol
例如:
battery,batteryCode=ffffffffffffff availableEnergy=58.6719970703125 1688169600000000000
一行只有一个字段,battery是measurement名称,batteryCode是tag,可能有多个,我这里只有一个,availableEnergy是字段名称,1688169600000000000是时间戳
脚本参考上一篇文章
2)转换
这里使用python 的pandas库转换,比较方便
transformData.py
import csv
import time
start_time = time.time()
with open('influxdb_export', 'r') as f:
data = f.readlines()
# index = batteryCode-time
header = ['index', 'columns', 'value']
rows = []
for line in data:
batteryCode=ss[0]
timestamp = ss[2]
column = ss[1].split("=")[0]
value = ss[1].split("=")[1]
rows.append([f"{batteryCode}-{timestamp}", column, value])
with open('output.csv', 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow(header)
writer.writerows(rows)
end_time = time.time()
run_time = end_time - start_time
print(f"代码运行时间:{run_time:.2f}秒,处理数据:{len(rows)}条")
输出的output.csv格式为:
index,columns,value
fffffffffff-1688169600000000000,availableEnergy,58.6719970703125
fffffffffff-1688169600000000000,bbbbbbb,58.6719970703125
fffffffffff-1688169600000000000,ccccccc,58.6719970703125
fffffffffff-1688169600000000000,dddddd,58.6719970703125
转换成这种格式是为了方便pivot,把行转为列
一个电池code和时间肯定是唯一的,所以把batteryCode-timestamp作为index
pivotData.py
import pandas as pd
import time
start_time = time.time()
# 读取csv文件
df = pd.read_csv('output.csv',dtype=str)
# 将index列拆分为batteryCode和timestamp两列
df[['batteryCode', 'timestamp']] = df['index'].str.split('-', expand=True)
# 透视表格
pivot_df = df.pivot(index=['batteryCode', 'timestamp'], columns='columns', values='value')
# 重置索引
pivot_df = pivot_df.reset_index()
# 保存到csv文件
pivot_df.to_csv('outputs.csv', index=False)
end_time = time.time()
run_time = end_time - start_time
print(f"代码运行时间:{run_time:.2f}秒")
这里只是为了pivot,分成两个脚本是为了观察中间输出的文件格式是否正确。我在本地测试的原始文件一天是500M,两个脚本都是用时20秒左右,如果合成一个脚本,没有中间的IO,应该会快很多。
转换后的数据就会是正常的csv了。
batteryCode,timestamp,availableEnergy,aaa,bbb,ccc,ddd
00VPB13111S0A1CCE0000001,1688169600000000000,58.6719970703125,9i,687.7999877929688,0,0i,31
这里介绍下pivot:
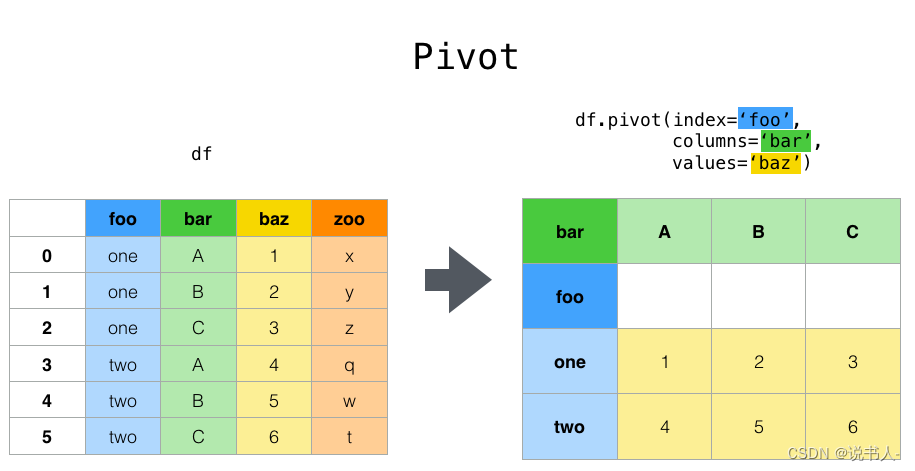
很方便的函数,中文叫透视,我觉得很形象。excel也有类似函数
官网链接:https://www.pypandas.cn/docs/user_guide/reshaping.html
3)导入
导入就简单了哈
# 建库建表
CREATE DATABASE IF NOT EXISTS device
CREATE TABLE device.battery
(
batteryCode String,
timestamp DateTime,
availableEnergy String,
aaaaa String,
bbbbb String,
cccccc String,
dddddd String
)
ENGINE = MergeTree()
PRIMARY KEY (batteryCode, timestamp)
# 导入
clickhouse-client --port 9001 -q "INSERT INTO device.battery FORMAT CSV" < influx_output.csv
这里我的端口是9001,默认是9000,所以要显式设置
补充一下,真实导出的是 .gz 的 压缩文件,python可以直接读取压缩文件:
import gzip
with gzip.open('file.gz', 'rt') as f:
for line in f:
# 处理每一行数据
print(line.strip())
2、记录一些influxdb的常用命令
直接在influxdb里面pivot
from(bucket: "device")
|> range(start: 2023-02-28T00:00:00Z, stop: 2023-02-28T01:00:00Z)
|> filter(fn: (r) => r._measurement == "car" )
|> drop(columns: ["_start", "_stop", "_measurement"])
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
|> group(columns: ["_time"])
从influxdb导出
influxd inspect export-lp \
--bucket-id f8f18a96df05f4ee \
--engine-path /data/db/influxdb/engine \
--output-path influxdb_export-${str}.gz \
--measurement battery \
--start 2023-07-${str}T00:00:00Z \
--end 2023-07-${str}T23:59:59Z \
--compress
必须在influxdb服务器上导出,因为要指定engine-path。
导入influxdb
influx write \
--bucket device_from_prod \
--file /root/influxdbdata/influxdb_export.gz
count
from(bucket: "test")
|> range(start: -2d,stop: 2d)
|> filter(fn: (r) => r._field == "current")
|> group(columns: ["current"])
|> count()
查看日志
journalctl -u influxdb -n 1000
本地创建config
influx config create --active\
-n dev-config \
-u http://localhost:8086 \
-p rootdev:rootdev\
-o hph
压缩命令
zip backup.zip influxdb_export-*.gz
backup.zip 是压缩后的名称,后面是要压缩的文件,我老是搞反