目录
1.最简单的文件上传
2.拖拽+粘贴+样式优化
3.断点续传+秒传+进度条
文件切片
计算hash
断点续传+秒传(前端)
断点续传+秒传(后端)
进度条
4.抽样hash和webWorker
抽样hash(md5)
webWorker
时间切片
5.文件类型判断
通过文件头判断文件类型
6.异步并发数控制(重要)
7.并发错误重试
8.慢启动控制
9.碎片清理
后记
参考资料
本文适合有一定node后端基础的前端同学,如果对后端完全不了解请恶补前置知识。
废话不多说,直接进入正题。
我们来看一下,各个版本的文件上传组件大概都长什么样
| 等级 | 功能 |
|---|---|
| 青铜-垃圾玩意 | 原生+axios.post |
| 白银-体验升级 | 粘贴,拖拽,进度条 |
| 黄金-功能升级 | 断点续传,秒传,类型判断 |
| 铂金-速度升级 | web-worker,时间切片,抽样hash |
| 钻石-网络升级 | 异步并发数控制,切片报错重试 |
| 王者-精雕细琢 | 慢启动控制,碎片清理等等 |
1.最简单的文件上传
文件上传,我们需要获取文件对象,然后使用formData发送给后端接收即可
function upload(file){
let formData = new FormData();
formData.append('newFile', file);
axios.post(
'http://localhost:8000/uploader/upload',
formData,
{ headers: { 'Content-Type': 'multipart/form-data' } }
)
}2.拖拽+粘贴+样式优化
懒得写,你们网上找找库吧,网上啥都有,或者直接组件库解决问题
3.断点续传+秒传+进度条
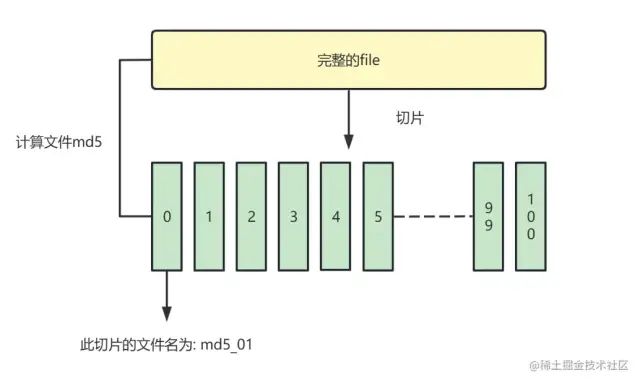
文件切片
我们通过将一个文件分为多个小块,保存到数组中.逐个发送给后端,实现断点续传。
// 计算文件hash作为id
const { hash } = await calculateHashSample(file)
//todo 生成文件分片列表
// 使用file.slice()将文件切片
const fileList = [];
const count = Math.ceil(file.size / globalProp.SIZE);
const partSize = file.size / count;
let cur = 0 // 记录当前切片的位置
for (let i = 0; i < count; i++) {
let item = {
chunk: file.slice(cur, cur + partSize),
filename: `${hash}_${i}`
};
fileList.push(item);
}计算hash
为了让后端知道,这个切片是某个文件的一部分,以便聚合成一个完整的文件。我们需要计算完整file的唯一值(md5),作为切片的文件名。
// 通过input的event获取到file
<input type="file" @change="getFile">
// 使用SparkMD5计算文件hash,读取文件为blob,计算hash
let fileReader = new FileReader();
fileReader.onload = (e) => {
let hexHash = SparkMD5.hash(e.target.result);
console.log(hexHash);
};断点续传+秒传(前端)
我们此时有保存了100个文件切片的数组,遍历切片连续向后端发送axios.post请求即可。设置一个开关,实现启动-暂停功能。
如果我们传了50份,关掉了浏览器怎么办?
此时我们需要后端配合,在上传文件之前,先检查一下后端接收了多少文件。
当然,如果发现后端已经上传过这个文件,直接显示上传完毕(秒传)
// 解构出已经上传的文件数组 文件是否已经上传完毕
// 通过文件hash和后缀查询当前文件有多少已经上传的部分
const {isFileUploaded, uploadedList} = await axios.get(
`http://localhost:8000/uploader/count
?hash=${hash}
&suffix=${fileSuffix}`
)断点续传+秒传(后端)
至于后端的操作,就比较简单了
-
根据文件hash创建文件夹,保存文件切片
-
检查某文件的上传情况,通过接口返回给前端
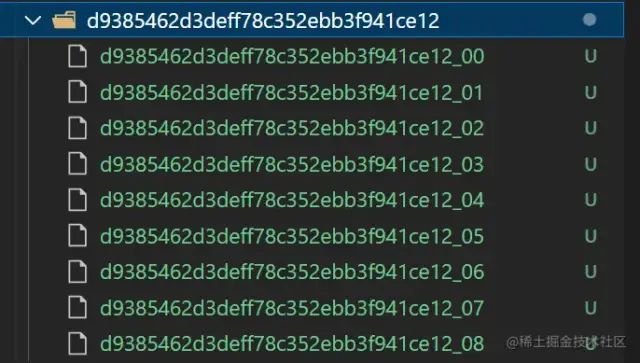
例如以下文件切片文件夹
//! --------通过hash查询服务器中已经存放了多少份文件(或者是否已经存在文件)------
function checkChunks(hash, suffix) {
//! 查看已经存在多少文件 获取已上传的indexList
const chunksPath = `${uploadChunksDir}${hash}`;
const chunksList = (fs.existsSync(chunksPath) && fs.readdirSync(chunksPath)) || [];
const indexList = chunksList.map((item, index) =>item.split('_')[1])
//! 通过查询文件hash+suffix 判断文件是否已经上传
const filename = `${hash}${suffix}`
const fileList = (fs.existsSync(uploadFileDir) && fs.readdirSync(uploadFileDir)) || [];
const isFileUploaded = fileList.indexOf(filename) === -1 ? false : true
console.log('已经上传的chunks', chunksList.length);
console.log('文件是否存在', isFileUploaded);
return {
code: 200,
data: {
count: chunksList.length,
uploadedList: indexList,
isFileUploaded: isFileUploaded
}
}
}
进度条
实时计算一下已经成功上传的片段不就行了,自行实现吧
4.抽样hash和webWorker
因为上传前,我们需要计算文件的md5值,作为切片的id使用。md5的计算是一个非常耗时的事情,如果文件过大,js会卡在计算md5这一步,造成页面长时间卡顿。
我们这里提供三种思路进行优化:
抽样hash(md5)
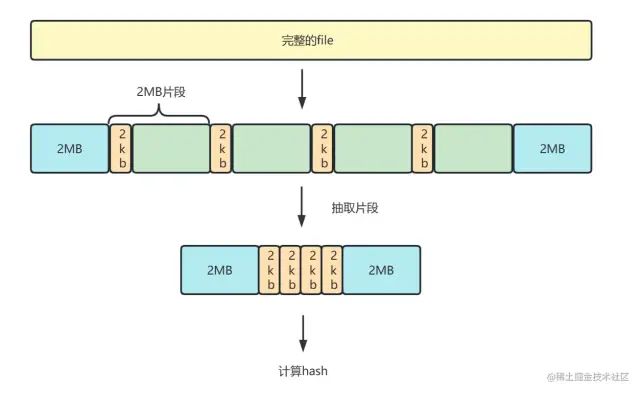
抽样hash是指,我们截取整个文件的一部分,计算hash,提升计算速度。
1. 我们将file解析为二进制buffer数据,
2. 抽取文件头尾2mb, 中间的部分每隔2mb抽取2kb
3. 将这些片段组合成新的buffer,进行md5计算。
图解:
样例代码
//! ---------------抽样md5计算-------------------
function calculateHashSample(file) {
return new Promise((resolve) => {
//!转换文件类型(解析为BUFFER数据 用于计算md5)
const spark = new SparkMD5.ArrayBuffer();
const { size } = file;
const OFFSET = Math.floor(2 * 1024 * 1024); // 取样范围 2M
const reader = new FileReader();
let index = OFFSET;
// 头尾全取,中间抽2字节
const chunks = [file.slice(0, index)];
while (index < size) {
if (index + OFFSET > size) {
chunks.push(file.slice(index));
} else {
const CHUNK_OFFSET = 2;
chunks.push(file.slice(index, index + 2),
file.slice(index + OFFSET - CHUNK_OFFSET, index + OFFSET)
);
}
index += OFFSET;
}
// 将抽样后的片段添加到spark
reader.onload = (event) => {
spark.append(event.target.result);
resolve({
hash: spark.end(),//Promise返回hash
});
}
reader.readAsArrayBuffer(new Blob(chunks));
});
}webWorker
除了抽样hash,我们可以另外开启一个webWorker线程去专门计算md5。
webWorker: 就是给JS创造多线程运行环境,允许主线程创建worker线程,分配任务给后者,主线程运行的同时worker线程也在运行,相互不干扰,在worker线程运行结束后把结果返回给主线程。
具体使用方式可以参考MDN或者其他文章:
使用 Web Workers \- Web API 接口参考 | MDN \(mozilla.org\)[1]
一文彻底学会使用web worker \- 掘金 \(juejin.cn\)[2]
时间切片
熟悉React时间切片的同学也可以去试一试,不过个人认为这个方案没有以上两种好。
不熟悉的同学可以自行掘金一下,文章还是很多的。这里就不多做论述,只提供思路。
时间切片也就是传说中的requestIdleCallback,requestAnimationFrame 这两个API了,或者高级一点自己通过messageChannel去封装。
切片计算hash,将多个短任务分布在每一帧里,减少页面卡顿。
5.文件类型判断
简单一点,我们可以通过input标签的accept属性,或者截取文件名来判断类型
<input id="file" type="file" accept="image/*" />
const ext = file.name.substring(file.name.lastIndexOf('.') + 1);当然这种限制可以简单的通过修改文件后缀名来突破,并不严谨。
通过文件头判断文件类型
我们将文件转化为二进制blob,文件的前几个字节就表示了文件类型,我们读取进行判断即可。
比如如下代码
// 判断是否为 .jpg
async function isJpg(file) {
// 截取前几个字节,转换为string
const res = await blobToString(file.slice(0, 3))
return res === 'FF D8 FF'
}
// 判断是否为 .png
async function isPng(file) {
const res = await blobToString(file.slice(0, 4))
return res === '89 50 4E 47'
}
// 判断是否为 .gif
async function isGif(file) {
const res = await blobToString(file.slice(0, 4))
return res === '47 49 46 38'
}当然咱们有现成的库可以做这件事情,比如 file-type 这个库
file-type \- npm \(npmjs.com\)[3]
6.异步并发数控制(重要)
我们需要将多个文件片段上传给后端,总不能一个个发送把?我们这里使用TCP的并发+实现控制并发进行上传。
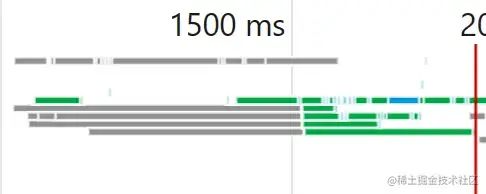
首先我们将100个文件片段都封装为axios.post函数,存入任务池中
-
创建一个并发池,同时执行并发池中的任务,发送片段
-
设置计数器i,当i<并发数时,才能将任务推入并发池
-
通过promise.race方法 最先执行完毕的请求会被返回 即可调用其.then方法 传入下一个请求(递归)
-
当最后一个请求发送完毕 向后端发起请求 合并文件片段
图解

代码
//! 传入请求列表 最大并发数 全部请求完毕后的回调
function concurrentSendRequest(requestArr: any, max = 3, callback: any) {
let i = 0 // 执行任务计数器
let concurrentRequestArr: any[] = [] //并发请求列表
let toFetch: any = () => {
// (每次执行i+1) 如果i=arr.length 说明是最后一个任务
// 返回一个resolve 作为最后的toFetch.then()执行
// (执行Promise.all() 全部任务执行完后执行回调函数 发起文件合并请求)
if (i === requestArr.length) {
return Promise.resolve()
}
//TODO 执行异步任务 并推入并发列表(计数器+1)
let it = requestArr[i++]()
concurrentRequestArr.push(it)
//TODO 任务执行后 从并发列表中删除
it.then(() => {
concurrentRequestArr.splice(concurrentRequestArr.indexOf(it), 1)
})
//todo 如果并发数达到最大数,则等其中一个异步任务完成再添加
let p = Promise.resolve()
if (concurrentRequestArr.length >= max) {
//! race方法 返回fetchArr中最快执行的任务结果
p = Promise.race(concurrentRequestArr)
}
//todo race中最快完成的promise,在其.then递归toFetch函数
if (globalProp.stop) { return p.then(() => { console.log('停止发送') }) }
return p.then(() => toFetch())
}
// 最后一组任务全部执行完再执行回调函数(发起合并请求)(如果未合并且未暂停)
toFetch().then(() =>
Promise.all(concurrentRequestArr).then(() => {
if (!globalProp.stop && !globalProp.finished) { callback() }
})
)
}
7.并发错误重试
-
使用catch捕获任务错误,上述axios.post任务执行失败后,重新把任务放到任务队列中
-
给每个任务对象设置一个tag,记录任务重试的次数
-
如果一个切片任务出错超过3次,直接reject。并且可以直接终止文件传输
8.慢启动控制
由于文件大小不一,我们每个切片的大小设置成固定的也有点略显笨拙,我们可以参考TCP协议的慢启动策略。设置一个初始大小,根据上传任务完成的时候,来动态调整下一个切片的大小, 确保文件切片的大小和当前网速匹配。
-
·chunk中带上size值,不过进度条数量不确定了,修改createFileChunk, 请求加上时间统计
-
·比如我们理想是30秒传递一个。初始大小定为1M,如果上传花了10秒,那下一个区块大小变成3M。如果上传花了60秒,那下一个区块大小变成500KB 以此类推
9.碎片清理
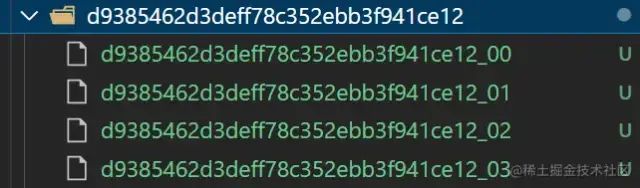
如果用户上传文件到一半终止,并且以后也不传了,后端保存的文件片段也就没有用了。
我们可以在node端设置一个定时任务setInterval,每隔一段时间检查并清理不需要的碎片文件。
可以使用 node-schedule 来管理定时任务,比如每天检查一次目录,如果文件是一个月前的,那就直接删除把。
垃圾碎片文件
后记
以上就是一个完整的比较高级的文件上传组件的全部功能,希望各位有耐心看到这里的新手小伙伴能够融会贯通。每天进步一点点。
参考资料
[1] https://developer.mozilla.org/zh-CN/docs/Web/API/Web_Workers_API/Using_web_workers: https://link.juejin.cn?target=https%3A%2F%2Fdeveloper.mozilla.org%2Fzh-CN%2Fdocs%2FWeb%2FAPI%2FWeb_Workers_API%2FUsing_web_workers
[2] https://juejin.cn/post/7139718200177983524: https://juejin.cn/post/7139718200177983524
[3] https://www.npmjs.com/package/file-type: https://link.juejin.cn?target=https%3A%2F%2Fwww.npmjs.com%2Fpackage%2Ffile-type