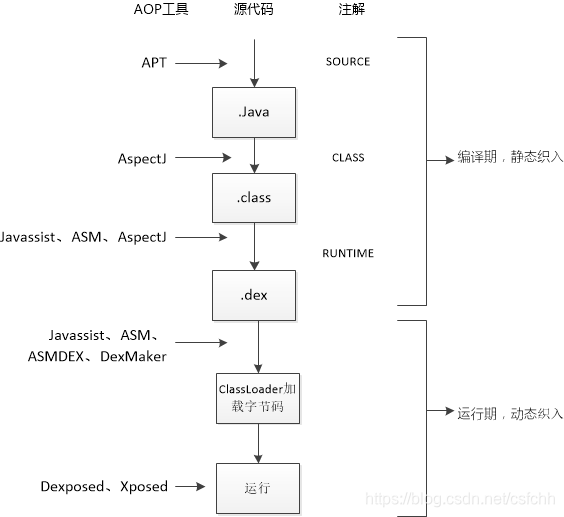
又搬来一个简单高效的知识蒸馏技术哦~~直接复用教师分类器还能显著减小性能差距的~
在分类器的上一层通过特征对齐来训练学生模型,并直接复用教师分类器到学生模型中,再使用L2损失进行特征对齐。来自浙江大学的复用教师模型的方法哦~~ 浙大好厉害~~
论文名称: Knowledge Distillation with the Reused Teacher Classifier
论文地址:https://arxiv.org/pdf/2203.14001.pdf
给定一个参数量较大的教师模型,知识蒸馏 (KD) 的目标是帮助另一个参数量较少的学生模型获得与较大的教师模型相似的泛化能力。实现这一目标的一种直接方法是,给定相同的输入,尽量减少它们输出预测结果的差距。原始 KD 策略的一个不足之处是,教师模型和学生模型性能的差距依然很大。
之前有一些相关的知识蒸馏的方法,如[1][2][3][4][5][6]。这些方法利用了一些中间层特征的信息,同时也获益于精心设计的知识蒸馏的特征 (比如蒸馏注意力[7],蒸馏相关性[8][9],蒸馏教师模型和学生模型的互信息[10]等)。
这些知识蒸馏策略的确能够带来某些性能的提升,但是它们要么基于不那么鲁棒的超参,要么依赖于精心设计的蒸馏特征。
本文作者提出了一个简单的知识蒸馏技术,可以显著弥合教师和学生模型之间的性能差距,称为 SimKD,如下图1所示。作者认为,教师模型强大的预测能力不仅归功于更强的特征提取能力,最后的分类器 (Classifier) 也同样重要。基于这一点,作者在分类器的上一层通过特征对齐 (Feature Alignment) 来训练学生模型,并直接复用 (Reuse) 教师分类器到学生模型中。

图1:SimKD 简介
原始 KD 方法
深度神经网络模型可以看成是一个特征提取器 + 最后的分类层。特征提取器通常是由很多个非线性层组成,分类层一般是由一个 Fully Connected Layer 加上一个 softmax 激活函数构成。它们的参数通过反向传播算法更新。


图2:原始 KD 方法
Simple KD 方法
Simple KD 方法是基于特征蒸馏方法,特征蒸馏方法如下图3所示,特征蒸馏主要是收集和传输 teacher 和 student 模型的额外梯度信息,以更好地训练学生的特征 Encoder。然而,特征蒸馏方法很大程度上依赖于特征类型的选择,比如是蒸馏注意力特征还是隐藏层特征。同时,由于涉及到的特征类型较多,特征蒸馏还对超参数的选择比较敏感。结合以上两个缺点,特征蒸馏方法比较耗时,同时我们很难直接做出判断哪种模型适合什么类型的特征蒸馏。
 图3:特征蒸馏技术
图3:特征蒸馏技术
SimKD 是一种简单的知识蒸馏技术,如下图4所示,它一个关键组成部分是 "分类器复用" 操作,即我们直接借用预先训练好的教师分类器进行学生推理,而不是训练一个新的分类器。这样就不需要用标签信息来计算交叉熵损失,使得特征对齐损失成为产生梯度的唯一来源。
作者认为,精心训练好的教师模型中包含的判别能力是非常重要的,但在很多 KD 方法中被很大程度上忽略了。作者是这么理解的:当一个模型被要求处理几个具有不同数据分布的任务,一个基本的做法是冻结或共享一些浅层作为跨不同任务的特征提取器,同时微调最后一层分类器以学习特定于任务的信息[11][12]。在这种单模型多任务的设置中,现有的研究一般认为:
-
task-invariant 的信息可以在不同模型之间共享,而 task-specific 的信息则需要独立识别,通常由最终的分类器进行识别。
推广到 KD 领域,不同能力的教师和学生模型在相同的数据集上进行训练,作者认为:
-
capability-invariant 的信息可以在教师和学生模型之间共享,而 capability-specific 的信息则学生模型很难独立地学好,通常这些信息在网络的深层,尤其是最后的分类器。
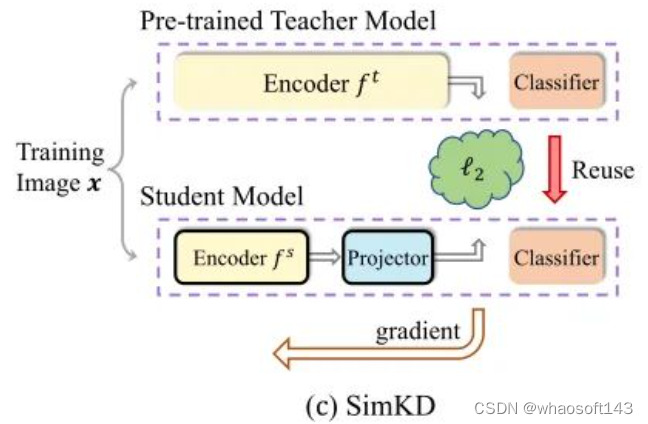
图4:Simple KD 方法

通过这种简单的技术,KD 中的性能下降将得到极大的缓解。而且,来自预训练的教师模型的特征复用允许合并更多的层,不限于最终的分类器。通常情况下,重用的层数越多,学生的准确率越高,但是会增加额外的推理负担。
与其他 KD 方法的精度对比
数据集:CIFAR100,ImageNet。优化器:SGD 0.9 Momentum,CIFAR100 和 ImageNet 分别训练 240 和 120 Epochs。
对比的其他 KD 方法:FitNet,AT,SP, VID,CRD,SRRL,SemCKD

SimKD 的性能始终优于所有竞争对手,在某些情况下提高相当显著。例如,对于 "ResNet8x4 & ResNet-32x4" 的组合,SimKD 在 ImageNet 上的准确率提高了 3.66%。作者还发现,在 "ResNet-8x4 & WRN-40-2" 和 "ShuffleNetV2 & ResNet110x2" 组合的情况下,用 SimKD 训练的学生模型比教师模型的精度更高,这有点令人困惑,因为即使是特征对齐损失训练到了零,也只能保证它们的准确性完全相同。自蒸馏 (Self-distillation) 的一个可能解释是,式3损失函数可以帮助特征重建,或许可以帮助学生模型变得更稳健,从而获得更好的结果。
分类器复用操作分析
"分类器重用" 操作是本文取得成功的关键。为了更好地理解它的作用,作者用两种可选策略进行了几个实验来处理学生模型的 Encoder 和分类器:
(1) 联合训练:不再复用教师模型的分类器,而联合训练学生模型的 Encoder 和分类器

图8:联合训练实验结果
(2) 顺序训练:先使用3式的损失函数训练好学生的特征提取器,再冻结其参数,即冻结提取的特征,用常规训练过程训练随机初始化的学生分类器
以上做法与自监督训练中的 Linear Probing 做法一致。实验结果如下图9所示。可以发现,除了 "WRN-40-1 & WRN-40-2" 和 "ResNet-110/116 & ResNet-110x2",其他学生模型的测试精度出现了急剧下降。而几次调优初始学习速率只对性能产生了轻微的影响。图9的结果表明,即使提取的特征已经对齐,训练一个令人满意的学生分类器仍然是一个挑战。相比之下,直接重用预先训练好的教师分类器显得简单,而且性价比高。
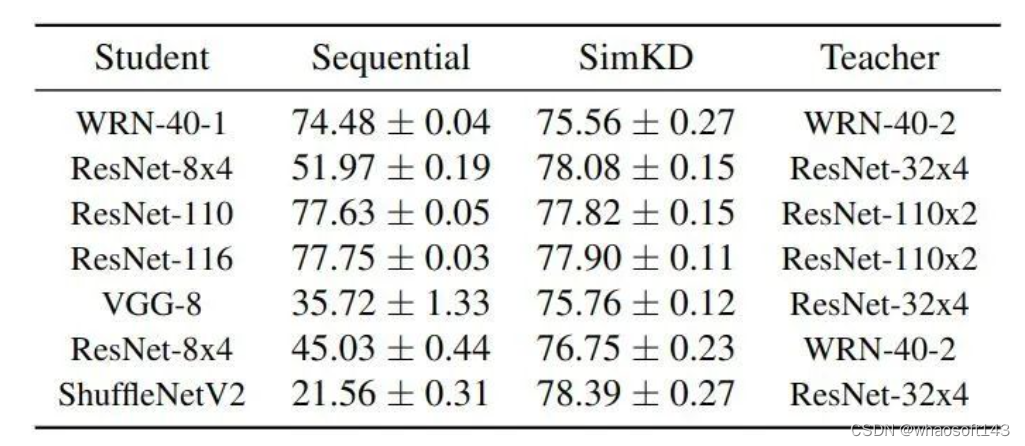 图9:顺序训练实验结果
图9:顺序训练实验结果
(3) 复用更多的层:以 ResNet 架构为例,除了复用最后的教师模型分类器之外,还复用最后一个 Building Block (SimKD+),和倒数第二个 Building Block (SimKD++)
实验结果如下图10所示。SimKD+ 和 SimKD++ 进一步提升了性能,但是复杂性也增加了。这些结果支持了 SimKD 的假设,即重用深层教师层有利于学生模型性能的提升,可能是因为其中包含了大多数特定能力的信息。另一种解释是,重用更深层的教师层将使浅层教师层的近似更容易实现,从而减少性能下降。在实践中,只重用最终的教师分类器可以很好地平衡性能和参数复杂性。

图10:复用更多的层实验结果
投影层分析
 图11:投影层消融实验结果
图11:投影层消融实验结果
总结

whaosoft aiot http://143ai.com




![[附源码]Python计算机毕业设计SSM基于框架的动漫设计(程序+LW)](https://img-blog.csdnimg.cn/3c74524bf23945229665a1a62aee5fb4.png)