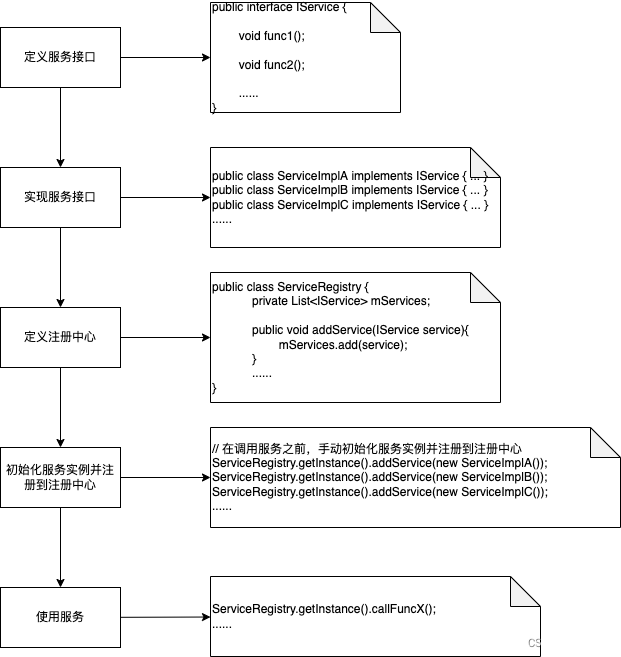
我们的日常开发中充满了Interface+Registry这种模式的代码,其中:
Interface为定义的服务接口,可能是业务功能服务也可能是日志服务、数据解析服务、特定功能引擎等各种抽象层(abstract layer);Registry为特定服务注册中心(或管理中心Manager),通常是一个单例形式用于管理对应的服务进行统一调度;
其常规开发流程如下:
这种常规模式存在两个可改进点:
-
服务的数量
在服务种类和实现的数量不多的情况下问题影响不大,但随着业务发展,会伴生越来越多的服务。极端地设想我们现在有50个服务,每个服务有10个实现类,意味着我们不进要需要对应的50个Registry类,还需要手动new出50×10个服务实例,并添加到注册中心。 -
注册中心与服务实现耦合
从上面开发流程可以看到,在调用服务之前有一个手动初始化服务实例和注册的过程,意味着注册中心是要显式引用每个服务实现类的,当服务实现类位于不同的module下时意味着要显式地依赖这些module,造成依赖复杂性增大和灵活性下降。
针对上述问题,一种更为解耦和可扩展的实现形式为:
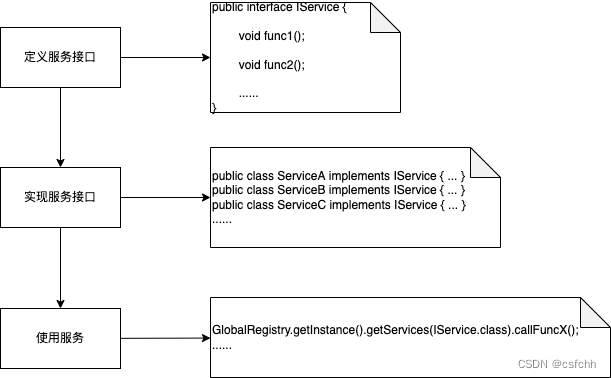
可以看到在这种模式下,针对第一个问题省去了手动初始化实例和注册的工作,针对第二个问题通过一个全局服务注册中心省去了创建特定服务注册中心的工作,此外最大的一个收益是解耦了接口与实现之间以及模块之间的依赖使我们可以从全局的视角去处理和调度服务。由此引申出了相关的实现技术。
技术方案
可以根据是否使用反射把这类技术分为有反射和无反射两大类(或动态和静态):
- 反射技术:通过某种方式获取对应服务的class对象,实例化并注册到全局注册中心。
- 优点:可动态加载
- 缺点:性能比静态差,混淆时需要添加keep规则
- 无反射技术:通过编译期修改代码的方式实例化服务并注册到全局注册中心。
- 优点:性能好
- 缺点:无法动态加载,编译隔离场景下引入额外的复杂度
反射技术
通过某种方式获取对应服务的class对象,然后初始化实例进行服务注册等相关操作。比较典型的如Java的SPI机制和Android上特有的dex遍历查找。
SPI机制
SPI(Service Provider Interface)是Java自带的一种服务发现机制,其核心类是ServiceLoader,使用也比较简单:
- 定义服务类,可以是接口或抽象类;
- 实现服务接口或抽象类;
- 在
META-INF/services下创建以服务类的完整类名为名的配置文件,文件需utf-8编码,内容为第2步中实现类的完整类名(每行一个); - 创建
ServiceLoader获取服务实例;
private static final Map<Class<?>, ServiceLoader<?>> sLoaders = new ConcurrentHashMap<>();
public static <T> List<T> getServiceBySPI(Class<T> clz){
List<T> services = new ArrayList<>();
ServiceLoader<T> loader = (ServiceLoader<T>) sLoaders.get(clz);
if (loader == null) {
loader = ServiceLoader.load(clz, clz.getClassLoader());
if (loader == null) {
throw new NullPointerException();
}
sLoaders.put(clz, loader);
}
for (T service : loader) {
Log.d(TAG, "getServiceBySPI: ==> " + service.getClass().getName());
services.add(service);
}
return Collections.unmodifiableList(services);
}
SPI的核心加载流程如下:

特点总结如下:
| 优点 | 缺点 |
|---|---|
| 1. 原生支持,使用简单; 2. 加载时间与包体大小没有线性正相关关系; 3. 支持模块化开发(jdk编译器会自动merge多模块配置文件); 4. 支持服务懒加载和provider缓存,在迭代器中实例化服务对象; | 1. 没有针对Android平台进行专门性能优化; 2. 使用了反射实例化,需要对服务接口及其实现类进行混淆keep; |
Dex扫描
在安卓中class被优化为dex文件以提高其在虚拟机中的执行效率,dex扫描顾名思义就是把应用中所有的dex文件都找到,然后加载这些dex并逐个遍历其中的文件找出符合条件的class文件。在使用流程与SPI也是大同小异:
- 定义服务类,可以是接口或抽象类;
- 实现服务接口或抽象类;
- 使用ClassUtils找到符合规则的class全类名;
- 初始化Class并实例化;
public static <T> List<T> getServiceByDex(Class<T> c){
List<T> services = new ArrayList<>();
try {
// 示例中使用报名作为全类名过滤条件,实际开发时可以灵活定制
for (String s : ClassUtils.getFileNameByPackageName(Utils.getApp(), c.getPackage().getName())) {
if (s.contains("$")) continue;
try {
Class<?> clz = Class.forName(s);
if (clz == c) continue;
if (!c.isAssignableFrom(clz)) continue;
Log.d(TAG, "getServiceByDex: ==> " + clz.getName());
services.add((T) clz.newInstance());
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InstantiationException e) {
e.printStackTrace();
}
}
} catch (PackageManager.NameNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
return Collections.unmodifiableList(services);
}
DEX扫描的核心加载流程如下:

特点总结如下:
| 优点 | 缺点 |
|---|---|
| 1. 动态特性,使用简单; | 1. 不支持Apply Changes等hot load技术,导致新增服务实现类时需要卸载重新安装apk才能被检测到; 2. 性能不如SPI,并且加载时间与包体增大而劣化; |
其他方案
从上面两个方案的对比中不难发现反射方案的核心和区别点在于服务实现类全名的搜集方式不同:
- SPI是借助resource资源文件和Java的resource相关API;
- DEX扫描则是采用运行期全局dex文件扫描的方式
两者的IO操作工作量相差巨大,我们不难推测基于SPI的方案性能要犹豫DEX扫描,而实验数据也可以进一步验证这个结论:
实验条件:
- 包体大小:apk:4.2MB,dex:3.7MB
- 服务1:该服务有3个实现,分别位于两个不同的module中
public interface IService {
String doJob();
}
- 服务2:该服务有2个实现,分别位于两个不同的module中
public abstract class AbsService {
protected abstract void doJob();
}
实验结果:
| 测试case | SPI | DEX扫描 |
|---|---|---|
| 加载3个服务耗时 | 3ms | 17ms |
| 加载2个服务耗时 | 1ms | 13ms |
实验数据显示,基于配置文件的SPI方案比基于运行期dex扫描的方案快了近一个数量级,可见服务列表的搜集方案对整体性能影响的占比是占了很大比例的。
有没有更好的搜集服务实现类的方法呢?这是一个开放性的问题,有一些比较典型的实践供我们参考:
apt经典案例之Glide
Glide作为谷歌官方维护的图片加载框架,除了其轻量级、功能多、性能强等优势外,一些代码设计的思想也非常值得我们借鉴。这里从服务发现的角度看看它是如何实现的。
Glide对用户提供了全局配置服务GlideModule,具体分为LibraryGlideModule和AppGlideModule,前者用于组件后者用于宿主。
- LibraryGlideModule示例
我们在library模块中创建如下的LibraryGlideModule:
@GlideModule
public class GModule1 extends LibraryGlideModule {
private static final String TAG = "GModule1";
@Override
public void registerComponents(@NonNull Context context, @NonNull Glide glide, @NonNull Registry registry) {
Log.d(TAG, "registerComponents: ");
}
}
然后make以下module,Glide的compiler将为我们生成如下的代码:
package com.bumptech.glide.annotation.compiler;
@Index(
modules = "<package_name>.GModule1"
)
public class GlideIndexer_GlideModule_<package_name>_GModule1 {
}
- AppGlideModule示例
我们在application模块中创建如下的AppGlideModule:
@GlideModule
public class GApp extends AppGlideModule {
private static final String TAG = "GApp";
@Override
public boolean isManifestParsingEnabled() {
return super.isManifestParsingEnabled();
}
@Override
public void applyOptions(@NonNull Context context, @NonNull GlideBuilder builder) {
super.applyOptions(context, builder);
Log.d(TAG, "applyOptions: ");
}
}
同样make以下module,Glide的compiler将为我们生成如下的代码:
out
├── com.bumptech.glide // 固定包名
│ ├── GeneratedAppGlideModuleImpl.java
│ └── GeneratedRequestManagerFactory.java
└── <package_name> // 用户包名
├── GlideApp.java
├── GlideOptions.java
├── GlideRequest.java
└── GlideRequests.java
文件比较多,我们主要关注GeneratedAppGlideModuleImpl.java:
package com.bumptech.glide;
@SuppressWarnings("deprecation")
final class GeneratedAppGlideModuleImpl extends GeneratedAppGlideModule {
private final GApp appGlideModule;
GeneratedAppGlideModuleImpl() {
// 获取到AppGlideModule服务实现类并实例化
appGlideModule = new GApp();
...
}
@Override
public void applyOptions(@NonNull Context context, @NonNull GlideBuilder builder) {
// 执行AppGlideModule实例的回调,使用户配置生效
appGlideModule.applyOptions(context, builder);
}
@Override
public void registerComponents(@NonNull Context context, @NonNull Glide glide,
@NonNull Registry registry) {
// 执行AppGlideModule实例的回调,使用户配置生效
// 注意:先执行library的回调再执行application的回调,把最终决定权交给宿主!!!
new GModule1().registerComponents(context, glide, registry);
appGlideModule.registerComponents(context, glide, registry);
}
@Override
public boolean isManifestParsingEnabled() {
return appGlideModule.isManifestParsingEnabled();
}
@Override
@NonNull
public Set<Class<?>> getExcludedModuleClasses() {
...
}
@Override
@NonNull
GeneratedRequestManagerFactory getRequestManagerFactory() {
...
}
}
那么Glide是如何解决上述代码的调用问题的呢?由于是配置服务,所以肯定是在Glide初始化时调用,找到对应的代码:
private static void initializeGlide(@NonNull Context context, @NonNull GlideBuilder builder) {
Context applicationContext = context.getApplicationContext();
// 实例化GeneratedAppGlideModule
GeneratedAppGlideModule annotationGeneratedModule = getAnnotationGeneratedGlideModules();
// 获取清单文件中的配置
List<com.bumptech.glide.module.GlideModule> manifestModules = Collections.emptyList();
if (annotationGeneratedModule == null || annotationGeneratedModule.isManifestParsingEnabled()) {
manifestModules = new ManifestParser(applicationContext).parse();
}
// 执行配置排除项
if (annotationGeneratedModule != null
&& !annotationGeneratedModule.getExcludedModuleClasses().isEmpty()) {
Set<Class<?>> excludedModuleClasses =
annotationGeneratedModule.getExcludedModuleClasses();
Iterator<com.bumptech.glide.module.GlideModule> iterator = manifestModules.iterator();
while (iterator.hasNext()) {
com.bumptech.glide.module.GlideModule current = iterator.next();
if (!excludedModuleClasses.contains(current.getClass())) {
continue;
}
if (Log.isLoggable(TAG, Log.DEBUG)) {
Log.d(TAG, "AppGlideModule excludes manifest GlideModule: " + current);
}
iterator.remove();
}
}
// 打印保留的清单文件配置
if (Log.isLoggable(TAG, Log.DEBUG)) {
for (com.bumptech.glide.module.GlideModule glideModule : manifestModules) {
Log.d(TAG, "Discovered GlideModule from manifest: " + glideModule.getClass());
}
}
// 执行其他配置回调
RequestManagerRetriever.RequestManagerFactory factory =
annotationGeneratedModule != null
? annotationGeneratedModule.getRequestManagerFactory() : null;
builder.setRequestManagerFactory(factory);
for (com.bumptech.glide.module.GlideModule module : manifestModules) {
module.applyOptions(applicationContext, builder);
}
if (annotationGeneratedModule != null) {
annotationGeneratedModule.applyOptions(applicationContext, builder);
}
Glide glide = builder.build(applicationContext);
for (com.bumptech.glide.module.GlideModule module : manifestModules) {
module.registerComponents(applicationContext, glide, glide.registry);
}
if (annotationGeneratedModule != null) {
annotationGeneratedModule.registerComponents(applicationContext, glide, glide.registry);
}
applicationContext.registerComponentCallbacks(glide);
Glide.glide = glide;
}
再看下GeneratedAppGlideModule是如何被实例化的:
private static GeneratedAppGlideModule getAnnotationGeneratedGlideModules() {
GeneratedAppGlideModule result = null;
try {
// 简单的反射即可,因为GeneratedAppGlideModuleImpl是固定包名的
Class<GeneratedAppGlideModule> clazz =
(Class<GeneratedAppGlideModule>)
Class.forName("com.bumptech.glide.GeneratedAppGlideModuleImpl");
result = clazz.getDeclaredConstructor().newInstance();
} catch (ClassNotFoundException e) {
if (Log.isLoggable(TAG, Log.WARN)) {
Log.w(TAG, "Failed to find GeneratedAppGlideModule. You should include an"
+ " annotationProcessor compile dependency on com.github.bumptech.glide:compiler"
+ " in your application and a @GlideModule annotated AppGlideModule implementation or"
+ " LibraryGlideModules will be silently ignored");
}
// These exceptions can't be squashed across all versions of Android.
} catch (InstantiationException e) {
throwIncorrectGlideModule(e);
} catch (IllegalAccessException e) {
throwIncorrectGlideModule(e);
} catch (NoSuchMethodException e) {
throwIncorrectGlideModule(e);
} catch (InvocationTargetException e) {
throwIncorrectGlideModule(e);
}
return result;
}
通过Glide的实现思路我们得到一些启发:
- 用annotation+apt做服务发现;
- 用固定包名(即协议)+反射做服务实例化,实现初始化;
由于服务发现是在编译期由apt实现的,只是用反射做了实例化的工作,严格上应该属于静态代码范畴,但这里是按是否使用反射进行分类。
无反射技术
通过编译期发现服务并生成服务初始化和注册的代码片段插入相关预留入口。
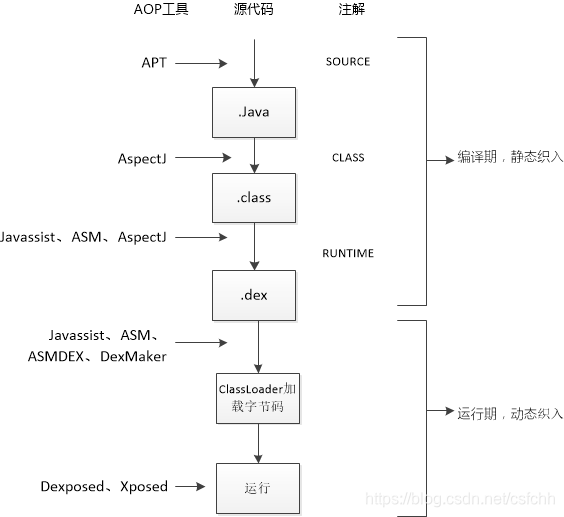
这些技术由于是在编译期生成了代码或修改代码,是静态的,相比动态实现方式具有天生的性能优势,同时也失去了动态的灵活性优势。适用于编译完成后服务的种类和数量都已确定的场景。
Annotation Processing
在Java生态中提供了apt工具可以帮助我们在运行期获取到源码相关元数据,从进行一些编译前预操作,比如常见的代码生成、配置文件生成等,通常的步骤为:
- 为每种特定目的定义annotation,用于在源码中打标记和提供参数;
- 自定义
AbstractProcessor来处理这些annotation标记执行对应的逻辑;
public class TestAnnotationProcessor extends AbstractProcessor {
@Override
public synchronized void init(ProcessingEnvironment processingEnv) {
super.init(processingEnv);
AptUtil.init(processingEnv);
AptUtil.log("Options = "+processingEnv.getOptions());
}
@Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
Set<TypeElement> typeElements = ElementFilter.typesIn(roundEnv.getElementsAnnotatedWith(Router.class));
if (typeElements.size()>0) {
// 生成代码或其他处理逻辑
}
return false;
}
@Override
public Set<String> getSupportedAnnotationTypes() {
return Collections.singleton(Router.class.getName());
}
@Override
public SourceVersion getSupportedSourceVersion() {
return SourceVersion.latestSupported();
}
}
- 在
META-INF/services下创建对应的配置文件以使AbstractProcessor可以被JDK识别; - 在gradle中使用
annotationProcessor等引入以使之生效;
通常APT都会配合一些代码生成工具使用,常见的如javapoet、kotlinpoet等。这个组合可以配合注解生成新的代码,但是不能修改已有的java代码,同时为了实现自动初始化等逻辑,还是需要根据生成代码的类名规则使用反射(如Glide的GlideModule)或者借助用户的手进行调用(如Glide的GlideApp、ButterKnife等)。
字节码插桩
字节码插装是指在javac生成class之后,转换成dex期间对class文件进行修改的一种时兴的技术。由于在这个阶段已经完成了编译的工作,已经不存在编译检查之类的环节,相比APT相关技术我们具有更高的修改自由度和广度,可以修改任何jar包中的文件。
目前比较主流的可实现字节码插装的技术分为两个流派:Aspectj和Transform。
Aspectj
通过hook gradle的javaCompile这个task,在编译完成后对class文件进行二次处理:
class AspectjPlugin implements Plugin<Project>{
@Override
void apply(Project project) {
project.dependencies {
api 'org.aspectj:aspectjrt:1.9.2'
}
def variants
try {
variants = project.android.libraryVariants
} catch (Exception ignore) {
variants = project.android.applicationVariants
}
variants.all { variant->
def javaCompile = variant.javaCompile
javaCompile.doLast{
String[] args = ["-showWeaveInfo",
"-1.8",
"-inpath", javaCompile.destinationDir.toString(),
"-aspectpath", javaCompile.classpath.asPath,
"-d", javaCompile.destinationDir.toString(),
"-classpath", javaCompile.classpath.asPath,
"-bootclasspath", project.android.bootClasspath.join(File.pathSeparator)]
project.logger.debug "ajc args: " + Arrays.toString(args)
MessageHandler handler = new MessageHandler(true);
new Main().run(args, handler);
}
}
}
}
在使用方便,基于AOP思想,分别定义切点和切面然后进行想要的修改即可。
Transform
Transform是Android Gradle V1.5.0 版本以后提供的API,用于在class文件被转化为dex文件之前去修改字节码以实现插桩需求。Transform最终会在AGP中被转化成对应的TransformTask,被TaskManager管理。
自定义Transform需要依赖implementation 'com.android.tools.build:gradle:1.5.0+'。
注册Transform:
class TestTransformPlugin implements Plugin<Project>{
@Override
void apply(Project project) {
project.android.registerTransform(new CustomTransform(project))
...
}
}
Transform的5个重写方法:
class TransformerTransform extends Transform {
private final Project mProject
TransformerTransform(Project project) {
mProject = project
}
@Override
String getName() {
/*
* 1. 会出现在 app/build/intermediates/transforms 目录下;
* 2. 在gradle tasks下面也能找到;
*/
return "${Your.Custom.Name}Transformer"
}
@Override
Set<QualifiedContent.ContentType> getInputTypes() {
/* 指定输入的类型:
通过这里设定,可以指定我们要处理的文件类型,这样确保其他类型的文件不会传入 */
/**
* {@link TransformManager#CONTENT_CLASS}:表示需要处理 java 的 class 文件
* {@link TransformManager#CONTENT_JARS}:表示需要处理 java 的 class 与 资源文件
* {@link TransformManager#CONTENT_RESOURCES}:表示需要处理 java 的资源文件
* {@link TransformManager#CONTENT_NATIVE_LIBS}:表示需要处理 native 库的代码。
* {@link TransformManager#CONTENT_DEX}:表示需要处理 DEX 文件。
* {@link TransformManager#CONTENT_DEX_WITH_RESOURCES}:表示需要处理 DEX 与 java 的资源文件。
* */
return TransformManager.CONTENT_CLASS
}
@Override
Set<? super QualifiedContent.Scope> getScopes() {
/* 指定Transfrom的作用范围: */
return TransformManager.SCOPE_FULL_PROJECT
}
@Override
boolean isIncremental() {
/*
如果返回 true,TransformInput 会包含一份修改的文件列表;
如果返回 false,则会进行全量编译,并且会删除上一次的输出内容;
*/
return false
}
@Override
void transform(TransformInvocation transformInvocation) throws TransformException, InterruptedException, IOException {
/* 必须要重写该方法,哪怕什么都不做,都需要把上一个transform的输入完整地传递给下一个transform,否则apk将会是空的 */
// Transform的inputs有两种类型:
// 1.directoryInputs:目录,源码以及R.class、BuildConfig.class以及R$XXX.class等
// 2.jarInputs:jar包,一般是第三方依赖库jar文件
...
}
}
重点是transform方法 ,在这个方法中去修改class文件注入我们的逻辑,通常有两种方式:Javassist和ASM,其中Javassist更接近java编码习惯,因此比较容易入门,ASM则比较复杂,需要了解相关的语法规则,可以借助类似Bytecode Outline这类插件辅助进行编码。
目前已经有一些现成的基于transform+ASM的服务发现方案,比如BlankJ的utilcode和字节内部的Claymore。
服务发现技术的应用
IDEA插件
插件框架赋予了IDE更多功能,使得三方开发者可以为IDE开发很多拓展功能,从而丰富应用生态。
这些插件位于:/Applications/Android Studio.app/Contents/plugins,那么IDE是如何知道这些插件并运行它们呢?其实每个插件都有自己的清单文件plugin.xml,其内容大致如下:
<idea-plugin>
<id>io.github.qzcsfchh.idea.plugin.demo</id>
<name>PluginDemo</name>
<version>1.0</version>
<vendor email="" url="">io.github.qzcsfchh</vendor>
<description><![CDATA[
My test Idea plugin, demonstrates how to create a plugin.<br>
<em>Test only.</em>
]]></description>
<change-notes><![CDATA[
Initial release of the plugin.
]]>
</change-notes>
<!-- please see https://plugins.jetbrains.com/docs/intellij/build-number-ranges.html for description -->
<idea-version since-build="173.0"/>
<!-- please see https://plugins.jetbrains.com/docs/intellij/plugin-compatibility.html
on how to target different products -->
<depends>com.intellij.modules.platform</depends>
<extensions defaultExtensionNs="com.intellij">
<!-- Add your extensions here -->
</extensions>
<actions>
<!-- Add your actions here -->
<!-- <group id="PluginDemo.MyGroup" text="MyGroup" description="Test my idea plugin">-->
<!-- <add-to-group group-id="MainMenu" anchor="last"/>-->
<!-- <action class="io.github.qzcsfchh.idea.plugin.demo.TextBoxed"-->
<!-- id="io.github.qzcsfchh.idea.plugin.demo.TextBoxed"-->
<!-- text="Input Dialog"-->
<!-- description="Show input dialog">-->
<!-- </action>-->
<!-- <action id="io.github.qzcsfchh.idea.plugin.demo.action.dialog.InputDialog"-->
<!-- class="io.github.qzcsfchh.idea.plugin.demo.action.dialog.InputDialog" text="InputDialog"-->
<!-- description="Show input dialog">-->
<!-- </action>-->
<!-- </group>-->
<action id="io.github.qzcsfchh.idea.plugin.demo.action.dialog.InputDialog"
class="io.github.qzcsfchh.idea.plugin.demo.action.dialog.InputDialog"
text="InputDialog"
description="Test input dialog">
<add-to-group group-id="ToolsMenu" anchor="last"/>
</action>
<action id="NotificationTest"
class="io.github.qzcsfchh.idea.plugin.demo.action.notification.NotificationTest"
text="NotificationTest"
description="Test notification">
<add-to-group group-id="ToolsMenu" anchor="last"/>
</action>
</actions>
</idea-plugin>
IDE只需要在启动时先扫描插件目录下的jar包,加载到classloader中,读取清单文件,最终在需要使用的时候进行反射实例化。
可执行jar包
jar包分为可执行和库文件两种,所谓可执行jar包是指可以通过java -jar xxx.jar来运行的jar包。那么Java如何区分这两种类型的jar包呢?同样还是清单文件,可执行jar需要在打包时在META-INF/MANIFEST.MF中指定Main-Class:
Manifest-Version: 1.0
Main-Class: com.github.thinwonton.jarstarter.JarStarterMain
Class-Path: ./lib/commons-lang3-3.5.jar
java程序在启动时加载指定的jar包到classloader,读取元清单文件Main-Class,反射实例化类对象并最终调用main方法。
扩展阅读
- 字节码技术在Android平台的应用